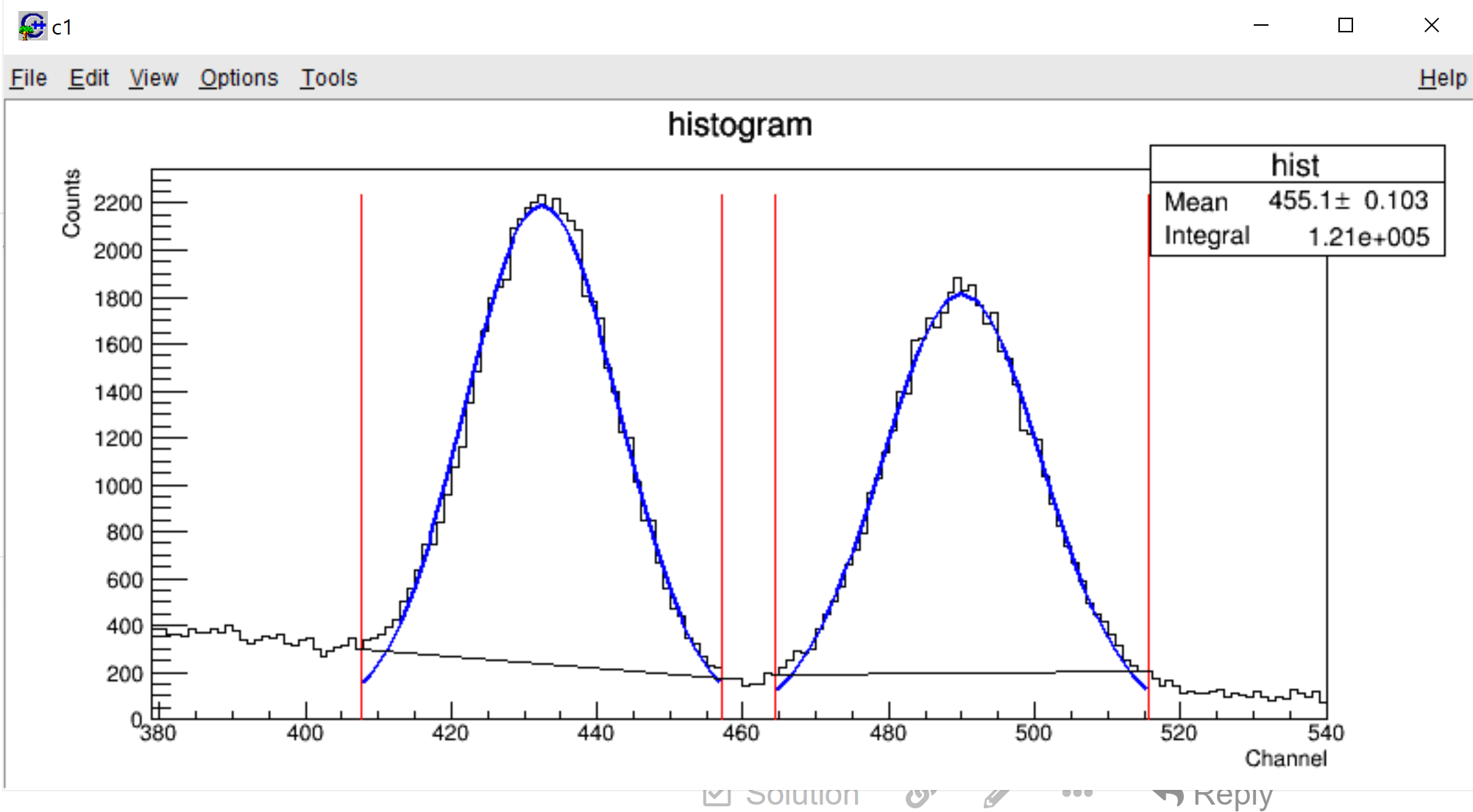
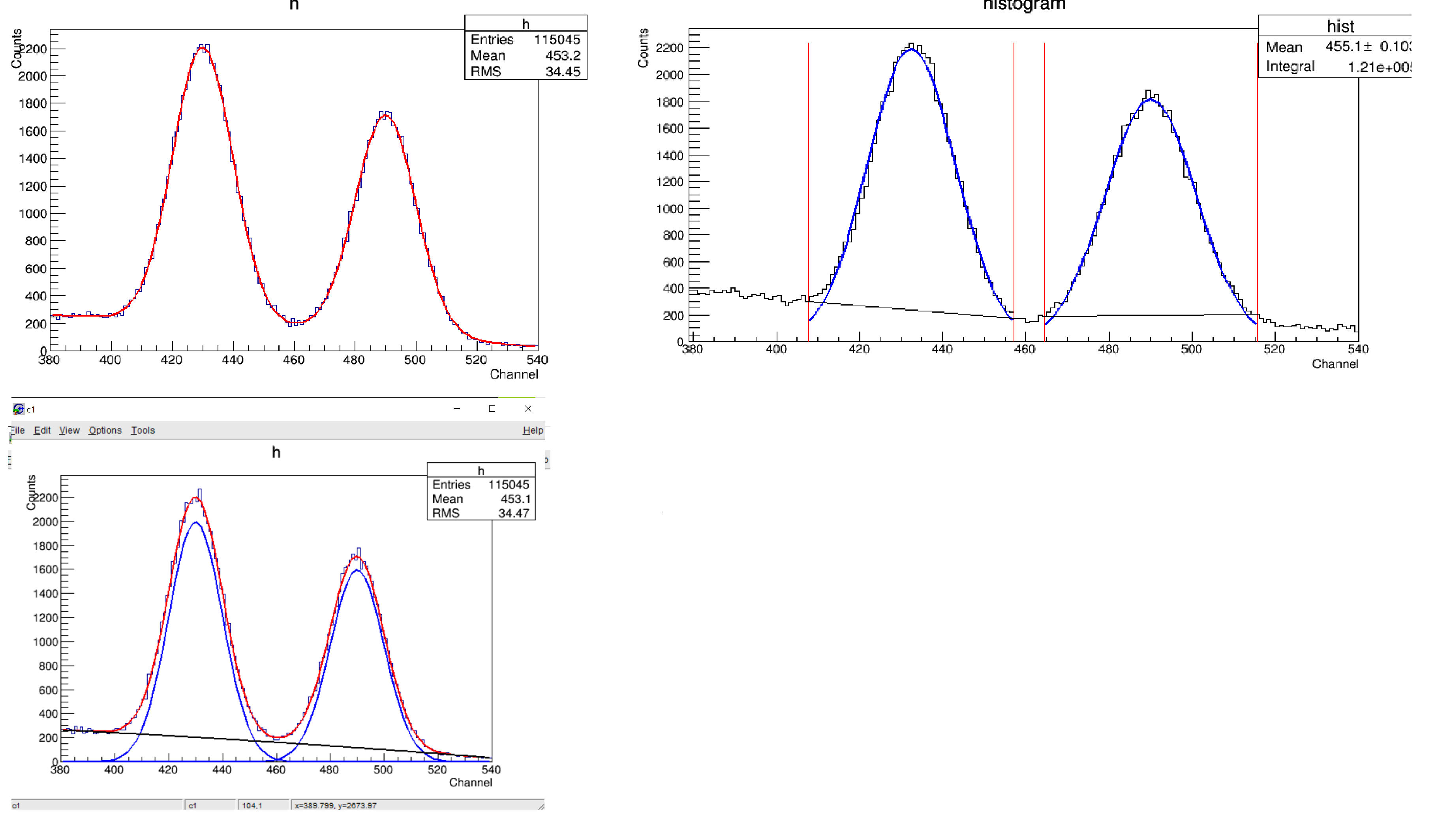
Play with a simple, dedicated simulation (a “toy MC”).
- The histogram is filled with each component separately (it is the preferred method, I guess):
{
Bool_t bg_pol2 = kFALSE; // simulate a "pol2" or a "broken line" background
// gRandom->SetSeed(0); // make it "really random"
// gStyle->SetOptFit(); // print fit parameters in the statistics box
ROOT::Math::MinimizerOptions::SetDefaultMinimizer("Minuit2");
Int_t n = 200; // number of bins
Double_t xl = 360., xr = xl + n; // make sure "bin width" = 1.
