In the sample code attached here, I am trying to incorporate my knowledge of root file and TTree. The next line of job is to use TChain to add the many root files that I obtain.
I have a couple of doubts regarding how the code is working. First, in line 11, I do:
t->SetMaxTreeSize(5)
Question 1: How does this, together with the number of iterations inside my loop, determine how many root files I am going to get at the end of the process?
So, once I ran this macro, I got six root files named file.root , file_1.root, …, file_5.root.
So before I chain these root files, I wanted to see what they contained.
So I went to the root terminal and executed following lines of command:
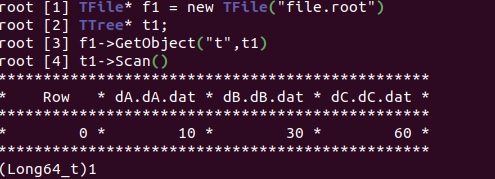
TFile* f1 = new TFile(“file.root”) ;
TTree* t1;
f1->GetObject(“t”,t1);
This gave me
Ok. I then did:
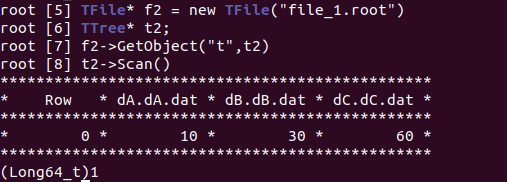
TFile* f2 = new TFile(“file_1.root”) ;
TTree* t2;
f2->GetObject(“t”,t2);
I was expecting this to print out row 1. But, instead it gave me the same output:
And same with all other root files.
What did I do wrong here? Any help would be very much appreciated.
I apologize, but I am confused as to why it is just giving me the output of the first loop even when I tried changing the MaxTreeSize all the way up to 100. So basically my question is:
Why am I getting 5 .root files for both SetMaxTreeSize(5) and SetMaxTreeSize(100)?
OK, I think playing with 5 bytes or 100 bytes is simply too small (with the metadata overhead). Try with a longer loop and higher maximum size, you will see the number of files will be different
Yes, I realized that if I do SetMaxTreeSize(500), for example, it only gives me 1 root file. But regarding your comment “What do you expect? It’s the same tree split in different files… Or did I miss something?”, I guess I am misunderstanding things or something. I was thinking the whole point of having multiple root files was that if you have enormous data, let’s randomly say 10000 data points, the very first root file would hold data points from 1 to 1000, the second root file would then have data points from 1000 to 2000, etc. But if same tree (with exactly same data points) were to be split in different files, why is that useful?
a, let’s randomly say 10000 data points, the very first root file would hold data points from 1 to 1000, the second root file would then have data points from 1000 to 2000, etc.
Yes this is the case/intent.
But if same tree (with exactly same data points) were to be split in different files, why is that useful?
In your example all the row are filled with the exact same data so you can not distinguish them.
I was expecting this to print out row 1. But, instead it gave me the same output:
So row number is in relation to the current TTree and/or TChain. Once the TTree is split, the row have no knowledge of where they were in the original order.
This lack of “unique identifier” for the row is intentional (because in most case of use of TTree the order is not important). It is common to add a column that contain a semantic unique identifier (for example Event Number and Run Number); in your example you could add a column containing the value of i for example.
This makes so much sense now. Thank you. Also when I run the macro the first time, it gives me a number of files, let’s say file.root, file_1.root,… When it do it the second time, it gives me file__1.root,file__2.root, etc. Right now, I make any changes in my code, I delete the previous ones. Is there any way around this?