I’m trying to run the BDT classification with 12 variables. In a subsample of events, 3 out of the 12 variables are missing and are assigned a default value = -9999 no matters if it is a signal or a background event. Even if the BDT looks working pretty nicely, it seems to me a perfect case where the usage of the category method could improve the classification (or at least I would expect a non-worse behavior).
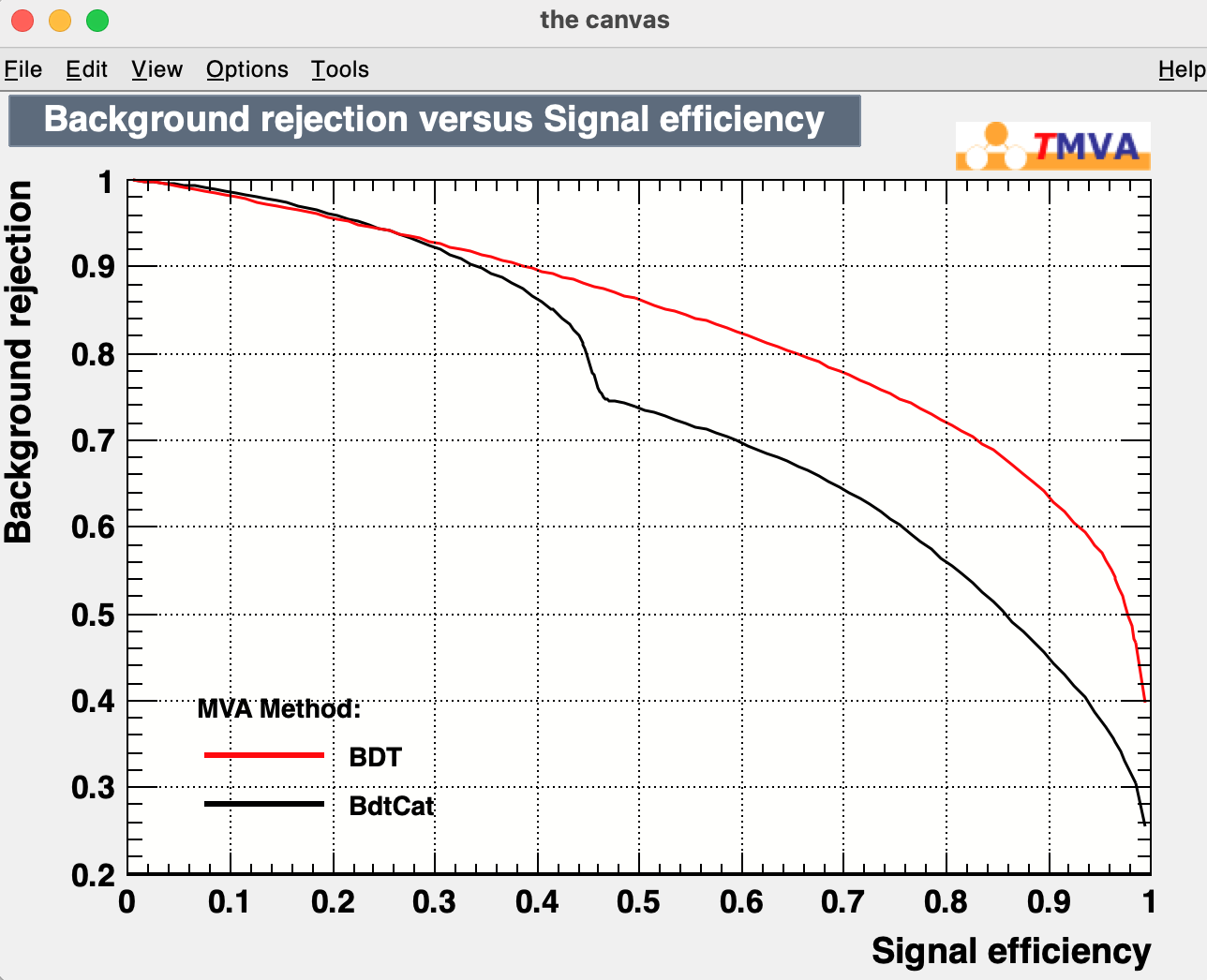
I tried to implement the classification with the category method but I’m a bit perplex about the results. I attach here the macro I used for the training, the output text file and the distributions of the BDT output classifier and a comparison of the ROC-curves. In particular the two-peak shape of the classifier distribution is quite worrisome to me.
I’m wondering if I’m doing something wrong and in case how to implement correctly the procedure.
Please let me know if I have to provide other information. The trees I’m using are quite huge but if needed I can select a subsample to test the macro.
Thank you very much.
Best regards,
Your macro seems correct to me. At first sight, it seems correct to me. It is an interesting case, I would need to get access to your trees to understand what is happening. If you could share them, for example on cernbox, I could have a look,
I forgot to tell you that the distributions I posted at the beginning of the thread are obtained with TMVAClassificationCategory(1,2,“BDT”,1).
Thanks a lot again.
Cheers,
Thank you for the update of the macro. I could run it and I could reproduce results similar to yours, although the difference between NDT and BDTCat is less pronounced.
Thinking about it, I think it makes sense to me that the performance of the single BDT are superior, because you are using more events for training trees. In the category case you are training separately two different methods, and in principle, if there are no real physical difference between the two cases, it is expected you will get worst performances.
I think the category can be useful for some cases where there are some physical differences between the two category, for example angular region of a detector where you have in place a different type of detector with different resolution, in this case it is maybe better to not mix all the events together. Although I can expect that in several cases, the algorithm can learn the different itself, if they are well reproduced in the data.
thank you very much for your reply!
Indeed, the two categories refer to events which are completely similar from the physical point of view (and also from the point of view of detector’s resolution), the only difference is that due to dead areas and detector efficiency in a subsample of events some variables are not present, but apparently the BDT is able to handle this very satisfactorily. Your explanation is very reasonable, now it is more clear to me which are the cases where the usage of the category method could be useful.