TF1 *bg;
if (bg_pol2) bg = new TF1("bg", "pol2", xl, xr); // pol2 background
else bg = new TF1("bg", "((x < [2]) * [1] * (x - [2])) + [0]", xl, xr); // "broken line" background
bg->SetParNames("a", "b", "c"); // any background
bg->SetLineColor(kBlack); bg->SetNpx(3 * n); // e.g., (n) or (3 * n);
TF1 *g1 = new TF1("g1", "gausn", xl, xr);
g1->SetParNames("Area_1", "Mean_1", "Sigma_1"); // gausn
g1->SetLineColor(kGreen); g1->SetNpx(bg->GetNpx());
TF1 *g2 = new TF1("g2", "gausn", xl, xr);
g2->SetParNames("Area_2", "Mean_2", "Sigma_2"); // gausn
g2->SetLineColor(kBlue); g2->SetNpx(bg->GetNpx());
if (bg_pol2) {
bg->SetParameters(450., 0.4, -0.002); // pol2 background
// bg->SetParameters(1150., -2., 0.); // pol2 background
} else {
bg->SetParameters(60., -4., 460.); // "broken line" background
}
g1->SetParameters(5.e4, 430., 10.); // gausn
g2->SetParameters(4.e4, 490., 10.); // gausn
delete gDirectory->FindObject("h"); // prevent "memory leak"
TH1D *h = new TH1D("h", "h;Channel;Counts", n, xl, xr);
h->FillRandom("bg", Int_t(bg->Integral(xl, xr) + 0.5)); // any background
h->FillRandom("g1", Int_t(g1->Integral(xl, xr) + 0.5)); // gausn
h->FillRandom("g2", Int_t(g2->Integral(xl, xr) + 0.5)); // gausn
TF1 *f = new TF1("f", "g1 + g2 + bg", xl, xr); // note: parameters are (re)ordered lexicographically
f->SetLineColor(kRed); f->SetNpx(bg->GetNpx());
// f->Print();
#if 1 /* 0 or 1 */
h->Fit(f, "L"); // e.g., "" or "L"
#else /* 0 or 1 */
h->Draw();
f->Draw("same");
#endif /* 0 or 1 */
bg->SetParameters(f->GetParameter("a"), f->GetParameter("b"), f->GetParameter("c")); // any background
g1->SetParameters(f->GetParameter("Area_1"), f->GetParameter("Mean_1"), f->GetParameter("Sigma_1")); // gausn
g2->SetParameters(f->GetParameter("Area_2"), f->GetParameter("Mean_2"), f->GetParameter("Sigma_2")); // gausn
bg->Draw("same");
g1->Draw("same");
g2->Draw("same");
}
- The histogram is filled with a sum of all components (individual components will be distributed more randomly):
{
Bool_t bg_pol2 = kFALSE; // simulate a "pol2" or a "broken line" background
// gRandom->SetSeed(0); // make it "really random"
// gStyle->SetOptFit(); // print fit parameters in the statistics box
ROOT::Math::MinimizerOptions::SetDefaultMinimizer("Minuit2");
Int_t n = 200; // number of bins
Double_t xl = 360., xr = xl + n; // make sure "bin width" = 1.
delete gDirectory->FindObject("h"); // prevent "memory leak"
TH1D *h = new TH1D("h", "h;Channel;Counts", n, xl, xr);
TF1 *f;
if (bg_pol2) {
f = new TF1("f", "gausn(0) + gausn(3) + pol2(6)", xl, xr);
f->SetParNames("Area_1", "Mean_1", "Sigma_1", // gausn(0)
"Area_2", "Mean_2", "Sigma_2", // gausn(3)
"a", "b", "c"); // pol2(6)
f->SetParameters(5.e4, 430., 10., // gausn(0)
4.e4, 490., 10., // gausn(3)
450., 0.4, -0.002); // pol2(6)
// 1150., -2., 0.); // pol2(6)
} else {
f = new TF1("f", "gausn(0) + gausn(3) + ((x < [8]) * [7] * (x - [8])) + [6]", xl, xr);
f->SetParNames("Area_1", "Mean_1", "Sigma_1", // gausn(0)
"Area_2", "Mean_2", "Sigma_2", // gausn(3)
"a", "b", "c"); // "broken line" background (6)
f->SetParameters(5.e4, 430., 10., // gausn(0)
4.e4, 490., 10., // gausn(3)
60., -4., 460.); // "broken line" background (6)
}
f->SetLineColor(kRed); f->SetNpx(3 * n); // e.g., (n) or (3 * n);
// f->Print();
h->FillRandom("f", Int_t(f->Integral(xl, xr) + 0.5));
#if 1 /* 0 or 1 */
h->Fit(f, "L"); // e.g., "" or "L"
#else /* 0 or 1 */
h->Draw();
f->Draw("same");
#endif /* 0 or 1 */
TF1 *g1 = new TF1("g1", "gausn", xl, xr);
g1->SetParNames(f->GetParName(0), f->GetParName(1), f->GetParName(2));
g1->SetParameters(f->GetParameters() + 0); // gausn(0)
g1->SetLineColor(kGreen); g1->SetNpx(f->GetNpx());
TF1 *g2 = new TF1("g2", "gausn", xl, xr);
g2->SetParNames(f->GetParName(3), f->GetParName(4), f->GetParName(5));
g2->SetParameters(f->GetParameters() + 3); // gausn(3)
g2->SetLineColor(kBlue); g2->SetNpx(f->GetNpx());
TF1 *bg;
if (bg_pol2) bg = new TF1("bg", "pol2", xl, xr);
else bg = new TF1("bg", "((x < [2]) * [1] * (x - [2])) + [0]", xl, xr);
bg->SetParNames(f->GetParName(6), f->GetParName(7), f->GetParName(8));
bg->SetParameters(f->GetParameters() + 6); // any background (6)
bg->SetLineColor(kBlack); bg->SetNpx(f->GetNpx());
bg->Draw("same");
g1->Draw("same");
g2->Draw("same");
}