Does fitting in root have an option to set boundary conditions on a fit? I know you can fix a parameter, but in my specific case, that would not work. Just to use a simple example, lets say I know my data will be y = 100 at x = 10 and want the fit to consider that. If my fit equation is y = ax + b then there are multiple different parameter values of a and b for which at x = 10, y = 100. Does root have a way to set a boundary condition like this?
“Fitting” a single point with a line y = ax +b has, as you said, an infinite number of possible values for a and b. You’ll need at leat a 2nd point. Is it what you call “boundary conditions”?
No sorry, I realize now my phrasing in my original post was bad.
By “my data” I meant a large amount of data points that I expect to be modeled as y = ax + b, but I also know it to be y = 100 at x = 10. Basically I want to tell my fit, “Your parameters of a and b are still free, but no mater what you end up fitting you MUST have them such that at x = 10, y = 100”.
Ah ok, That’s more clear. I am sure @moneta knows the answer.
So, you just have one “free parameter”, e.g.: “y = a * (x - 10) + 100” or “y = (100 - b) * x / 10 + b”
I was using y = ax + b as an example. Unfortunately the equations I am dealing with are not linear but are exponential. I’ll give a brief overview of what I’m trying to do but in my case I don’t think I can mathematically apply the boundary condition I want and reduce my equations by one parameter.
TDLR: The only way to do what I want is by telling the fit it need to be a certain value at a certain x and I can’t change the equation to represent that as you have showed.
I am fitting radioactive decays so I am using the Bateman equation. I’ll use the most simple case the Bateman equation which is just an exponential decay, A(t) = A0 * e ^ (-lambda * T) (1) where A(t) is activity, A0 is initial activity, and lambda is a decay constant. I simulate a radioactive decay and end up getting a histogram mathematically represented by equation 1. Lets say I end up getting a histogram where the sum of all the bins is N0 (or N0 radioactive decay happened). My next step is to make a cumulative sum histogram (CSH) from the original histogram (the value of bin N in the CSH is the sum of bin 1 to N of the original histogram). I then fit the CSH with a integral of equation 1 or I(t) = N0 * (1 - e ^ (-lambda * T)) (No +c because I need I(0) = 0). I know in my CSH the value of the last bin must be the sum of all the bins of the original histogram. Thus, if my fit does not reflect this, it is wrong. Unfortunately, attempting to solve I(t) in the fashion above doesn’t work. Thus, I was wondering if there was any way I could tell the fit it need to end up at N0 at time T0.
Hi,
In general you should be able to write your fitting function in a way that satisfies your constraint, If it is not possible to write the function that satisfies teh constraint exactly you can always add a constraint to your likelihood or least-square function.
For example if you want that your fitting function has in the last bin the value N0, you can set a very small error in the last bin to have this constraint satisfied.
Lorenzo
Oh I see. Setting a very low (or 0) error on the last bin would do exactly what I want. Thank you.
Do NOT set the error to zero (standard chi2 fits will ignore such bins).
I’ve been thinking that you might somehow scale the histogram first and then fit the “shape” of such a “normalized” distribution only.
I am using log-liklihood for fitting so I think it should be fine (not 100% on this). Also, I don’t see how fitting the “shape” of the histogram accomplish the goal I am after.
On second thought, it seems to me that your “cumulative sum histogram” will have highly correlated bin errors (and contents). I don’t think any standard ROOT fitting routine can take it into account (you’d better fit the “original histogram”, where bins are “uncorrelated”).
This is true but it turns out, if the bin error is assigned as sqrt(N) where N is the height of the bin, the error is properly accounted for in the cumulative sum histogram.
