Hi
I have to convert huge csv file to root file
I am trying to use the RDF to do this conversion
But the program never end and only an empty root file is created
below my code
include "Riostream.h"
#include "TString.h"
#include "TFile.h"
#include "TTree.h"
#include "TCanvas.h"
#include "/soft/root/6.22.08/include/ROOT/RDataFrame.hxx"
#include "/soft/root/6.22.08/include/ROOT/RCsvDS.hxx"
#include "TSystem.h"
int CSV_to_root_viaRDF()
{
ROOT::EnableImplicitMT();
// Let's first create a RDF that will read from the CSV file.
auto df = ROOT::RDF::MakeCsvDataFrame("Data_CH6@DT5730S_10548_Ron35.csv");
cout << "apres make"<<endl;
df.Snapshot("myTree", "myFile2.root");
cout << "apres Snapshot"<<endl;
return 0;
}
Hi @Thibaut_VINCHON ,
please see Posting code? Read this first! for some tips regarding code formatting on the forum.
The first thing I would suggest is to try with a more recent ROOT version, possibly v6.26.02. You can run it from a docker container, or from an LCG release, or install it as a conda/snap/homebrew package, see Installing ROOT - ROOT .
If the problem is still present in a recent ROOT version, please share the CSV file with us so that we can take a look.
Cheers,
Enrico
Hi Enrico
Thank you for your help
A IRSN, the latest version of root is 6.22.08
I am trying now to do a test with a smaller file to see the behavior of the program
the content of this csv file is below
BOARD:CANAL:TIMETAG:ENERGY:ENERGY_SHORT:FLAG
0;2;193700111870948;395;255;0x4000
0;2;193700443142777;512;437;0x4000
0;2;193700834489222;1879;1562;0x4000
0;2;193700908930306;676;587;0x4000
0;2;193701112366768;968;690;0x4000
0;2;193701613869011;545;366;0x4000
0;2;193701795834206;2268;1941;0x4000
0;2;193702006826005;178;158;0x4000
Yes I imagined, that’s why I suggested docker or similar to quickly try a newer version out, e.g. on your personal workstation or laptop. RDataFrame has evolved a lot since v6.22.
I can run your macro on your example CSV and it takes 2-3 seconds on my laptop (but most of it is startup and interpreter time, the actual RDF event loop is 0.03s for that file).
Cheers,
Enrico
Dear Enrico
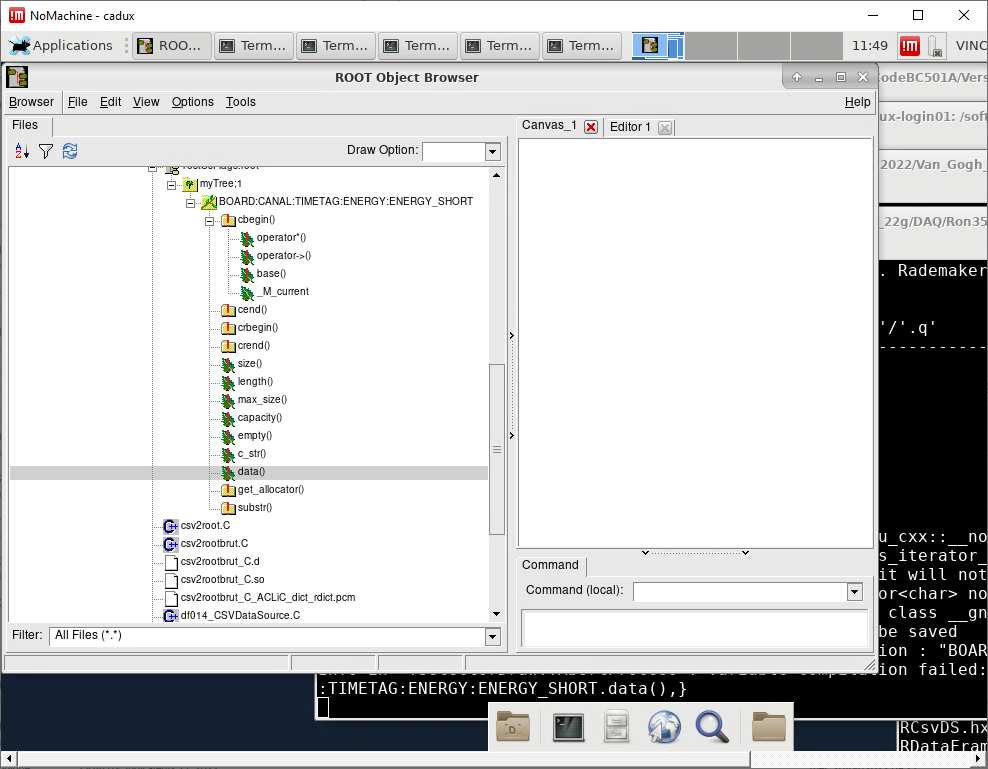
My goal is to obtain a tree having as leaves the titles of the columns
Regards
Thibaut
for the moment I get this tree (see image)
Ah sorry, I thought the problem was just performance, so I did not check the tree contents.
MakeCsvDataFrame does not parse the contents correctly because a) the delimiter is ; instead of the default , and b) the header uses a different delimiter than the data.
