what you are looking for is either hand-crafted errors or a hand-crafted minimization function. Either way it’s impossible to help you without knowing how exactly the points at larger x should have less importance. We’ll probably need the full story to be able to give a hint what to do: what is measured, where do the uncertainties come from, why don’t you like some of the points.
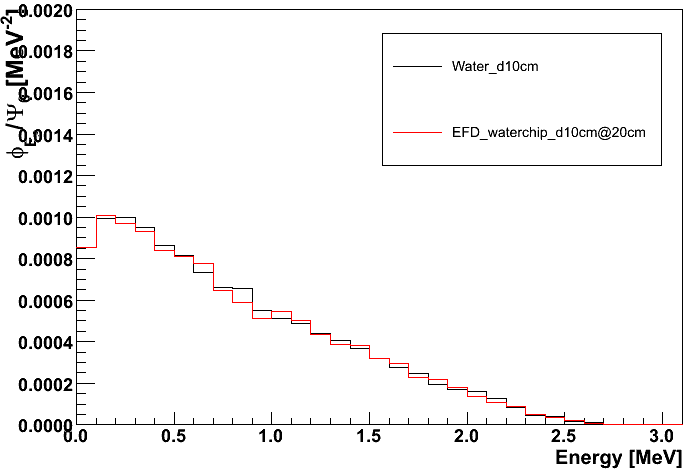
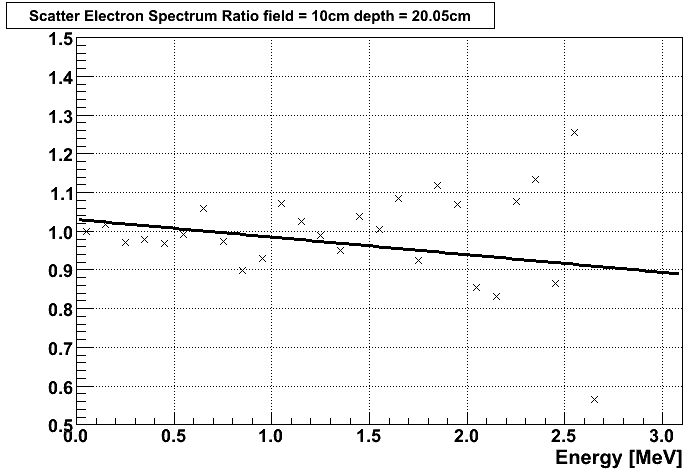
My points are ratios of electron fluence, so my x is energy (MeV) and y has dimension 1. The histograms of the fluence is shown in the first attached file. I wish to look at the ratio of the red and the black histograms. The ratio is shown in the second attached file. When the energy approaches the maximum electron energy the fluence is very low, so the points will be almost “0/0”. Very small differences in fluence give large difference in ratio at these energies (x-values) but these points are not very relevant for the general trend in fluence ratio.
My greatest concern is that I don’t fully understand how the Fit-function works. What do the default settings give me? And how can I change the defaults? And how can I extract information about the results 8succes) of the fit.
Where are the errors on your data points? without errors the fit is meaningless. By default teh fit will assume a statistical error being the sqrt(bin contents). Of course in your case this does not make any sense
yes. And the fit will “trust” the points depending on their uncertainties. So if you have a way to determine or at least model the original histograms’ uncertainties then that’s the way to go. If your histograms contain counts then the errors might be simply Poisson errors, and calling hist->Sumw2() before filling them would be sufficient.
what’s minimized is the sum of the (difference[i]/error[i])^2, where the difference is the difference of the point and the fit function’s value, summed over all points i.
Thanks for all help! I still have a few questions on the subject. What happends to the errors if I rebin my hisograms? I also still wonder how I can know how well the fit suits the data, can I extract som information about that?
I have succeded quite well with the fit I asked about at first, thank you for all help with that!
Now I have another fit that I am confused over as well. The figure with data-points and fitted line is attached at the bottom. I do:
TF1 *f_fit = new TF1("f_fit","[0]+[1]*x");
TGraph *g_RFvsSF = new TGraph("RFvsSF_Varian4MV_20cm2.txt");
g_RFvsSF->Draw("AP");
g_RFvsSF->Fit("f_fit","WW","");
f_fit->Draw("L same");
And in the statistics-window I get the information (see also attached figure):
MIGRAD MINIMIZATION HAS CONVERGED.
MIGRAD WILL VERIFY CONVERGENCE AND ERROR MATRIX.
FCN=0.0262358 FROM MIGRAD STATUS=CONVERGED 31 CALLS 32 TOTAL
EDM=1.31347e-023 STRATEGY= 1 ERROR MATRIX ACCURATE
EXT PARAMETER STEP FIRST
NO. NAME VALUE ERROR SIZE DERIVATIVE
1 p0 9.68291e-001 1.34283e-001
2 p1 1.34482e-001 3.48373e-001
FCN=0.0262358 FROM MIGRAD STATUS=CONVERGED 31 CALLS 32 TOTAL
EDM=1.31347e-023 STRATEGY= 1 ERROR MATRIX ACCURATE
EXT PARAMETER STEP FIRST
NO. NAME VALUE ERROR SIZE DERIVATIVE
1 p0 9.68291e-001 1.34283e-001
2 p1 1.34482e-001 3.48373e-001[/quote]
What is the difference between the “error” in the output in the terminal window and the ± information in the statistics window? How should I interpret the information about the Chi-square?
NB, I have not set any errors on these points, I use the “WW” option in my fit.
3) When fitting a TGraph (ie no errors associated to each point),
a correction is applied to the errors on the parameters with the following
formula:
errorp *= sqrt(chisquare/(ndf-1))
Ah, Ok, I see. Thanks for pointing this out! Would you happen to have a link to a page explaining why this correction has to be applied? Once more, thanks for your help!