as a follow-up of the recent CMS open data tutorial, I’ve been exercising on the Google cloud platform to get a grasp of eventual access modes to open data for open data users.
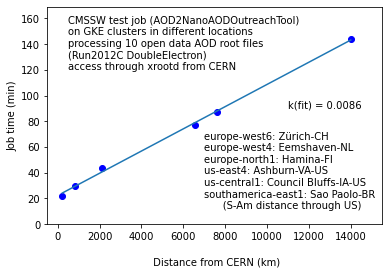
I’ve observed the following behaviour when running CMSSW analysis jobs on CMS AOD files (reading through xrootd from CERN):
These are 10 AOD files of total of 40G and 163kevts, and would be a normal first step of an analysis. I believe the time dependence on the cluster location is expected, but it is quite strong.
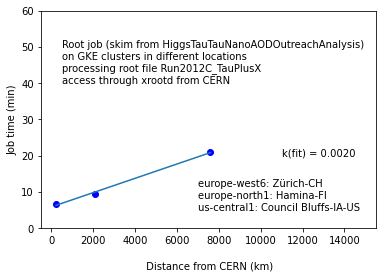
Comparing to the next step, i.e. running an analysis in plain root on the output data of the first step (again, in this case, reading the input through xrootd from CERN) I see the following:
This is a single root file of 16 G and 51 Mevts.
As you can see, the dependence on the cluster distance from CERN is four time stronger for CMSSW jobs reading AOD root files compared to root jobs reading plain root files.
I’m curious to know why this happens. Do you have some ideas?
For NanoAOD job you are using rootproject/root-conda:6.18.04 (even though you could try more recent version from rootproject/root-conda:6.22.02).
I’m not sure if it is correct to compare ROOT 5.34 vs 6.18, since there were so many improvements / design changes comparing ROOT5 and ROOT6.
It will be interesting to understand if there is a possibility to run AOD2NanoAOD on more recent CMSSW container (I see the latest is https://hub.docker.com/r/cmsopendata/cmssw_10_6_8_patch1 with ROOT 6.14.09), unless the CMSSW versions and dependencies are too different (no backward compatibility)?
I’d like to make sure it’s actually the data files causing this. Would you have a chance to mirror the files to some other xrootd cluster, and grab them from there instead? My theory is that it’s not the files dominating the slowdown but metadata access.
There are a couple of items we’re working on that will help in the near future:
async prefetching
TTree’s successor RNTuple - which operates inherently asynchronously and in parallel, hiding latency.
But instead of hoping for the future let’s first understand the here and now
Thanks for having a look! The CMSSW_5_3_32 container is the one that is needed to get access to open data, which is old by definition. We are actually using even older root version which comes with the CMSSW_5_3_32 release area (gROOT->GetVersion() in root in the container gives 5.32/00). That’s something we cannot change. I can eventually try with some more recent OD files (with some other example code) to see if the time dependence is different with CMSSW jobs with a more recent root version.
From the root point of view, it is certainly not correct to compare two (very) different root versions, but for me the interest is to compare the timing behaviour between steps CMSSW/“reading AOD open data files” and root/“reading root files derived from open data” so that we can eventually advise users for these two typical steps in the analysi process. For the first step, we are tied to the old version (because of old data) but for the second step more recent root version can be used.
And mainly I’m just curious to see this, and, if it is a matter of root versions, it is good to see that
more recent version behaves better in that sense
I realize indeed that there quite a many factors here:
the code (embedded in CMSSW vs plain root)
the data format (AOD with CMS-specific classes vs plain root)
the data format “usage” (picking a small part of a big event content vs using all of a small event content
the root version (old vs more recent) which I did not think of even if obvious, thanks for pointing that out
I have not mirrored the files, but I tested whether transferring first the AOD files to a disk storage connected to the GKE cluster and then reading them locally from a mounted volume makes difference. In this case, the AOD job run at the same speed compared to reading from CERN to a GKE cluster in Zürich. I believe this must indicate something … The files were not at the same node running the job but on a separate storage disk. I also tried this with the second step and I observed the same, but I will need to verify the timing for my test job (which is not the full analysis step).
So IIUC the timing is (to first order) not affected by the “distance” of the ROOT files? Good! If so: good luck hunting And indeed it’s good to hear that ROOT does a good job even with remote access - but again, we will further improve this, quite dramatically so, actually, to further reduce the slope of your second plot.
As the processing time should be the same for all locations, your job in Sao Paolo spent 120/140 = 85% in waiting. So there’s a fair chance that just calling gSystem->Backtrace() after 60 minutes should indicate what’s being waited for.



 … The files were not at the same node running the job but on a separate storage disk. I also tried this with the second step and I observed the same, but I will need to verify the timing for my test job (which is not the full analysis step).
… The files were not at the same node running the job but on a separate storage disk. I also tried this with the second step and I observed the same, but I will need to verify the timing for my test job (which is not the full analysis step). And indeed it’s good to hear that ROOT does a good job even with remote access - but again, we will further improve this, quite dramatically so, actually, to further reduce the slope of your second plot.
And indeed it’s good to hear that ROOT does a good job even with remote access - but again, we will further improve this, quite dramatically so, actually, to further reduce the slope of your second plot.