Hello RooExperts,
I’m struggling to estimate the expected median significance for a model [1] containing few nuisance parameters (that survive after some pruning procedure). The model is already Asimov and the pulls look reasonable [2]. The fit converges and the amount of signal looks sizable compared to background in many bins [3]. To estimate the significance I use the StandardHypoTestDemo.C code with the asymptotic calculator and the one-sided LHC test statistic. I use Minuit2 and the robust strategy 2 for the minimizer.
When setting
dataName = "asimovData"
noSystematics = 1
I obtain somehow desirable results [4]. When I switch to “obsData”, then I get a totally different response [5]. But more significantly, when I do set noSystematics = 0 I obtain NAN results [6]. In the latter case it seems that the fit is not converging (see log with verbosity level set at 3 [7]) in contrast to the converged fit I obtained with another program based on RooFit but with the same settings (strategy = 2, Minuit2).
My questions are:
-
It makes sense to use asimovData and poiValue > 0 for the expected significance calculation. Am I right?
-
I don’t understand why the StandardHypoTestDemo fails with noSystematics = 0. Is it safe anyway to set it always to noSystematics = 1 when computing the expected significance?
-
my model is already Asimov, i.e. data = bkg + signal. Shouldn’t StandardHypoTestDemo give me the same results if I set dataName to “asimovData” or “obsData”?
Thank you in advance for your help!
Best regards,
Zinonas
[1] RooWorkspace built with HistFactory: ~zenon/public/RooWorkspace.root on lxplus
[2] Pulls plot attached:
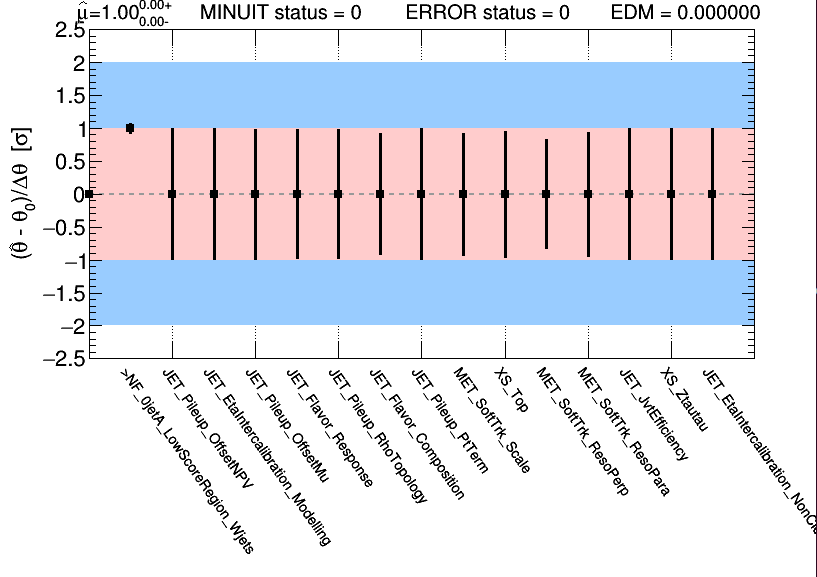
[3] Postfit distribution plot attached:
