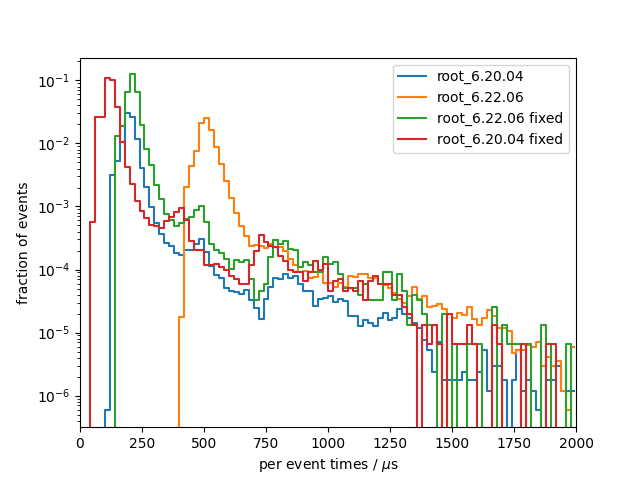
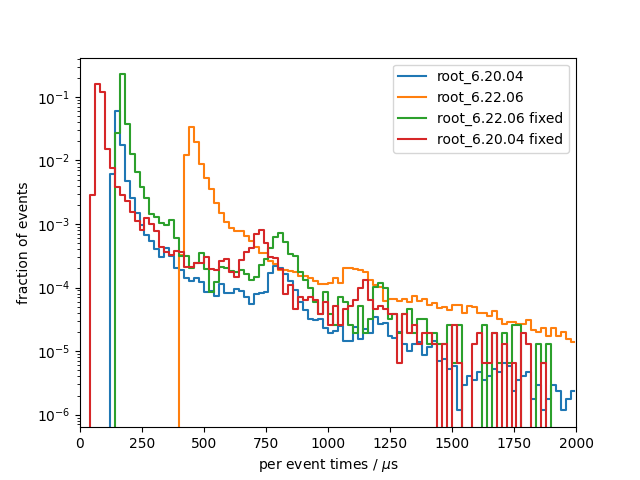
When opening the perf output, I got:
Kernel address maps (/proc/{kallsyms,modules}) were restricted. │
│
Check /proc/sys/kernel/kptr_restrict before running 'perf record'.│
│
As no suitable kallsyms nor vmlinux was found, kernel samples │
can't be resolved. │
│
Samples in kernel modules can't be resolved as well. │
and the content is missing the symbol names (it could just be me because I don’t have access to the libraries). I see a lot of:
+ 2.60% 0.00% DelphesSTDHEP_E libTree.so.6.22.06 [.] 0x00007f6d73b85616
+ 2.31% 0.00% DelphesSTDHEP_E libTree.so.6.22.06 [.] 0x00007f6d73b85645
+ 2.17% 0.24% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] std::use_facet<std::ctype<char> >
+ 1.89% 0.00% DelphesSTDHEP_E libDelphes.so [.] 0x00007f6d73e711bd
+ 1.88% 0.00% DelphesSTDHEP_E libDelphes.so [.] 0x00007f6d73e70199
+ 1.87% 0.00% DelphesSTDHEP_E libDelphes.so [.] 0x00007f6d73e7016b
+ 1.74% 0.00% DelphesSTDHEP_E libDelphes.so [.] 0x00007f6d73e71304
+ 1.72% 0.00% DelphesSTDHEP_E libDelphes.so [.] 0x00007f6d73e702b1
+ 1.72% 0.00% DelphesSTDHEP_E libDelphes.so [.] 0x00007f6d73e711ec
+ 1.70% 0.00% DelphesSTDHEP_E [unknown] [k] 0xffffffff8d00008c
If you see a better ouput, please copy/paste and send it to me.
Nonetheless the top items in reading are:
v6.22
+ 7.98% 7.96% read_benchmark libc-2.31.so [.] __strcmp_avx2
+ 5.25% 0.00% read_benchmark libc-2.31.so [.] __GI___libc_malloc (inlined)
+ 5.08% 0.43% read_benchmark libstdc++.so.6.0.28 [.] operator new
+ 3.48% 0.00% read_benchmark libTree.so.6.22.06 [.] 0x00007f2a5d70b645
+ 4.36% 0.00% read_benchmark libTree.so.6.22.06 [.] 0x00007f2a5d70b616
v6.20
+ 4.59% 4.59% read_benchmark libc-2.31.so [.] __strcmp_avx2
+ 3.96% 0.00% read_benchmark libc-2.31.so [.] __GI___libc_malloc (inlined)
+ 3.79% 0.18% read_benchmark libstdc++.so.6.0.28 [.] operator new
+ 3.73% 0.00% read_benchmark libTree.so.6.20.04 [.] 0x00007fa6da677fb8
+ 3.55% 0.00% read_benchmark [unknown] [k] 0xffffffff8d00008c
So the first 4 are taking a larger fraction of the time in v6.22 and hence are part of the slowdown.
For __strcmp_avx2 to take longer it needs to either:
- be processing longer strings
- be called more often
- spend more time fetching the memory
So
- is unlikely, it probably would require a change in input … or a bug …
- is plausible and callgrind would be able to tell if it is the case or not.
- would probably require the total memory usage to be much larger (or more fragmented memory.
for write
v6.22
+ 11.14% 0.34% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] std::basic_ios<char, std::char_traits<char> >::init
+ 10.21% 0.52% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] std::basic_ios<char, std::char_traits<char> >::_M_cache_locale
+ 8.62% 5.29% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] __dynamic_cast
+ 6.12% 6.11% DelphesSTDHEP_E libc-2.31.so [.] __strcmp_avx2
+ 5.56% 0.58% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] operator new
+ 5.35% 0.00% DelphesSTDHEP_E libc-2.31.so [.] __GI___libc_malloc (inlined)
+ 3.24% 3.20% DelphesSTDHEP_E libc-2.31.so [.] _int_free
v6.20
+ 13.03% 0.35% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] std::basic_ios<char, std::char_traits<char> >::init
+ 12.32% 0.67% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] std::basic_ios<char, std::char_traits<char> >::_M_cache_locale
+ 10.55% 6.63% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] __dynamic_cast
+ 4.41% 0.00% DelphesSTDHEP_E libc-2.31.so [.] __GI___libc_malloc (inlined)
+ 4.37% 0.26% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] operator new
+ 3.49% 3.49% DelphesSTDHEP_E libc-2.31.so [.] __strcmp_avx2
+ 3.03% 1.67% DelphesSTDHEP_E libstdc++.so.6.0.28 [.] __cxxabiv1::__vmi_class_type_info::__do_dyncast
Here the top 3 are taking less fraction of the time and thus other are responsible for the slowdown.
Here we see again that __strcmp_avx2 is taking more time. More surprisingly operator new is also taking more and (likely correlated) __int_free is taking much more time.
** Conclusions and questions
There are too many “anonymous” functions in the output to make a good comparisons. I do not know whether running with a RelWithDebInfo build would help but it is worth a try.
Since we have only the raw routine, getting a callgrind output would help us understand the direction.
The fact that string and allocation operation are on top is also making me wonder if we are not seeing the initialization phase being dominant in this “short” run.
So could you
- try running with a debug build
- publish the 17k event perfs
- try running with callgrind (with the debug build), 1000 events or even 100 events should be enough there.
Cheers,
Philippe.