You must first make sure that ACLiC is able to precompile it:
root [0] .L analysis.C++
You cannot use “helgrind-root.supp” instead of “valgrind-root.supp” (you need to find this file, maybe it is not in the “root-config --etcdir” subdirectory but somewhere else).
So, it seems that your system administrators do not allow you to access “/cvmfs/sft-nightlies.cern.ch” (you will need to talk to them).
Maybe @axel knows another place which does not need “nightlies”.
under 5.34/38 are reporting many errors, such errors are not seen when compiling under 6.10/09. I also can’t find any valgrind-root.supp so far using:
find / -name “valgrind-root.supp”
Ok, now I copied all files to CERN cluster (lxplus7.cern.ch) where CentOS 7 is running. I used ROOT v6.16.00 by doing ‘. /cvmfs/sft.cern.ch/lcg/app/releases/ROOT/6.16.00/x86_64-centos7-gcc48-opt/bin/thisroot.sh’
By the time I post this, the macro is still in the process of looping over events (at ~7million), but here is the current seen output: Valgrind_Message_Summary_ROOT_v6.16_00.txt (621.5 KB)
I can see there are still many spurious valgrind warnings, but are there any hints from your perspective?
This seems to be the same screenshot as your previous one - is that intentional?
OK so copying is the way to go. You should have taken v6.18 - it has a much reduced number of valgrind warnings. Apologies this is such a rocky ride - it really shouldn’t be: we failed to address the valgrind warnings for way too long.
Once you have the warnings available with v6.18 please post them and we should be able to point you to where things go wrong.
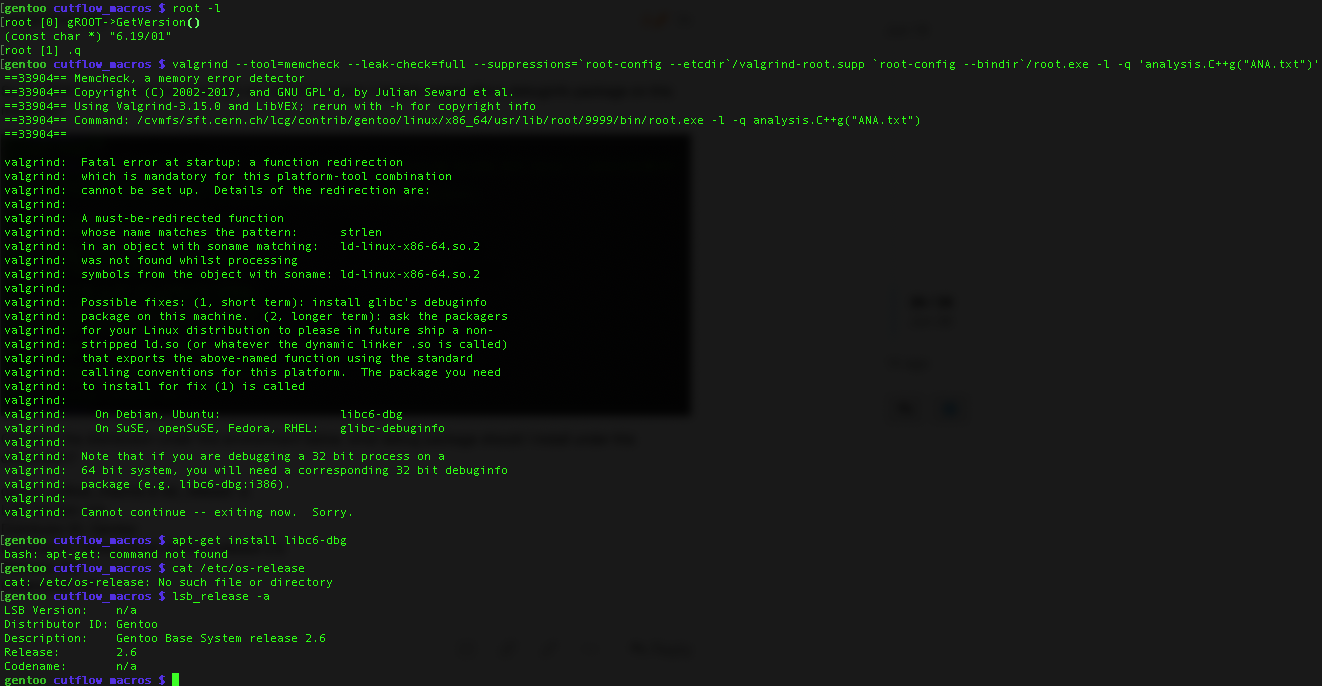
I don’t that think you can get the “valgrind” running on this “gentoo prefix” yourself. The error that you get suggests that there are vital components missing in this setup (and you cannot install / add them on your system, they would have to be installed in the “gentoo prefix” repository).
Interestingly, the same program running on lxplus7 (also with same ROOT v6.18.00) seems to be able to loop over all 46 million events, here is the valgrind output from lxplus7: Valgrind_Message_Summary_ROOT_v6.18_00_CERN_LXPLUS.txt (408.0 KB)
Anyway, it’s more interesting to know why the macro can’t finish on the university cluster, since all input files are usually stored there.
In the end it’s not a memory problem - I forgot this as a possible cause. But at least now you have the proof that your analysis does everything perfectly fine when it comes to memory!