Dear All,
I’ve been playing for the last ~1 week with defining a custom data source for ROOT::RDataFrame, and came across the following issue while developing that code.
What I observed is that certain operations are very inefficient when running in multiple threads. I was trying to push as much of the initialisation of my custom data source to the multi-threaded execution of RDataFrame, as possible. But to my big surprise I found that this made my tests a lot slower than just executing that same initialisation in a single thread before the rest of the code would run multi-threaded. (Which means that I have an unavoidable, ~8 second initialisation time to all of these jobs at the moment.  )
)
To demonstrate the issue in piece of code that only uses ROOT’s own classes, I wrote this example:
Since the repo is not public, the relevant code from this file is:
int main( int argc, char* argv[] ) {
// Read the command line options.
const xDFT::CommandLineOptions cmdl( argc, argv );
// Set up the runtime environment.
ROOT::EnableThreadSafety();
RETURN_CHECK( APP_NAME, xAOD::Init() );
// Execute the file scanning using N parallel threads, X times.
const std::vector< std::vector< std::string > >
args( 50, cmdl.inputFiles() );
ROOT::TThreadExecutor pool( cmdl.nThreads() );
pool.Foreach( scanFiles, args );
// Return gracefully.
return 0;
}
void scanFiles( const std::vector< std::string >& fileNames ) {
// Set up a TChain for reading the files.
TChain chain( "CollectionTree" );
for( const std::string& fname : fileNames ) {
chain.Add( fname.c_str() );
}
// Load the first entry/file.
chain.LoadTree( 0 );
// Scan the branches of the tree.
TObjArray* branches = chain.GetListOfBranches();
for( Int_t i = 0; i < branches->GetEntries(); ++i ) {
TBranchElement* br = dynamic_cast< TBranchElement* >( branches->At( i ) );
if( ! br ) {
continue;
}
TClass::GetClass( br->GetClassName() );
}
return;
}
Now, when I run this test with different number of threads, I see the following scaling behaviour:
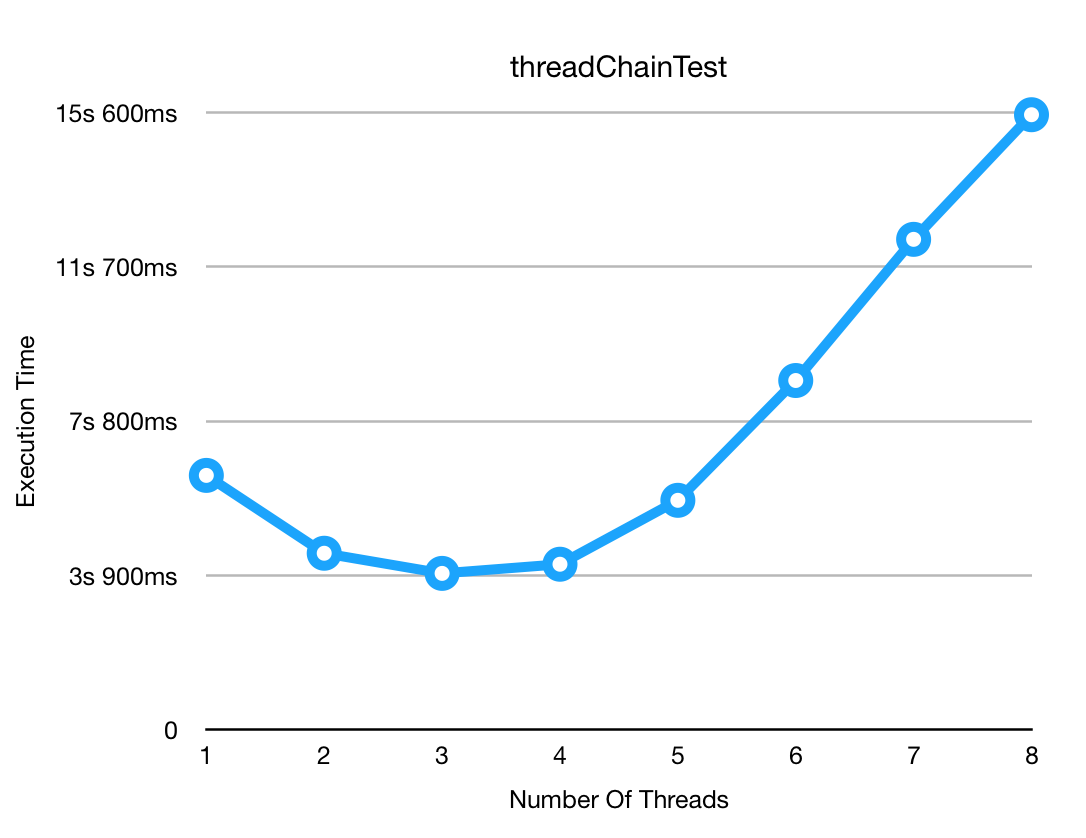
I.e. After a certain number of threads the internal locks of ROOT start to hurt the execution pretty badly.
Just to show one more thing, this is the profile I get from GPerfTools when running the executable with 8 threads:
threadChainTest_t8.pdf (17.7 KB)
I thought I’d write this up on the forum, instead of opening a Jira ticket with it. Since it’s not really a bug in the code. I just wanted to discuss a bit if it could be possible to improve on this situation…
Cheers,
Attila
ROOT Version: 6.14/04
Platform: x86_64-slc6-gcc62-opt
Compiler: GCC 6.2