I’m using RDataFrame to create histograms from tree. As I have many variable to plot, I use a loop to make the histograms and store them in a dict.
I found that, if I compute the error using Sumw2 after getting EACH histogram, my program is slowed down significantly. The only way to avoid it is completing filling the dict of histogram, then loop over the dict and do Sumw2.
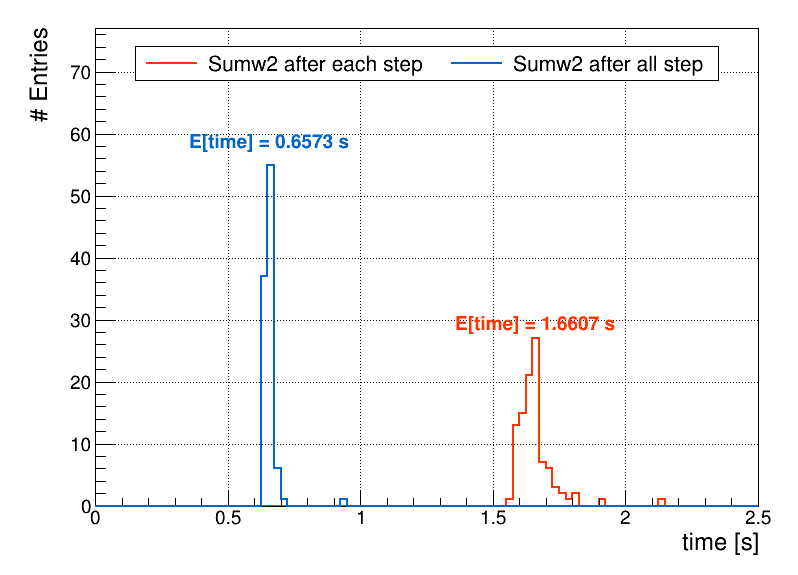
I have attached a test code [1] along with a text input [2], which can create a test root file, read the histogram and compute the error in different ways (like I describe above), so you can reproduce the result. For a small root file (less than 1MB), the different between 2 method is 1 second (plot in [3]). Is it what we should expect?
Another question I have related to the RDataFrame is that, if I add new column using Define (like I did in my test code), it will not work with root version 6.18 and above.
Hi,
RDataFrame is lazy: it only runs the event loop and produces the results when you access them for the first time. If you call a method on each histogram after RDF returns it, you run one event loop per histogram. If you call the method at the end, you run a single event loop that fills all histograms, that’s the reason for the performance difference.
In your case however I think what you really want is to call the static method TH1::SetDefaultSumw2(true) to turn on the weight sums automatically on all histograms, see the docs.
Cheers,
Enrico
P.S.
We added several useful features and important performance improvements for large-scale analyses with RDF in recent RDF versions, consider switching from 6.16 to e.g. 6.24.