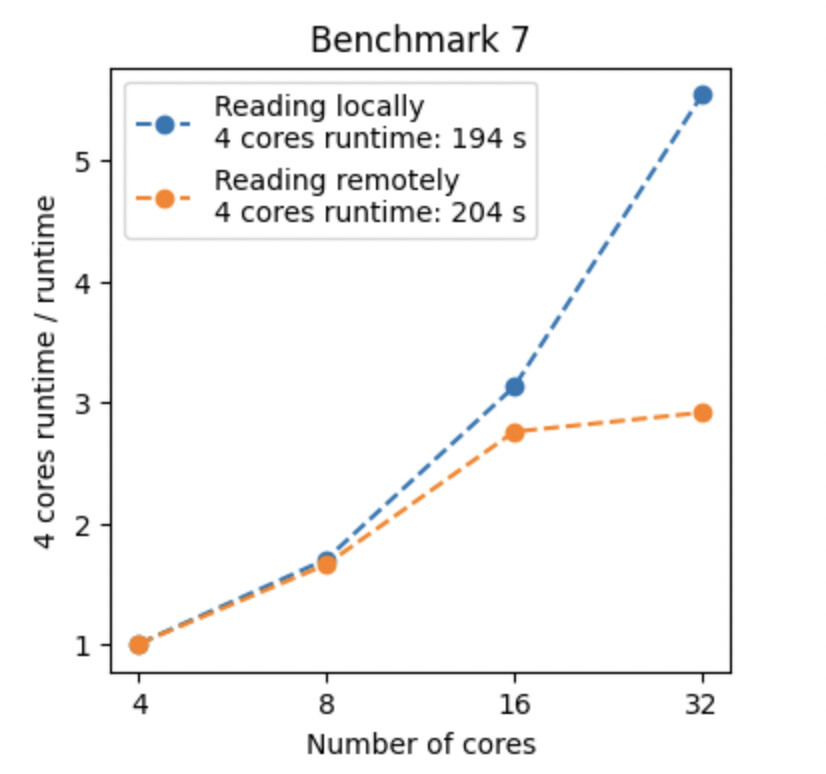
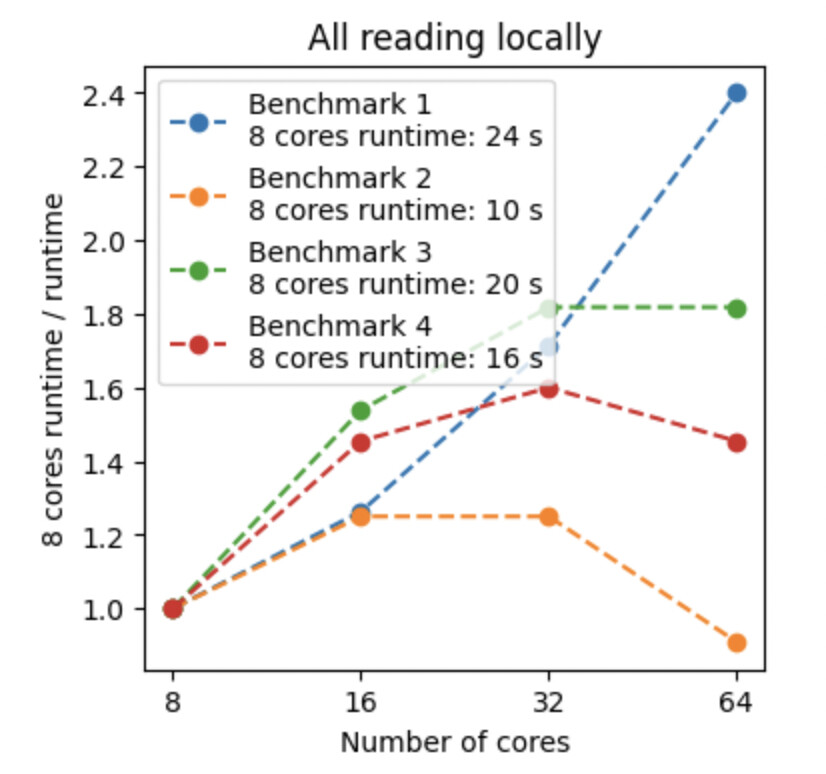
I am currently running some performance tests of the ROOT framework using this benchmark and I am encountering unexpected behavior: I have run the queries of the benchmark using various instances sizes on EC2 (all m5d instance sizes, to be precise), which have between 2 and 48 physical cores, and observed that the running time only improves until 8 to 16 cores and gets significantly worse after that (see plot.pdf (378.7 KB)) With some queries, using 48 cores is slower than using just 2 cores.
Is this a known behavior, and if yes, is there an easy fix?
You should be able to fully reproduce what I did the following way: I am using the Docker image from
Docker Hub and GitHub - masonproffitt/opendata-benchmarks: Example repository showing benchmarks with open data. I use the Docker image like so:
docker run --rm \
-v /path/to/benchmark/data/:/data/:ro \
masonproffitt/rdataframe-benchmarks:0.0 \
/root/util/run_benchmark.sh \
-n 3 \
$query_id \
"/data/Run2012B_SingleMu.root" \
true
This assumes that you have downloaded the benchmark data from root://eospublic.cern.ch//eos/root-eos/benchmark/Run2012B_SingleMu.root to /path/to/benchmark/data/ (which should also work on EC2 in case you want to use the same hardware as I did).
ROOT Version: 6.22.08 (via official Docker image rootproject/root:6.22.08-ubuntu20.04)
 Jitting and too many allocations (due to missing small buffer optimization in RVec) may be an issue. But fair enough, we should also scale with the nicely readable code!
Jitting and too many allocations (due to missing small buffer optimization in RVec) may be an issue. But fair enough, we should also scale with the nicely readable code!