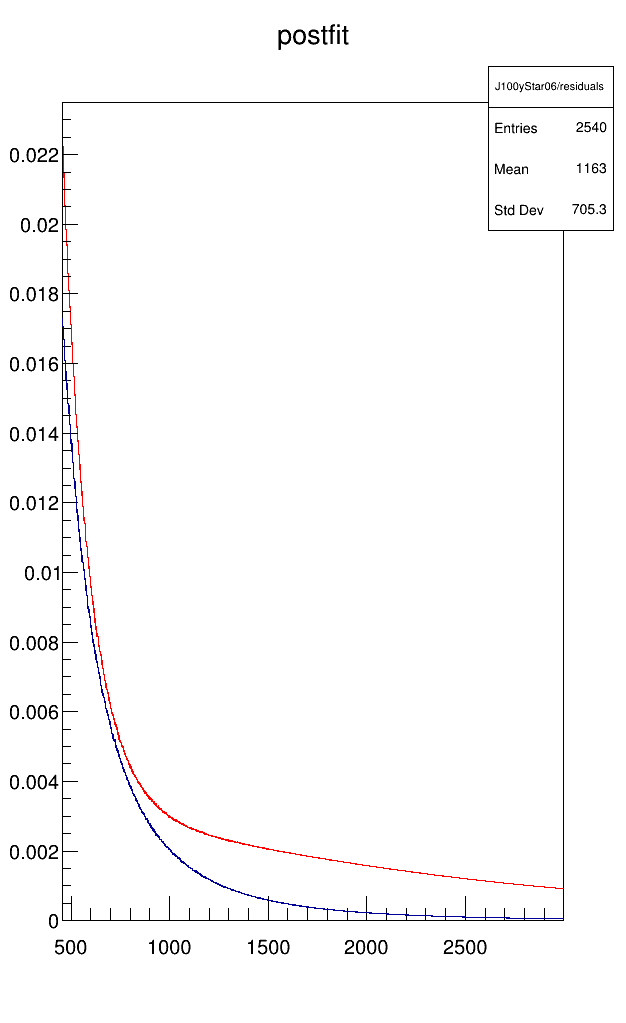
We have run into an issue of inaccuracies with the NLL minimum not corresponding to the best fit.
We are building a RooWorkspace using xmlAnaWSBuilder where we have a 5-parameter function fitting a histogram (10^9 entries, 2500 bins) that was generated by exactly this function, unfluctuated. We then perform the fit using quickFit, setting the initial parameters to the values that yield the optimal fit and if we fix them, a chi2 of (almost) 0 comes out. If we allow the fit parameters to float, the minimization of the NLL yields new fit parameters which indeed correspond to a lower NLL but offer a worse fit.
Our assumption is that we run into the limit of numerical accuracy of the NLL since the relative NLL difference between the best fit and true minimum is in the order of 10^-10. We have found that disabling the NLL offset in RooAbsPdf::createNLL() and switching the integrator via RooAbsReal::defaultIntegratorConfig()->method1D().setLabel("RooAdaptiveGaussKronrodIntegrator1D") improve the result, but still a difference remains.
Are there any other improvements that we can apply to get a better fit? I am attaching a plot of the residuals with the different settings in the fit and a tarball containing the workspace and a README with the commands used to build the workspace and fit it. We tested this both in ROOT 6.20 and 6.24.
Thanks for the detailed post, I was able to reproduce the fit.
I also ran it with the ROOT master branch so see if the problem has maybe solved itself in the meantime, and indeed the agreement is much better (fixed parameters in blue and floating parameters in red).
I think with ROOT 6.26, you would also get the same result because the differences between 6.26 and master are small.
The reason for the fit being better is that the RooFit batchmode was completely re-implemented and the new implementation is seemingly less sensitive to floating point errors.
Is there a reason why you can’t use ROOT 6.26 for this fit?
Anyway the agreement is still not perfect, probably because of some remaining floating point related errors. It’s better to investigate even further to see how we can get perfect agreement, right?
Thanks for your investigation! Did you use quickFit to perform the fit or somehting else?