(the binning in the workspace is equidistant)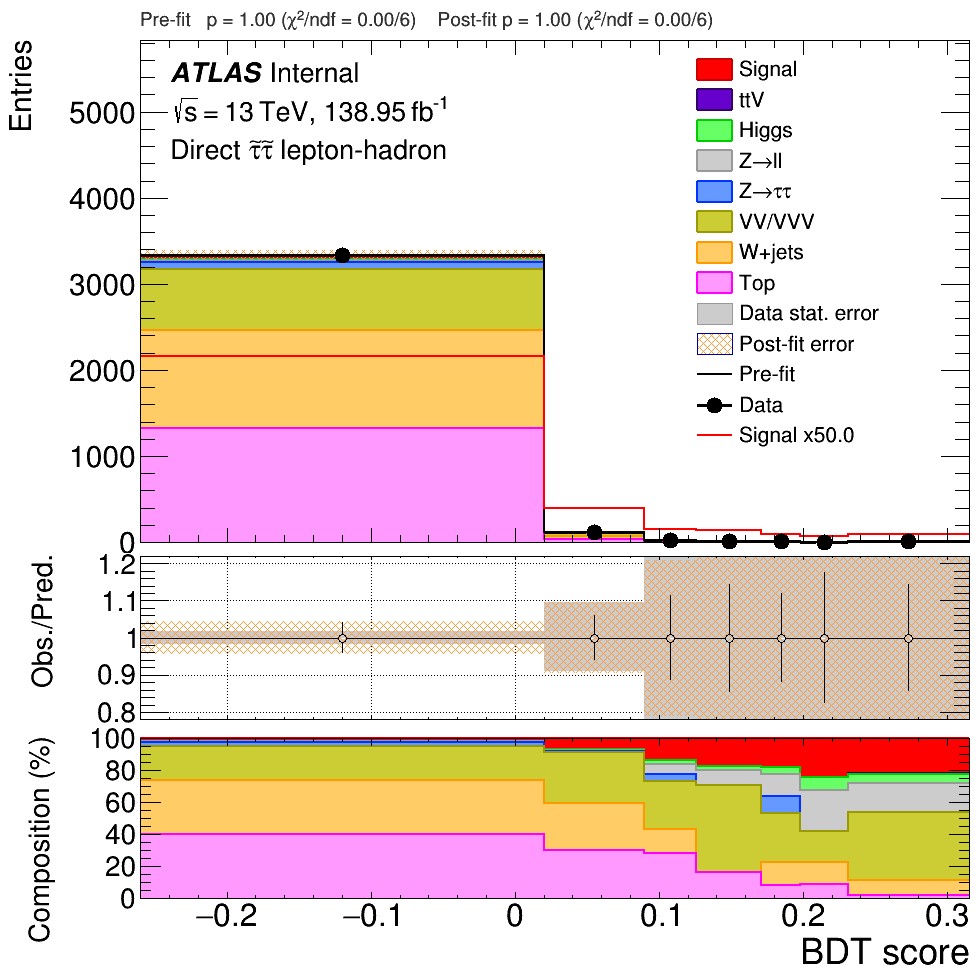
[4] Results HypoTestAsymptotic_result:
- Null p-value = 0.0330297
- Significance = 1.83802
- CL_b: 0.0330297
- CL_s+b: 0.5
- CL_s: 15.1379
Asymptotic results
Expected p -value and significance at -2 sigma = 0.564339 significance -0.161979 sigma
Expected p -value and significance at -1 sigma = 0.20101 significance 0.838021 sigma
Expected p -value and significance at 0 sigma = 0.0330297 significance 1.83802 sigma
Expected p -value and significance at 1 sigma = 0.00226971 significance 2.83802 sigma
Expected p -value and significance at 2 sigma = 6.2015e-05 significance 3.83802 sigma
[5] Results HypoTestAsymptotic_result:
- Null p-value = 0.5
- Significance = -0
- CL_b: 0.5
- CL_s+b: 0.96697
- CL_s: 1.93394
Asymptotic results
Expected p -value and significance at -2 sigma = 0.564339 significance -0.161979 sigma
Expected p -value and significance at -1 sigma = 0.20101 significance 0.838021 sigma
Expected p -value and significance at 0 sigma = 0.0330297 significance 1.83802 sigma
Expected p -value and significance at 1 sigma = 0.00226971 significance 2.83802 sigma
Expected p -value and significance at 2 sigma = 6.2015e-05 significance 3.83802 sigma
[6] Results :
- Null p-value = nan
- Significance = -nan
- CL_b: nan
- CL_s+b: nan
- CL_s: nan
Asymptotic results
Expected p -value and significance at -2 sigma = -nan significance nan sigma
Expected p -value and significance at -1 sigma = -nan significance nan sigma
Expected p -value and significance at 0 sigma = -nan significance nan sigma
Expected p -value and significance at 1 sigma = -nan significance nan sigma
Expected p -value and significance at 2 sigma = -nan significance nan sigma
[7] ~zenon/public/hypo.log on lxplus