Dear Experts,
I want to do an unbinned fit of the distribution shown here.
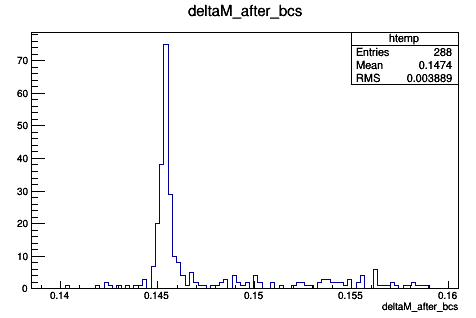
I am trying to use RooPolynomial to implement the background is whose form is:
(deltaM - 0.1399)^(1/2) + alpha * (deltaM-0.1399)^(3/2). Here’s the script and root file that i am using.unbinned_fit_ksks.py (3.0 KB) forfit_proc11_bucket9to12_bcs.root (12.5 KB)
Also, as the error message is vey long, I am attaching the .txt file here
fn_456.txt (137.4 KB)
I am unable to implement the background
Would you please help me?
Thanks,
Sanjeeda
Perhaps @StephanH can help?
Dear @jblomer,
Thank you so much for your message. I have now figured it out. Here’s how I implemented the background:
alpha = r.RooRealVar(‘alpha’, ‘co_efficient’,20,-100,100)
diff = r.RooFormulaVar(“diff”,“deltaM_after_bcs-mpi”, r.RooArgList(deltaM,mpi))
first_part = r.RooFormulaVar(“first_part”, “pow(diff,1/2)”, r.RooArgList(diff))
second_part = r.RooFormulaVar(“second_part”, “alpha*pow(diff,3/2)”, r.RooArgList(alpha, diff))
bkg = r.RooGenericPdf(“bkg”,“first_part + second_part”,r.RooArgList(first_part, second_part))
Also, in case you want to refer, here’s the complete code. unbinned_fit_ksks.py (3.1 KB)
However, I still receive some warnings. It would be of great if you can help me understand the warnings better. I am attaching here the runtime output.final_runtime_output.txt (24.7 KB)
Regards,
Sanjeeda
The warnings you receive have two causes:
- The function goes below zero. A PDF cannot do that, so you have to use something that stays positive. Check if either
first_part or second_part can go below zero, and either adjust the ranges of the parameter such that this doesn’t happen or use a different function. (The Bernstein polynomials are e.g. always positive, RooBernstein)
- The second warning you get is when there is a data point in a place where your background is zero. Since
log(0) cannot be used in a fit, you need a background model that doesn’t go to zero or you need to exclude the range where the model is zero, but there are some data points left.
By the way:
If the errors only happen during the minimisation, but they stop before the minimisation converges, it’s fine. The minimiser maybe just tested a wrong parameter, and then recovered and went into the “right” direction.
In your case, that seems to be the case, because there are no errors when calculating the covariance matrix (the HESSE step at the end).