I recompiled quickFit after lsetup "views LCG_102rc1_ATLAS_14 x86_64-centos7-gcc11-opt" which comes with Root 6.26/00 and RooFit 3.60. It throws a couple of warnings that RooMinuit has been replaced by RooMinimizer now, but it compiles. If I now set --useBatch 1 for quickFit, which adds BatchMode(1) to RooAbsPdf.createNLL(), the results change.
One additional parameter shows up as info from Minuit2 (the first one):
Info in <Minuit2>: MnSeedGenerator Negative G2 found - new state:
Minimum value : -2.173421348e+10
Edm : 121266.6657
Internal parameters:
1.542734729
0.5235987756
0.0316276393
0.3459600492
0.1197389193
0.08797523891
Internal gradient :
0
-11152990.55
1108.107355
59610.54466
-150652.755
76293.44441
and the fit seems to abort with
MnHesse 2nd derivative zero for parameter _J100yStar06_obs_x_channel ; MnHesse fails and will return diagonal matrix
Hi! I will try the comparison later today myself to confirm that this is the problem, but I think the fit might be affected by a bug that got fixed the upcoming 6.26.04 patch release. Sorry for the delay in this investigation.
in the meanwhile note that if @jonas is right you can test whether 6.26.04 fixes the problem by updating to the latest version or by trying it out in a conda environment, a docker container or similar. See also Installing ROOT - ROOT .
I Have produced the results with quickFit, using my custom branch that compiles with ROOT master. It is based on the ROOT_v6.24_06 in the official quickFit repo. Then I just followed the instructions from the README in your tarball, executing the quickfit command once of the floating parameter input file and once for the fixed input file.
The problem with the spurious parameter in the BatchMode that you observed was fixed recently in this commit. It was backported to 6.26.06, so if you use the most recent 6.26 patch release it should be all good.
I didn’t see a --useBatch 1 branch for quickFit though, do you use a different quickfit branch? In my branch based on the ROOT_v6.24_06 branch, the BatchMode(true) option is hardcoded in the createNLL call. So my results are indeed using the BatchMode and look fine, as far as I can tell.
I hope this helps you to continue your investigation, let me know if you need further help!
Thanks for the details! In your custom branch, do you use the setup_lxplus.sh that sources /afs/cern.ch/user/a/asciandr/public/ROOT_v6.24_06/build/bin/thisroot.sh (which does not exist anymore)? Or do you instead build the latest ROOT master and source that?
I’m using the development branch of the original quickFit repo, I think you are using a fork from that. There, the --useBatch 1 can be used to set BatchMode(true) which otherwise defaults to false.
I used now the development branch of quickFit; my ROOT_master branch is now based on that. Indeed I can reproduce your results from your initial post now:
Both times I use the same build of ROOT master. So there was something going on in the recent quickFit develompent that made the fit converge slightly worse. The fir results are very similar however. Here with the branch based on development:
Both times I used the BatchMode. Since the fit parameter results are so similar, could quickFit have changed the way the residuals are computed?
Maybe it’s better to keep quickfit out of the equation when investigating this model? You said you have some code to do this fit standalone, maybe you can share that if there are some further checks I can help with?
About the ROOT version I use: yes, I use ROOT master that I built myself, but you can also source it from the nightly builds.
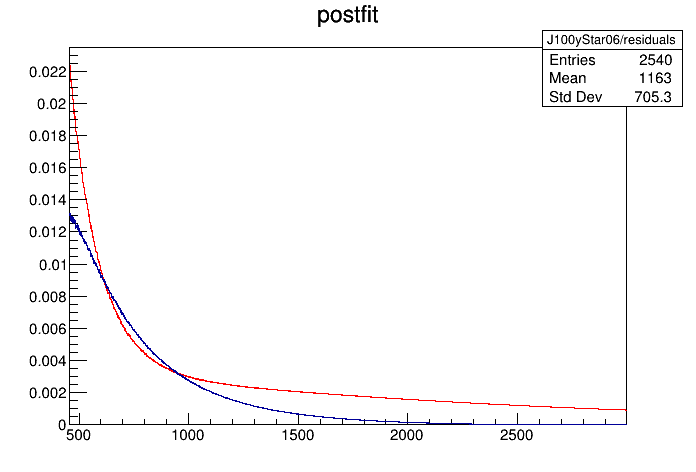
Right, with the latest ROOT master the BatchMode issue is gone. The relevant difference between the two quickFit repositories seems to be that in the atlas-phys-exotics-dijetisr one there is a default value set for _samplingRelTol so by default bins are integrated while in the standard quickFit they are not.
