Have there been breaking changes in TMVA? I didn’t find anything in the Release Notes, yet I get a totally different (and wrong) result with 6.14.0 (working with BDT and gradient boosting). The first thing I noticed was that the correlation matrix isn’t created any more (and clicking on it in the TMVARegGui crashes it).
Is this known? If so, do I have to modify my code someshow?
If this is not known, I can try to create an example (not that easy for me to do, therefore I am first asking if anything has chaned).
There should have been no changes to the BDT output that I am aware of in the latest release. For the correlation matrix, there might was a change to the options (to allow omitting the printing of it during data loading, maybe this is related).
I’ll look into the missing correlation matrix, but for the totally different and wrong resutls of grandient boosted DT’s I need some more information
I think the correlation matrix has been removed by mistake. In case of very large input it does not make anymore sense to compute it, and it requires a huge amount of time.
I will commit the fix now and it will be in 6.14-patches
That wasn’t me And I saw the difference between the 6-12-00-patches branch (compiled a few weeks ago) and the 6.14.00 release.
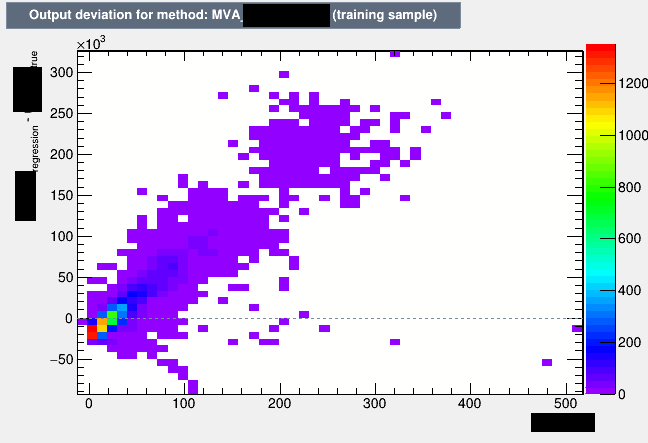
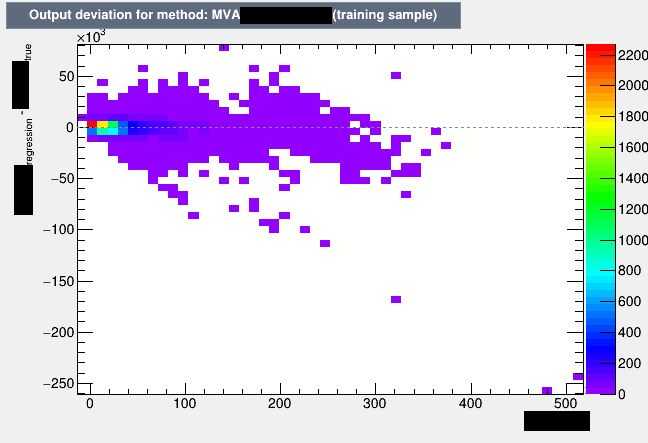
I’ll try to create an example. Need to anonymize data first. It was a very first try of a training. Anyway, the output looks like this:
In 6.14.00 (bad bad bad):
In 6.12.07 (good):
Yes, this is 4b) (but 4a looks similar). The training is totally unoptimized, i.e. neither are the input features “good” nor have I optimized anything about the number of trees. Usually, when TMVA is unable to do predict, it predicts the average. You then get a plot almost looking like a backslash, i.e. if you fit a linear function, it has a slope of -1. But here in the first plot the slope looks more like +1. Never seen that before!
I cannot share the input data file. Haven’t tried to reproduce with some random data yet but maybe the plots can give you a clue what went wrong here.
To Lorenzo: I saw the commit, thanks for removing the #if 0
When diffing the files, I am a bit surprised to see that a lot of spelling mistakes (“probably” -> “probaby”) and spaces at the end of lines have been introduced?!
For example:
git diff v6-12-06..master tmva/tmva/src/DecisionTree.cxx
(...)
- << "(Nsig="<<s<<" Nbkg="<<b<<" Probably you use a Monte Carlo with negative weights. That should in principle "
+ << "(Nsig="<<s<<" Nbkg="<<b<<" Probaby you use a Monte Carlo with negative weights. That should in principle "
<< "be fine as long as on average you end up with something positive. For this you have to make sure that the "
- << "minimal number of (unweighted) events demanded for a tree node (currently you use: MinNodeSize="<<fMinNodeSize
+ << "minimul number of (unweighted) events demanded for a tree node (currently you use: MinNodeSize="<<fMinNodeSize
The IMT changes in MethodBDT.cxx look innocent, so my best guess would be DecisionTree.cxx - but it might be elsewhere of course.
I tried reproducing the error using a linear function (Y = 2X + 1) with some random noise, and in this case the regression using GBDT seems to be working. It was a basic test case, and indicates that we need to learn more about your specific setup.
Could you provide some assistance in creating a reproducer? E.g. if you would know or have an idea about the characteristics of the events that are miss-reconstructed.
Edit: Output of BDTG with and without imt is identical for this setup. So again we need to understand your setup better to be able to reproduce the problem.
I’ve now modified my input data so that I can share it - also I have been using the tutorial/TMVARegression.C file and adapted it to the features and to the file name. I didn’t change the BDTG configuration. I hope you can reproduce it with the attached file.
To see the difference, run root TMVARegression.C with the different ROOT builds.
I ran the modified example on both imt and non-imt builds and the output is, for me, identical w.r.t. output of regression and the targets. However, both runs have outputs like “In 6.14.00 (bad bad bad)”.
Thus, more debugging is required. I suggest we move the discussion to JIRA.