I am using a macro (see [1]) to analyze a large number of Ntuples. The way I did this is quite common, a TChain is used to first add all files(~700files, ~70k events/file, tot. ~50 million events) and then use SetBranchAddress to access all branches inside each event and loop over the events in the TChain.
I found the macro usually stopped loopping over the events at pretty large number of events, but not always the same. Sometimes it stopped at ~10 million events level, sometimes at ~20 million. I am sure the adding file part is fine from the print out, it successfully adds all 700 files and prints the right number of entries.
That’s often an issue with either running out of memory or invalid memory accesses. The former you can check by looking at your machine’s memory usage / free memory. For the latter you can use valgrind, see Valgrind and ROOT
Absolutely, it’s called “bug fix” But we first need to find out what the issue is. Can you send the result of the two investigations I suggested you to do?
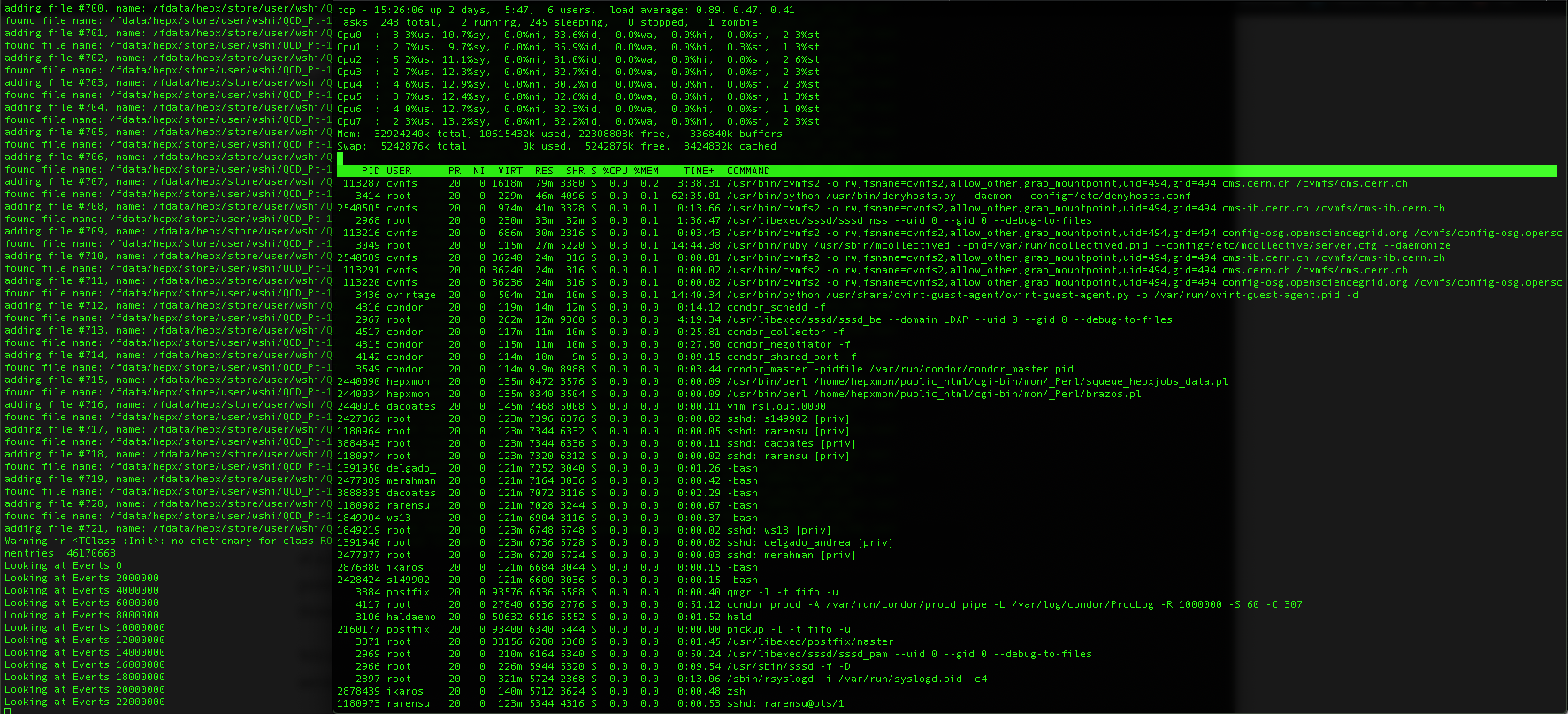
I used the ‘top -c’ command to check the memory usage when the macro was running.
