Hello,
For the last week I have been trying to compile the GemGPU example but to no success. Both Tensorflow and PyTorch can detect my GPU, both nvidia-smi and nvcc -V work fine and cudaGetDeviceCount() returns 1, which is the exact number of available GPUs my computer has. I also used -DUSEGPU=ON when calling cmake before installing Garfield.
The aval.ResumeAvalanche() call (line 90 of the example) triggers the following error message:
Line 238 in the AvalancheMicroscopicGPU.cu file seems to be the one triggering the error, but I have no idea on how to fix it.
Any help is appreciated. I’ll be glad to provide more information if needed.
ROOT Version: 6.32.2
Platform: WSL2, Ubuntu 22.04
CUDA Toolkit Version: 12.6
Compiler: GCC 11.4.0
Hi,
this might have been fixed by this merge request:
Could you update and try again?
I tried re-installing Garfield, I am getting the following error code during the make install step of the installation:
I was able to work around the error by installing the pip version of CMake (I was previously using the apt one). I ended up getting the same error as the one from my 1st post (thrust::system::system_error during the stack data transfer).
However, adding the -DCMAKE_CUDA_ARCHITECTURES=native flag during the cmake step of the Garfield installation caused something different to happen:
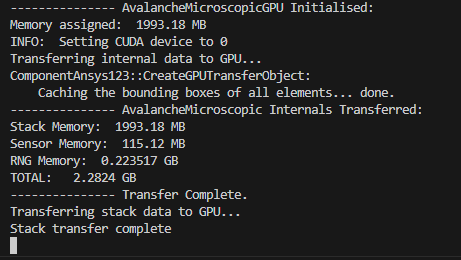
The executable was able to complete the stack transfer, but the terminal has been stuck like this for a few minutes now. I opened a second terminal, ran the executable and then closed the terminal. I was able to observe a drop in GPU usage:
Last minute edit: Alright, the example seems to be running normally, its just really slow compared to my CPU. When using nInitElectrons = 10000 the CPU is still a lot faster than the GPU, about twice as fast. Perhaps I’m missing something?
Hi @gabrielribcesario,
What GPU model do you have?
GPU: NVIDIA GeForce RTX 3090 (24GB)
CPU: Intel(R) Core™ i9-10980XE CPU @ 3.00GHz
Thanks. This isn’t a model we’ve tested before so it is interesting to see your results. Looking at the List_of_Nvidia_graphics_processing_units wikipedia page (sorry I can’t post links) it seems that double precision performance isn’t as good for the 3090s as for the typical data centre GPUs we’ve been testing (e.g. an A100 is listed as having 10 TFLOPS at double precision compared with vs 0.5 TFLOPS for the 3090).
We originally had the option to run calculations at single precision but that feature was lost in development. It might be interesting to try and resurrect it for cases like this.
Ah, I see! Yeah, that makes sense, this GPU is pretty good for Machine Learning tasks, as they generally use single precision, a shame I can’t use it to accelerate the Avalanche calculations. It looks like I’ll have to make do with the CPU + OpenMP for the time being.
Anyway, thank you both for your help @tomneep @hschindl !