Changing the header to also use ; and specifying to MakeCsvDataSource that that’s our delimiter, I get the expected tree out:
BOARD;CANAL;TIMETAG;ENERGY;ENERGY_SHORT;FLAG
0;2;193700111870948;395;255;0x4000
0;2;193700443142777;512;437;0x4000
0;2;193700834489222;1879;1562;0x4000
0;2;193700908930306;676;587;0x4000
0;2;193701112366768;968;690;0x4000
0;2;193701613869011;545;366;0x4000
0;2;193701795834206;2268;1941;0x4000
0;2;193702006826005;178;158;0x4000
and then
auto df = ROOT::RDF::MakeCsvDataFrame("foo.csv", true, ';');
gives:
/tmp rootls -t myFile2.root (cern-root-626)
TTree Apr 22 11:51 2022 myTree;1 "myTree"
BOARD "BOARD/L" 138
CANAL "CANAL/L" 138
TIMETAG "TIMETAG/L" 140
ENERGY "ENERGY/L" 139
ENERGY_SHORT "ENERGY_SHORT/L" 145
FLAG "FLAG" 169
Cluster INCLUSIVE ranges:
- # 0: [0, 7]
The total number of clusters is 1
Cheers,
Enrico
Thanks Enrico
It works now for the small file
I am now testing with my large csv file which is in fact 1,13E8 bigger that the test file
I did read it yesterday with this other program
’ ’
#include “Riostream.h”
#include “TString.h”
#include “TFile.h”
#include “TTree.h”
#include “TSystem.h”
void csv2rootbrut( char* argv)
{
std::string NomSortie;
string ReadFileName =argv;
NomSortie=argv;
NomSortie += “.root”;
cout <<" NomSortie"<<NomSortie<<endl;
TFile *f = new TFile(NomSortie.c_str(),“RECREATE”);
TTree *tree = new TTree(“coincidence”,“data from csv file”);
tree->ReadFile(ReadFileName.c_str(),“BOARD/C:CHANNEL/C:TIMETAG/D:ENERGY/I:ENERGYSHORT/I:FLAGS/C”,’;’);
f->Write();
cout << “apres Write()” << endl;
}
’ ’
Hi Thubaut,
good!
It might very well be that TTree::ReadFile is better optimized for CSV files of that size, but if you can share the number of columns and rows in the large CSV I can generate an artificial one myself and check where the bottleneck is.
Cheers,
Enrico
Hi Enrico
the number of columns stays the same but the number of rows is multiplied by the factor given above
Thanks in advance for your help
Regards
Thibaut
with the old method it costed 2 hours to build the root file …
with the RDF method , a root file is created but with a very small size
And i want to read a copy of it with the TBrowser I get the message
file Data_CH6@DT5730S_10548_Ron35.root has no keys
So it’s a 30+ GB CSV file?
yes
Is it too much for this method?
Regards
Thibaut
It depends on how much RAM you have 
I will check whether there are some optimizations we can do in RDataFrame+CSV, but I would suggest to split it in 10 or 50 CSV files using e.g. head and tail and run the program on the splits to produce 10 or 50 root files (that you can merge at the end if need be, but you can also just keep them separate).
Cheers,
Enrico
Hi,
I took a first brief look today and indeed for a large CSV (11 GB) the RAM usage exploded.
Telling MakeCsvDataFrame to read it in chunks of 100k lines fixes that:
auto df = ROOT::RDF::MakeCsvDataFrame("./large_body.csv", true, ';', /*linechunks=*/100000);
It still takes a while to process it afterwards but at least memory usage is under control.
I can also see that there are a couple of relatively simple performance optimizations we can do in the code, although I can’t tell how much it will help with your usecase (and they will end up in the next ROOT version anyway). Most of the time is spent parsing the CSV.
Cheers,
Enrico
P.S.
the first of said patches is at [DF] Avoid expensive stringstream construction in RCsvDS by eguiraud · Pull Request #10458 · root-project/root · GitHub
Dear Enrico
I have built a script using as you suggested head and tail
Since I need to analyze coincidences between two channels X and Y ( each event of channel X in a file …X…root and each event of channel Y in a file …Y_root)
I have several choices
A)Merge the NX splitted file issued root files in a merge_ChannelX.root file using hadd
idem for the NY splitted file issued root files in a merge_ChannelY.root file using hadd
and then do the coincidence analysis with these two big merge root files
B) do the coïncidence analysis in parallele ( but maybe with loss of coïncidence at limit a splitting issued files
C) find a an hybrid method
So for this I need to know the maximum manageable root file size ( 2 root file open en the same time)
Thanks in advance for your feedback
Regards
Thibaut
Hi @Thibaut_VINCHON ,
ROOT files can be very large, a few tens of GBs should totally be ok, but it is typical, for convenience, to keep datasets split in small ROOT files and then merge them only logically, in analysis code.
In practice if you have 10 ROOT files and you need to process them as a single large one it’s enough to put them in a TChain or with RDataFrame it just happens automatically when you construct it as RDataFrame("treename", {"f1.root", "f2.root", "f3.root"}).
By the way with the patch I linked above it takes 43 seconds on my laptop to process a CSV file of 32M lines (1.1GB), so it should not take much longer than 25 minutes to process a 37GB CSV file. Assuming this is a one-time kind of operation it might be acceptable. A ROOT version with the patch will be available tomorrow at Nightlies - ROOT under “pre-compiled binaries”.
Cheers,
Enrico
Hi
Thanks enrico for you answer
Q1) Do I have to install a patch and recompile root to use the chunk option?
Q2) On another hand , I would try to use Slurm on our cluster where root is installed
I tried with the same root script. it indicate error when could trough slurm
I already used SLURM with programs compiled with the root library . It was working
Do I have to transform my script in a compiled exe to work with SLURM
Thanks to answer to these 2 independant questions
Regards
Thibaut
For Q1, you can compile ROOT yourself with the patch or use the nightly builds that I linked above (pre-compiled packages or LCG releases – the nightly conda packages are currently not up to date).
For Q2, you can certainly run ROOT macros as SLURM jobs in principle, as long as ROOT is available on the worker nodes. The problems you are having depend on your specific cluster setup, it is probably a question for the cluster admins or a colleague that has been running ROOT on that specific cluster.
Cheers,
Enrico