I’m seeing a number of differences when fitting a 1D RooDataHist (imported from a TH1F) with an explicitly specified range versus no range given in the fitTo(…) function. The fitTo call uses custom errors (non-sqrt(n) or poisson), otherwise I use all typical default options. This appears true even when the range given matches the minimum/maximum bins AND the RooRealVar corresponding to the 1D histogram variable is given the same minimum and maximum values. I’ve also played around with changing the RooRealVar range to exclude the lowest bin and highest bin; this doesn’t appear to explain the differences seen.
Apart from arriving at slightly different results, specifying the range when fitting takes something like 30 times longer, which is my real concern.
Does fitting with an explicit range change some options under the hood that might explain this difference in performance?
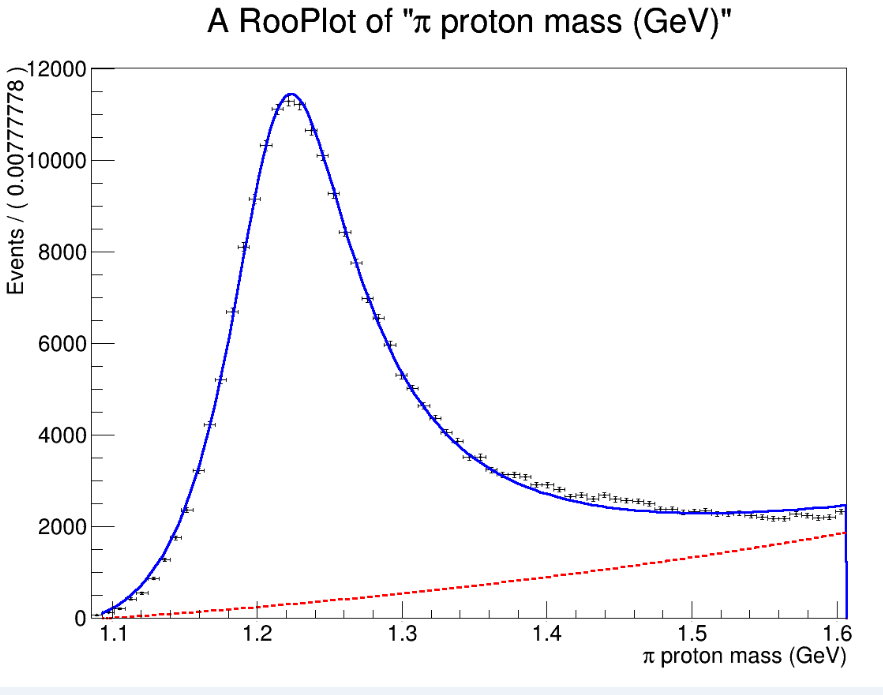
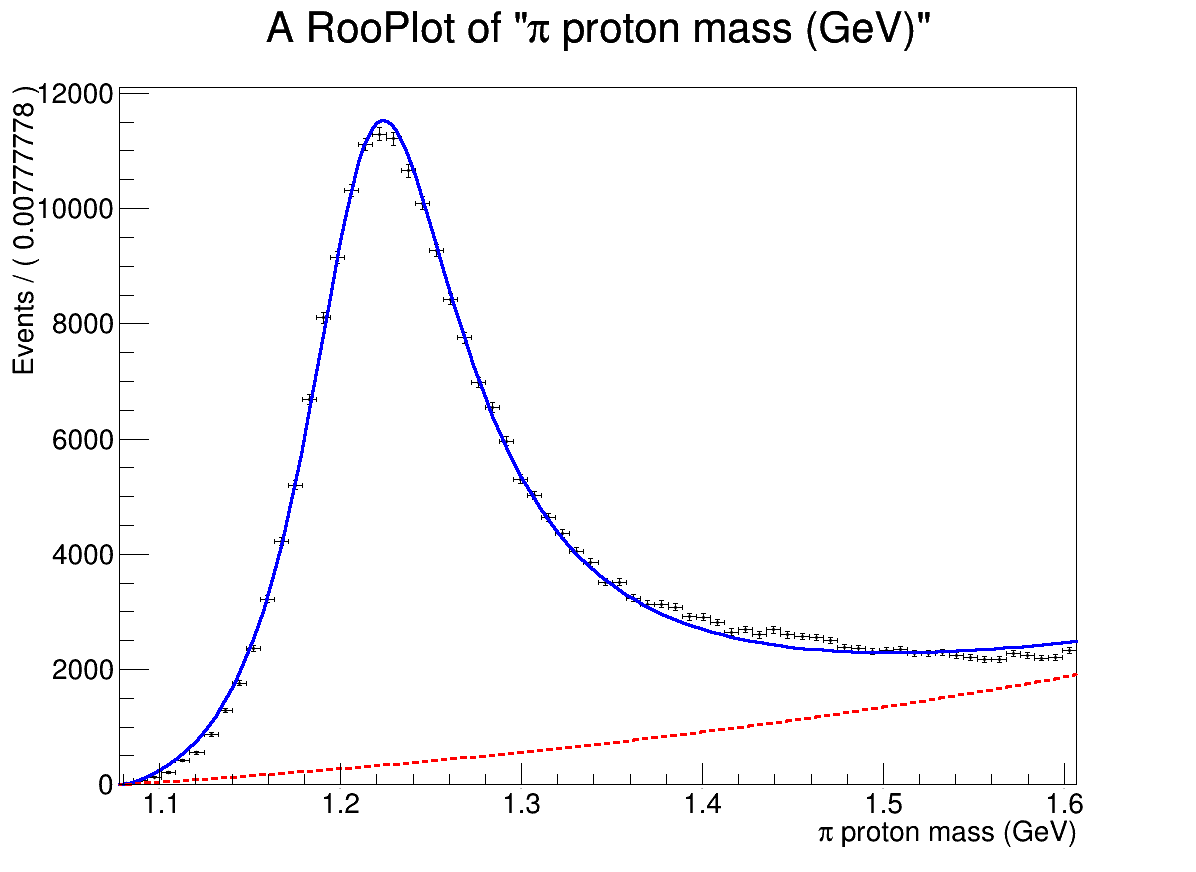
Here are some histograms and fit results for concreteness. I fit with a signal shape (non-simple Breit-Wigner) and polynomial background. I suspect the issue may be related to the fit having trouble keeping the background pdf positive, however the behavior remains even when fitting far from the left threshhold.
Sure thing. Here’s the script I use to fit and save with flag “use_explicit_range” at the start to toggle whether the range should be given in the fitTo(…) call or not. The root file with the necessary histogram and a custom PDF used in the fit are also included.
Hence the fit appears to be the same in both cases, and gives me a fitted yield of N_sig = 215462 ± 499.019 for both cases. Yet for some reason when I specify the range the fitting takes much longer (I’ll need to perform 1000s of fits, so a factor of 5 would be quite a big deal for me)
The range is not exactly the same, because it is adjusted when creating the RooDataHist
INFO:DataHandling – RooDataHist::adjustBinning(my_RooHist): fit range of variable mass expanded to nearest bin boundaries: [1.08167,1.60667] → [1.07778,1.60667]
Therefore the two fits are not exactly the same. Since your fit does not converge, it is full of error, it is very unstable, so you can get completely different paths and different timings.
I would use a better Polynomial representation, such as the Bernstein polynomial which are positive defined and let you avoid all these errors