I can reproduce both repositories behaviour by setting --samplingRelTol 1e-3 (blue) or --samplingRelTol -1 (disabled, red):
The result can be plotted with the ExtractPostfitFromWS.py as well. It seems to perfectly reproduce the red fit from above. Unfortunately I do not manage to get it succeed with IntegrateBins enabled.
I didn’t manage to perform further tests yet, but I suspect using the integration does not in general produce more accurate results and this might just be random chance. I did check however that this behaviour seems to be driven by the highest-statistics bins at the low end of the spectrum. Restricting the fit to e.g. 10 bins there yields even stronger deviations than in the full range.
I have been investigating this issue in parallel. I suspect there is a real machine accuracy issue with the size of the statistics and the definition of the ML. With the FCN being on the order of 2e10 this is getting very large.
I have been running a simple Minuit fit and reproduce the problem outside of RooFit using a NLL definition of the usual extended type
Sum (expected - observed log(expected)).
If I replace this with a more sophisticated NLL then I get good convergence and a FCN that is approximately equal to the number of degrees of freedom which is much more numerically stable:
Sum (expected - observed + observed ( log(observed) - log(expected))
I have been trying to work out where I can modify this in RooFit but the code is too complex for me to figure out where the likelihood is defined.
interesting observation, thanks for reporting this!
So you’re saying that dropping the constant terms in the likelihood makes the fit not converge anymore?
If it’s an accuracy issue, you can also try out the Offset() option mentioned in the RooAbsPdf::createNLL or RooAbsPdf::fitTo methods. It subtracts the initial likelihood value from all subsequent likelihood evaluations, making the likelihood values closer to zero and hence more numerically stable.
By the way, it is not good that 6.26 broke your code. If this is not related to some intended deprecation, this could be a bug. If you have time, please feel free to open a new forum post about this, or even a GitHub issue if you think it’s a bug!
I will attempt again using the OffSet() option but have not had much success with its previously as it depends on the initial values of the fit parameters.
My experience with fitting large statistics binned data is that it really does require using a NLL that contains the constants.
I will re download the latest root and test with my code. Old RooFit based programs had failed previously and I will check that behaviour.
I had tried the Offset() option before as well. And even with optimal starting parameters it rather made the fit worse instead of better (see light blue vs green or yellow vs red curve in the very first post of this thread.
I had more time to digest your answers now, and I think I understand now what is going on. The key is Iains definiton of the likelihood above:
Sum (expected - observed + observed ( log(observed) - log(expected))
Basically, instead of calculating the NLL, which can grow really large and unstable, he evaluates the likelihood ratio compared to a template PDF created from the dataset. This ratio is much closer to zero. And by taking the ratio for every bin before summing it, you have a value close to zero for each bin and avoid numerical instabilities in the sum because you might combine bins with a vastly different number of events. This is probably exactly what happens in @fbartels fit, because it’s an exponentially decaying distribution.
Now I also understand why the “Offset” feature doesn’t help, because the offset is applied only after summing over the bins.
This trick needs to be implemented in the RooFit likelihood classes I think. It makes huge sense! I would certainly like to have in the next ROOT release. Maybe we could have a new option for createNLL, called RatioWithTemplate (or TemplateRatio or something less cryptic), that enables this likelihood definition. We can’t make it the default because the different absolute NLL values can catch users by surprise. I would implement it, commit it to ROOT master, and then you can try it out, either by sourcing the nighlies from CVMFS or building yourself. For the next ROOT release that is due in January, this new feature would be included.
I am afraid I cannot recall the source of the likelihood (other than it may have been developed due to lower precision computations pre 32/64 bit machines).