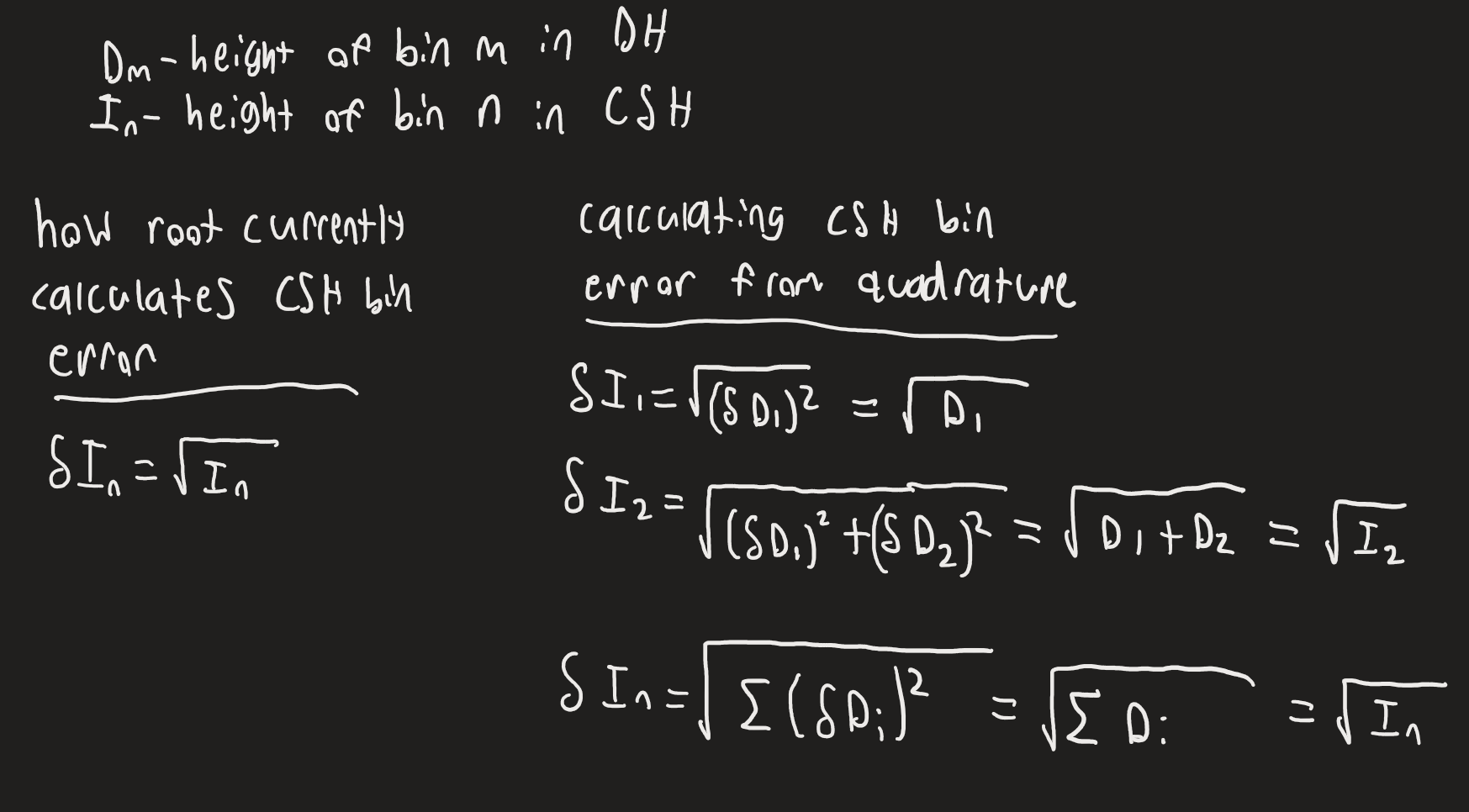
Here you can see the math if we were to propagate the error from quadrature is the same as what root is already doing.
DH(Decay histogram) is the original histogram
CSH(cumulative sum histogram)
It’s not about errors of individual bins but about their correlations.
I guess @moneta could comment on it.