Hi all 
I used TMVA PyKeras and trained NN with my data. Then I got the scores from my trained model for the signal and background data. If we look at the distribution
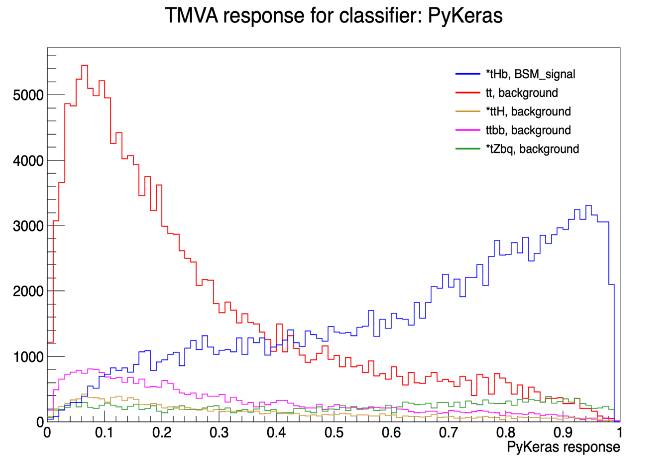
the signal samples massively tend to around 1 and background samples around 0, as it’s anticipated. When I try to build exactly the same NN model and train with exactly the same data, but using standalone Keras API and then try to get the scores from the trained model for the signal and background samples, we can see the following distribution
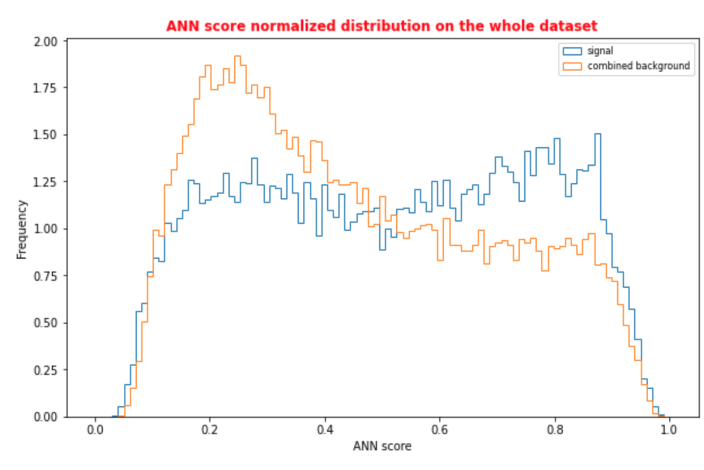
It’s seen that the model poorly distinguishes the signal and background samples from each other.
It’s interesting for me that although the ROC AUC I get using TMVA PyKeras is 0.79 and ROC AUC with standalone Keras API is 0.81, the model which trained using TMVA distinguishes signal/background better. Such distribution is important for my research since I obtain the values such as significance of the signal using this distribution.
I wonder if there is some additional hidden steps that TMVA automatically performs when I try to get the scores from already trained model?
Cheers,
Aizat