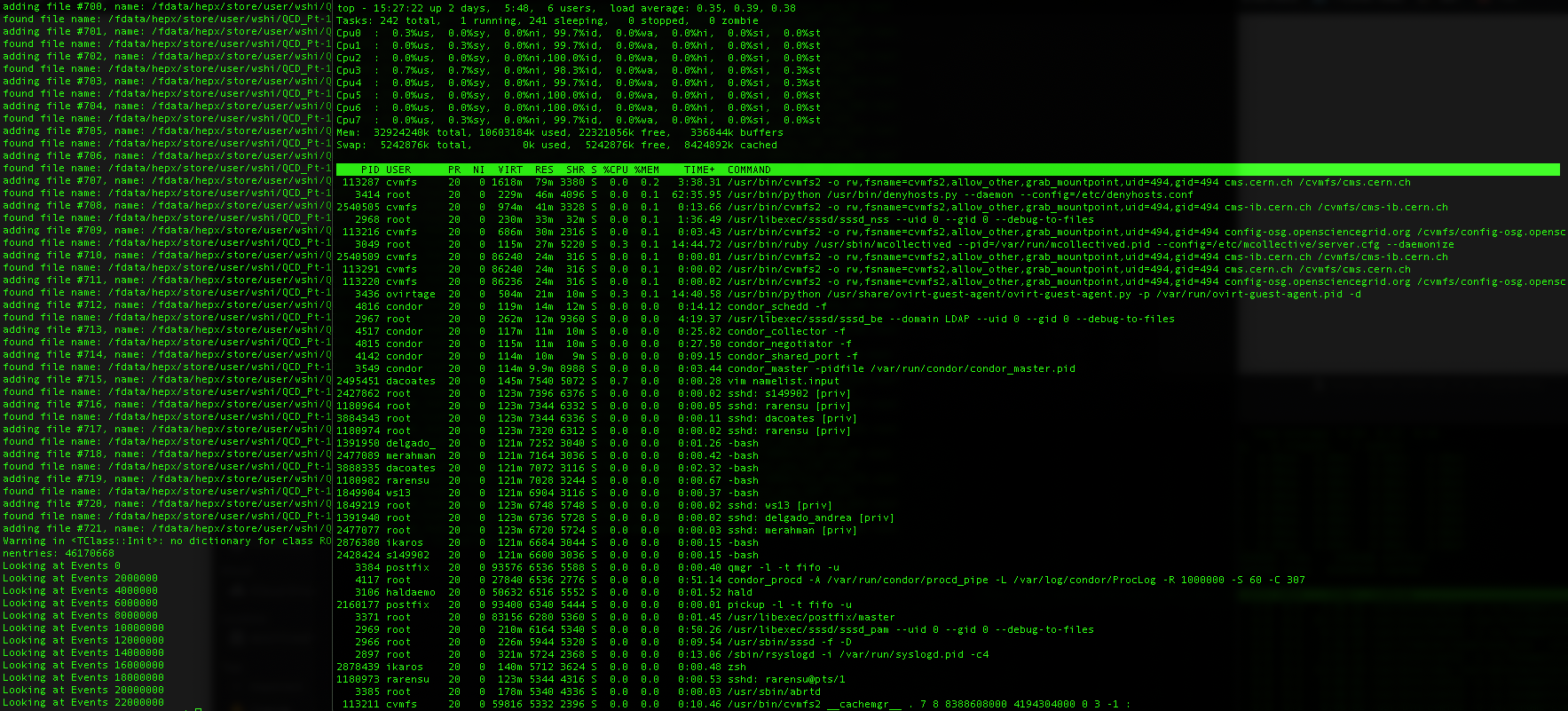
Here is a screenshot before the macro stopped at over 22 million events:
To me it doesn’t look like the memory ran out. But please take a look in case I misinterpreted. In the screenshot, my username is ws13. It’s a university owned cluster.
For the second case (invalid memory access), the page you pointed me to has some suppression command. What command should I use in order to check that?
