Hi,
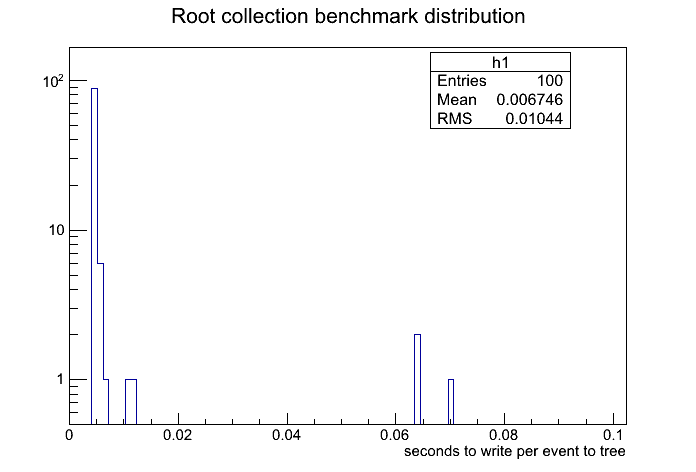
so, I was trying to benchmark root’s latency when collecting data in a standalone application, where the application writes events to a tree (event class is simple, such that it writes time and an array of track data). So it collected about 100 events, where each event had 10000 tracks. I timed how long it took to write each event to the tree. I attached the distribution of those times. So what puzzles me is that there are two peaks, one centered about 0.0047 seconds and the other about 0.064 seconds (granted the latter is a much smaller peak). What I notice though was that the data that contributes to the latter peak occurred after every 30 events written.
I had also noticed that the mean of the latter peak and its interval of occurrence is dependent on what the bufsize is set to when calling:
Tree::Branch(branchname, className, &p_object, bufsize, splitlevel)
So here’s my question:
- what is the cause of that latter peak?
- what formula can I use (I’m guessing that the size of the events are dependent on this) to set bufsize such that it would minimize the latency when collecting events to a tree?