When I try this, it gives me an error: Error in <TTree::SetBranchAddress>: The pointer type given "vector<double>" does not correspond to the type needed "Double_t" (8) by the branch: w0
Same error on the other branches, of course.
So, apparently, root recognizes the branch types to be doubles instead of double vectors (which I know is not correct, since I can analyze the file just fine using python.
What am I doing wrong? Is there some way to suggest the correct branch type to root?
Thanks for the interesting post and welcome to the ROOT Community!
This is odd. Are you sure that the type of column w0 is really a vector<double>? I ask because you start the post by calling those arrays.
Have you tried reading the file with RDataFrame? That would be the interface we suggest to use for analysis.
Could you also share the file for us to reproduce?
At my setup, I am writing awkward arrays to the branches. I am assuming that uproot transforms those into native types (vectors? arrays? I really don’t know because I can’t/don’t know where to look at the types in the root file…).
I would love to share the data file but it is 50GB in size and as such, can’t easily be shared…
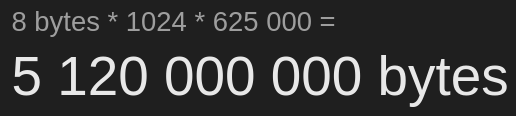
The number of entries amounts to what I expected to see. There should be 625000 arrays in that branch, which there are. Assuming that “/D” is the type of the branch, ROOT detects it as a "D"ouble branch type as the error message suggests?
But it is, see the 3rd entry in this post. If they weren’t stored as arrays, uproot would not be able to read in the rootfile and print the arrays like that…
It depends. uproot might have logic to read back the data from disk and do the necessary manipulation to treat the doubles as arrays but only in memory (e.g. simply by referencing a range of them to make the array of one event, this is just an example I am not sure this is how it happens).
I could try to reproduce your problem if you gave me a small ROOT file produced with uproot and possibly a reproducer of how to write that dataset. Unfortunately I can’t promise I would be able to test this immediately but I would come back to you once I try.
The code is embedded into our measurement framework and as such is a bit crowded, I’ll try to isolate the most important points:
with self.device:
self.log.info("Reading %d events...", max_num_events)
while nevts < max_num_events:
time.sleep(0.05)
waveforms = self.get_waveforms()
current_nevts = len(waveforms)
nevts += current_nevts
data += waveforms
self.log.info("Read %d out of %d events...", nevts, max_num_events)
self._chunk += data
self._meta_chunk += [meta] * len(data)
if len(self._chunk) >= self._chunk_size or ignore_chunk_size:
self.log.info("Chunk full.")
self.copy_and_save_chunks()
copy_and_save_chunks() creates copies of the chunk lists and starts a thread to save the chunks:
chunk = pd.DataFrame(chunk)
chunk = chunk.applymap(_format_waveform)
chunk = chunk.rename(columns=self._channel_map)
meta_chunk = pd.DataFrame(meta_chunk)
# Transform (meta)data to suitable format for saving
formatted = {"wfm": {}, "meta": {}}
formatted["wfm"] = {column: chunk[column] for column in chunk.columns}
formatted["meta"] = {
column: ak.Array(meta_chunk[column]) for column in meta_chunk.columns
}
# Note: Empty string next to zip function is necessary
if self._output_file is None:
# No rootfile created yet, so create it
self._output_file = ur.recreate(self._output_path)
for tree, data in formatted.items():
self._output_file[tree] = {"": ak.zip(data)}
else:
# Rootfile already exists, so extend it
for tree, data in formatted.items():
data["n"] = ak.Array([len(data)])
self._output_file[tree].extend({"": ak.zip(data)})
The TTree::Print confirms that the data for that branch is not stored as collection; There is a single value per entry. Uproot must have a feature that allows the loading of single element into a collection.
I have wrote a quick standalone script to reproduce my problem:
import uproot as ur
import pandas as pd
import awkward as ak
import numpy as np
channel_map = {
"CH0": "w0",
"CH1": "w1",
}
output_path = "test.root"
def generate_random_chunk(chunk_size, length):
"""Generate a chunk of random floating point numbers of a specific length and chunk size
on all channels specified in the channel_map."""
chunk = []
for _ in range(chunk_size):
channel_data = {channel: list(np.random.rand(length)) for channel in channel_map.keys()}
chunk.append(channel_data)
return chunk
chunk = generate_random_chunk(10, 1024)
chunk = pd.DataFrame(chunk)
chunk = chunk.rename(columns=channel_map)
# Transform (meta)data to suitable format for saving
formatted = {"wfm": {}}
formatted["wfm"] = {column: chunk[column] for column in chunk.columns}
output_file = ur.recreate(output_path)
for tree, data in formatted.items():
output_file[tree] = {"": ak.zip(data)}
Checking the generated data with the methods described in your previous posts, I verified that the problem occurs here, too.
@jpivarski This issue needs to be address in uproot, it is producing incorrect file. The correct leaflist needs to be recorded in the title of the branch.