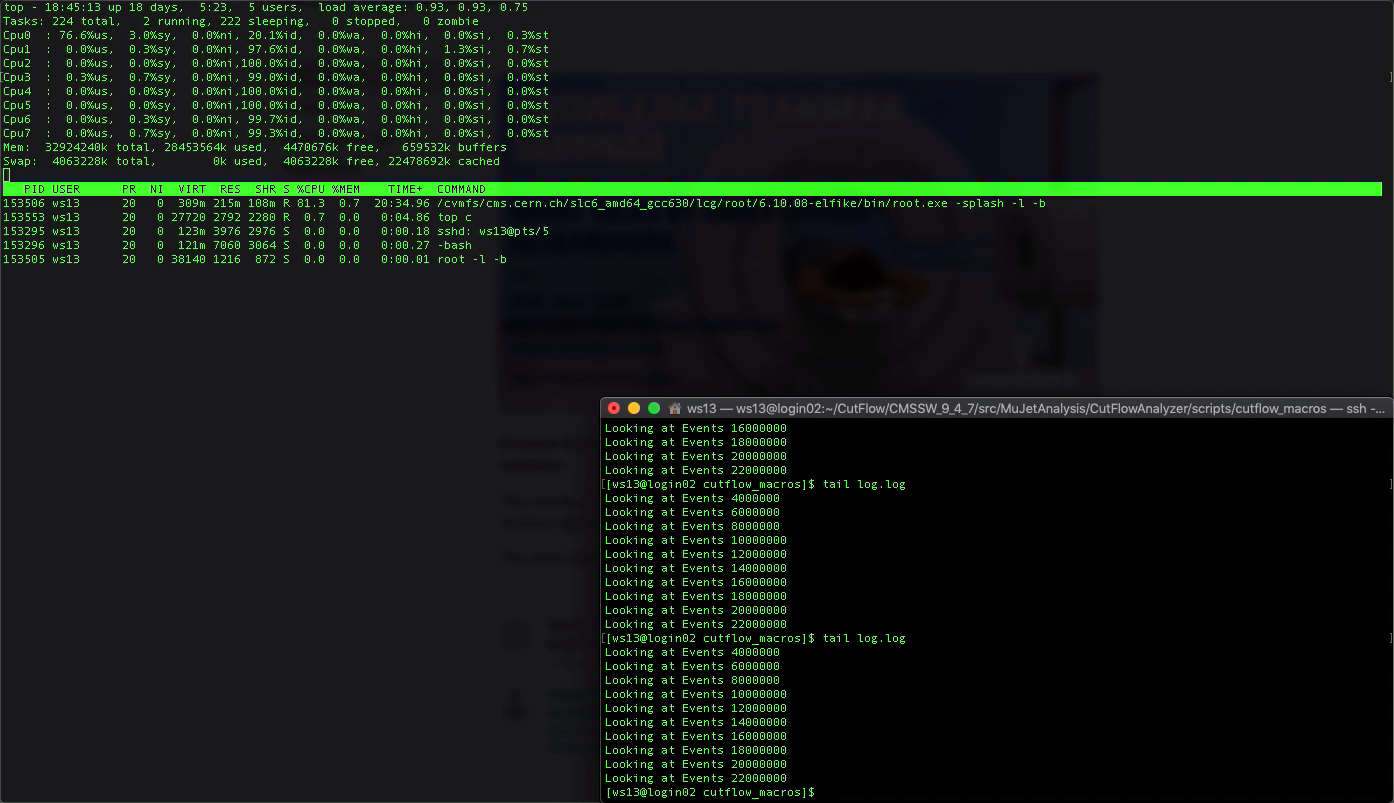
Sorry, the previous screenshot is not very informative, here is one shot with only my processes listed when the macro is running, the relevant PID is 153506, this is the last 1 second before the macro stops at over 22million events:
I can only see the CPU(%CPU) usage is high, but this is throughout the whole process while the macro was running. I don’t see any other peculiar behavior.
I used the command “valgrind --leak-check=yes” to do memory check as you mentioned in the second case. It prints out the following message, which I assume is fine? After these messages, the macro starts running until it stopped at some point as usual:
Pasted here:
==3417210== LEAK SUMMARY:
==3417210== definitely lost: 260 bytes in 12 blocks
==3417210== indirectly lost: 5,456 bytes in 87 blocks
==3417210== possibly lost: 193,312 bytes in 2,955 blocks
==3417210== still reachable: 104,576,119 bytes in 191,834 blocks
==3417210== of which reachable via heuristic:
==3417210== newarray : 32,448 bytes in 46 blocks
==3417210== multipleinheritance: 5,432 bytes in 8 blocks
==3417210== suppressed: 207,061 bytes in 2,271 blocks
==3417210== Reachable blocks (those to which a pointer was found) are not shown.
