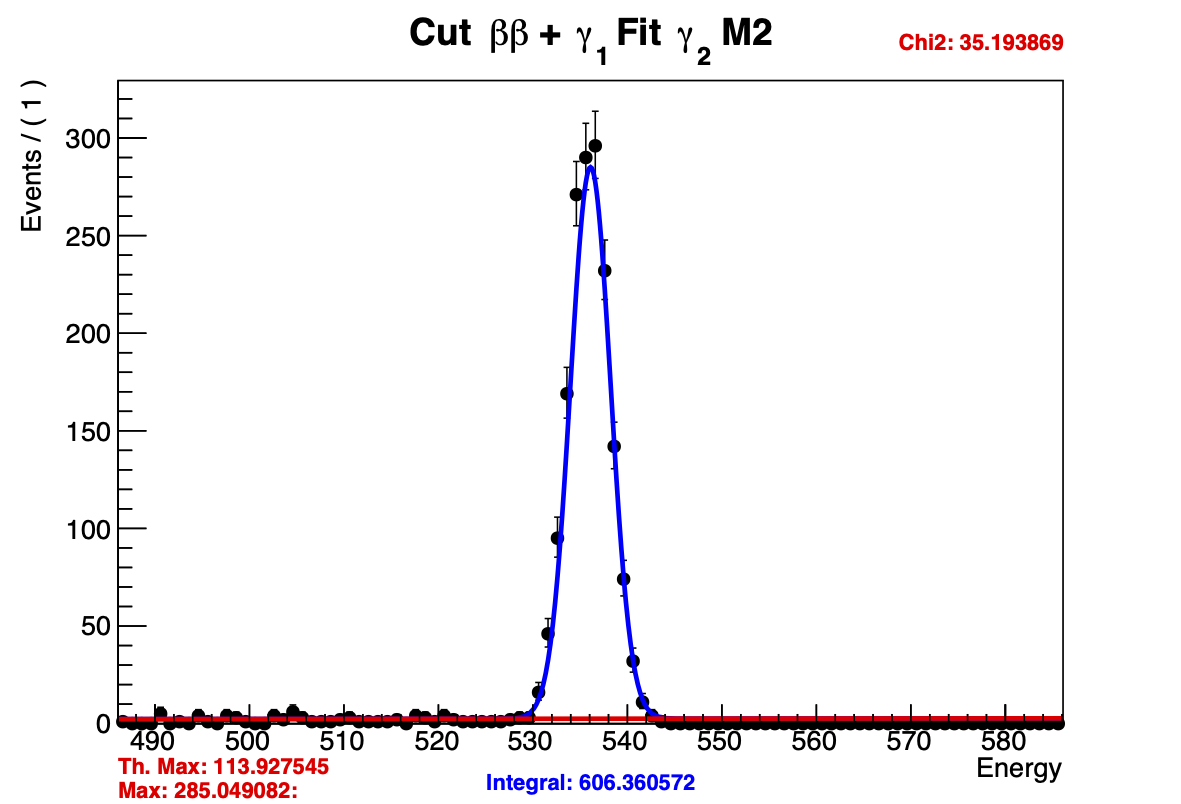
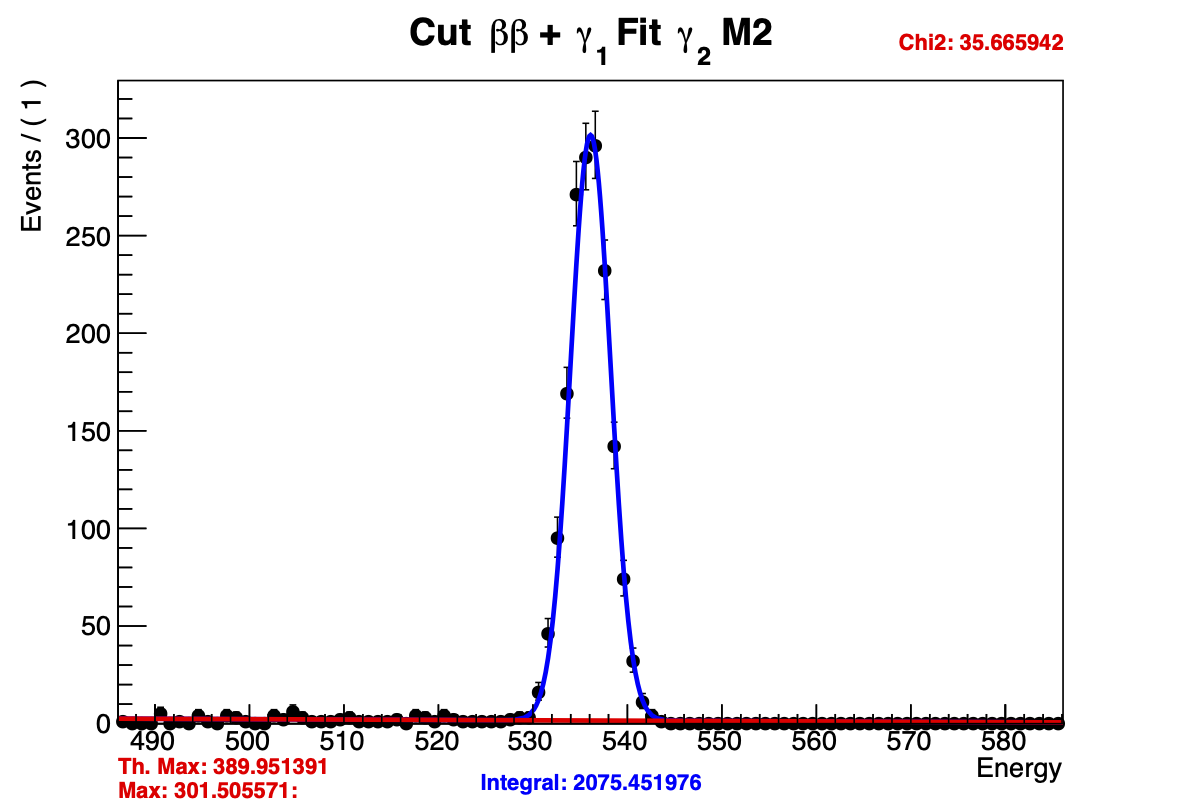
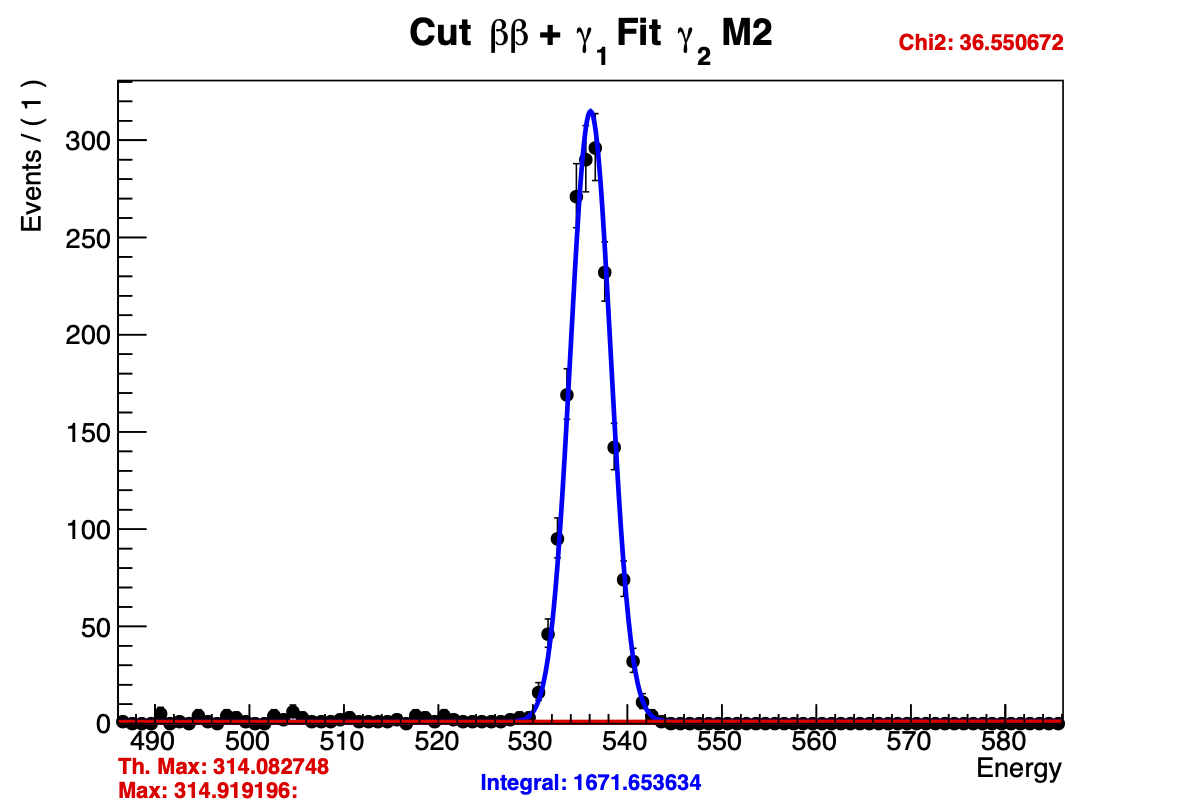
I’ve included FitterTest.C with Fit1() and Fit2() which generates these plots. The critical part is that the only difference between these two programs is that the range of a variable which is used in RooPolynomial is changed from (-1000,1000) to (-100,100). I came across this “fix” by accident and I suspect something else is wrong because I don’t understand why Fit1() works and Fit2() doesn’t.