==3417210== To see them, rerun with: --leak-check=full --show-leak-kinds=all
==3417210==
==3417210== For counts of detected and suppressed errors, rerun with: -v
==3417210== Use --track-origins=yes to see where uninitialised values come from
==3417210== ERROR SUMMARY: 16085 errors from 158 contexts (suppressed: 366 from 328)
CPU time limit exceeded (core dumped)
Well, the ROOT version that you use seems to produce a huge amount of “spurious” valgrind warnings (I remember this problem at least in ROOT 6.10/08 and 6.12/04).
I guess @pcanal improved it in (some?) recent ROOT versions.
Can you maybe try ROOT 6.16/00?
You’re picking ROOT up from /cvmfs - so you could simply try this: . /cvmfs/sft.cern.ch/lcg/app/releases/ROOT/6.16.00/x86_64-centos7-gcc48-opt/bin/thisroot.sh
(under CMSSW_9_4_7 environment where ROOT 6.10/09 was default), I am getting this when opening ROOT:
/cvmfs/sft.cern.ch/lcg/app/releases/ROOT/6.16.00/x86_64-centos7-gcc48-opt/bin/root.exe: /lib64/libc.so.6: version `GLIBC_2.14’ not found (required by /cvmfs/sft.cern.ch/lcg/app/releases/ROOT/6.16.00/x86_64-centos7-gcc48-opt/lib/libCore.so.6.16)
If not under a CMMSW environment, the university cluster has an even older ROOT installed(5.34/38), it complains this:
/cvmfs/sft.cern.ch/lcg/app/releases/ROOT/6.16.00/x86_64-centos7-gcc48-opt/bin/root.exe: error while loading shared libraries: libpcre.so.1: cannot open shared object file: No such file or directory
@axel The “valgrind output” contains “/cvmfs/cms.cern.ch/slc6_amd64_gcc630/…” so I guess (s)he is using SLC 6 and so CentOS 7 binaries will NOT work.
Well, there are two options … (s)he could start to use a newer system (like CentOS 7) for which the newest ROOT is supported … or … use the old SCL 6 and find some binary distribution (from the LCG stack?) of the newest ROOT or downgrade the ROOT version (I think I remember there were only few “spurious” valgrind warnings for ROOT 6.08/06 and also ROOT 5.34/36 was fine).
There seem to exist some SLC 6 binaries in “/cvmfs/sft.cern.ch/lcg/views/LCG_95a/” or “/cvmfs/sft.cern.ch/lcg/releases/ROOT/6.16.00-f8770/” or “/cvmfs/sft.cern.ch/lcg/releases/ROOT/6.16.00-ecb64/”. For debugging purposes, it is better to take the “*-dbg” than the “*-opt” distribution.
it shows this
[ws13@login02 cutflow_macros]$ . /cvmfs/sft.cern.ch/lcg/nightlies/dev4/Sun/LCG_dev4/gcc/8.2.0/x86_64-slc6/setup.sh
-bash: /cvmfs/sft.cern.ch/lcg/nightlies/dev4/Sun/LCG_dev4/gcc/8.2.0/x86_64-slc6/setup.sh: No such file or directory
[ws13@login02 cutflow_macros]$ . /cvmfs/sft.cern.ch/lcg/nightlies/dev4/Sun/ROOT/v6-18-00-patches/x86_64-slc6-gcc8-dbg/bin/thisroot.sh
-bash: /cvmfs/sft.cern.ch/lcg/nightlies/dev4/Sun/ROOT/v6-18-00-patches/x86_64-slc6-gcc8-dbg/bin/thisroot.sh: No such file or directory
I checked the system linux distribution of the cluster, it shows CentOS 6.10, I guess it’s not CentOS 7 or SLC6 either:
[ws13@login02 cutflow_macros]$ cat /etc/system-release
CentOS release 6.10 (Final)
The Valgrind message before showed slc6_amd64_gcc630 because I did it under a CMS software environment.
 But we first need to find out what the issue is. Can you send the result of the two investigations I suggested you to do?
But we first need to find out what the issue is. Can you send the result of the two investigations I suggested you to do?