I use the Integral value to calculate a the “Th. Max” and compare it to the actual value of the PDF at the peak. These values are compared on the plot to show that the integral is incorrect. The value of my poly_c1 is ~0.011.
If I run Fit2() again or run Fit1() before Fit2() I get
Obviously running these fits, I see that I’m getting a lot of warnings about minimization related to the pdf being negative for certain values of the polynomial. I would like to consider linear fits with negative slopes while constraining the pdf to be positive, but don’t understand if that’s the issue with these fits or if I can just rely on the fitter to discard those fits. I’m confused as to why raising the range of poly_c1 seems to fix these fits despite the fact that the finalized value is nowhere near the limits.
the first and most important piece of information is:
PDFs cannot be negative.
Polynomials can obviously be negative, and there is no protection in RooPolynomial against that. The moment any point of RooPolynomial is negative, the fit can produce wrong values. (It might recover by luck, and everything stays positive, but that really depends on the data.)
If you limit the range, it’s less likely that one of the negative points has been encountered during the fit, and therefore the fit converges. When you see warnings about negative results, you can only trust the fit result if these warnings happen early during the fit, and if there are no warnings at the end when errors are estimated.
Therefore, if you cannot trust the coefficients, Th. Max might be wrong. To really get a feeling for whether the Th. Max values are compatible, you should also compute the uncertainty of Th. Max taking into account all post-fit errors and correlations.
The RooBernstein Polynomials are exactly what I’m looking for. On a related note, this was happening with the previous fits, and now these Bernstein fits. (C1 and C2 are the coefficients for a B_{0,N} , B_{1,N} polynomial.)
If I run it a singular time, the fit converges on values
which. The C1 value has a perturbing error, but it seems to me that the other values are well defined. But if I run it a second time, these values slightly switch up to
These results are not drastically different, but if I keep running the fit, the results don’t shift off of this second set of values. Is this related to persistent values in the root session? Is one set of results more/less correct based on that, or is it all related to their uncertainties?
The second fit starts where the first fit stopped. You might be in a situation where the fitter is not allowed to do enough fit steps. Check the logs of the fitter to see what happens. It could saying something like “Maximum number of steps reached or so.”
I’m not seeing anything about that in the logs. Additionally how would the values persist? At the end of my program I delete the variables, and at the beginning of the program recreate them with their initial values. If I check through the logs I see that the variables are at their start values when it’s beginning Migrad Minimization
Moreover, how would I just add in more possible steps to the fitter? I’m looking through the manual and the closest option I can find is changing the MINUIT strategy.
I don’t think that xxx.Delete() is necessary. You normally use it to delete things from a canvas after it has been plotted. That being said, the fact that you put the variables on the stack is enough for them to go out of scope, so you are right, they don’t persist between fit steps.
What persists is the fitter itself. Apparently, the fitter keeps some state from the previous fit session, and this affects the convergence. I haven’t found the root cause of this problem, but what you can do is to give better starting values for the parameters. Don’t set the yields to zero, and also the limit at zero. Start with yields of 50 or so. In this way, you get faster convergence.
For the difference in starting points, I am testing at the moment if Minuit2 gives reproducible results.
Update
Indeed, Minuit2 produces stable results. What I did is to set all yields and the coefficients of the polynomials to non-zero to avoid starting at the limit values (you might have seen the warnings that minuit was issuing), and then I used Minuit2: