Hello,
I’m trying to monitor the MT performace of my RDataFrame code with psrecord.
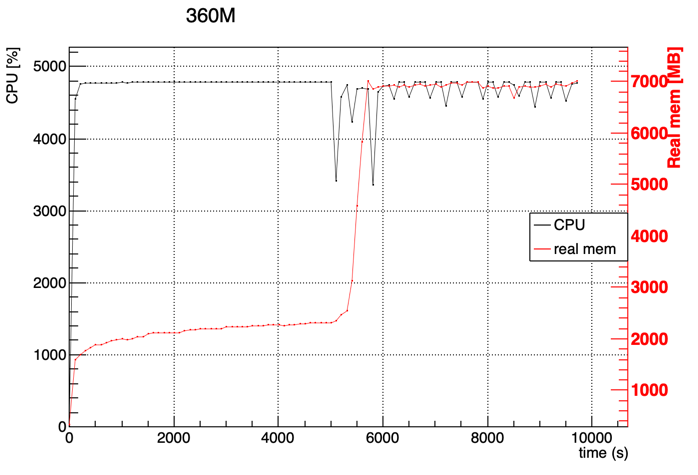
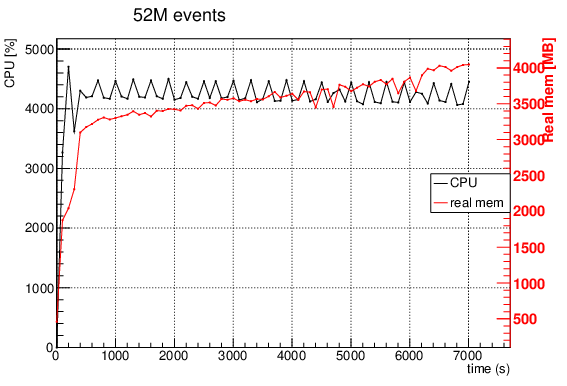
I observe a difference when I run from my local computer on remote files located on eos:
Is there a particular moment in the code flow which could explain it and/or something I can optimize (like file caching, number of threads, etc…)?
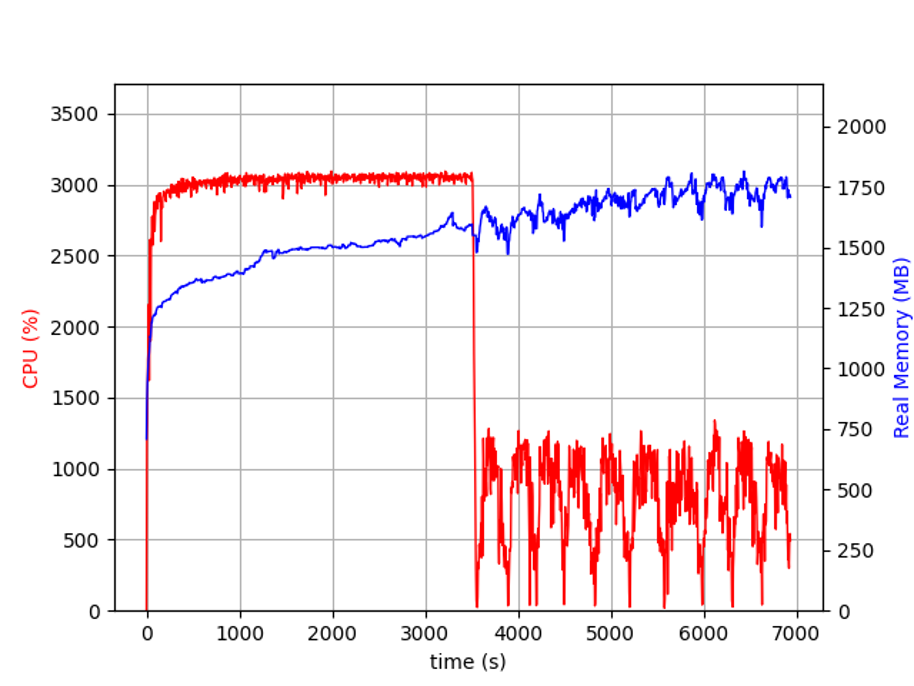
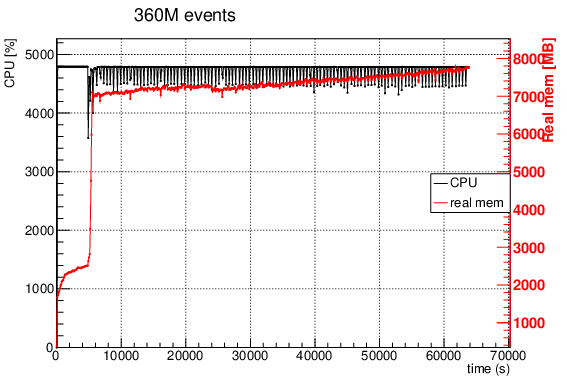
In a more recent example and more complex code I also see a large increase in memory at ~the same point:
I create a lot of TH1DModels at some point which are filled from different dataframes, etc…
(I’m not sure if it might be a memory leak because the total memory stays more or less constant afterwards)
Hi,
I am not an expert but i wonder if your initial timing and cpu usage is actually spent in compiling some expressions you use, and afterwarda you get limited throughout due to some network bandwidth limits (which you don’t have on local machines).i am also very interested on the outcome of this discussion since i also have very complex examples doing the same exact things you do here
Looking at the previous plots, it seems to me that the issue you are experiencing could be due to some bottleneck related to EOS file read. Regarding the increase of memory usage in the second case, I guess we need to investigate it further.
Could you please tell us how to reproduce these results?
Hello @jalopezg,
Thank you, I think I would be more interested in investigating if and how one could potentially avoid the bottleneck. I don’t have a simple example for the memory increase, this might be just as well be on my side, though I’d need to understand when exactly this could happen (like building the many TH1DModels, defining everal dataframes, filtering etc?)
Hi @RENATO_QUAGLIANI
Thank you for the suggestion! I didn’t think of this - is there any reference exactly which parts of the expression are compiled (or which parts are more complicated than others)? I would need to understand if I could avoid at least some parts of it…
Though the duration seems to be proportional to the size of dataset as well - I have two datasets which differ maybe 6-8 times in size, I run the same analysis on both, it seems that both the total duration and the initial step duration scale with the dataset size?
Can you share the code where you do all the operations?
I had in the past a huge slow down when i was doing a huge amount of :
Filter().Define("weight", wEpression).Histo1D()
I don’t know if that’s the case for you as well, the solution i found to make this as fast as possible was to refactor my code to have the Weight Definition only once with different bookkeped names if the weights were changing, and given that i was cutting several time my dataframe, and most of the time in the same way, i created a map< TString, RNode> to keep the nodes form Filters in a sort of cached place, to don’t redo the computation and compilation of the cut several time .
I have never run profilers for RDataFrame applications… but sometimes refactor the nodes building helped me to get much faster event loops…
Just for reference, we do observed several issues related to eos instabilities and RDataFrame in our analysis as well. Our code was not running with the same performance speed-up from a remote machine or from lxplus reading the files at /eos. That also might well be the reason of what you see.
From the main frame, I have a couple of Defines and simple Filters, then I would like to split the events into N categories and in these categories to M bins, where N,M I don’t know in the beginning/would like to set them up in a configuration file.
I have the code working unfortunately it is not efficient - going from 1 to 2 categories basically doubles the processing time. I do it maybe in a similar way as you do, only instead of a map, I keep a vector (size N) of DataFrames/Nodes pointers after I split them with a Filter and use these pointers then to split them into M bins (2D vector NxM), then I have a 2D vector (also NxM) of TH1DModels which are filled from each of the frame
Any idea where this becomes inefficient?
Some of the Defines in my code are ‘constants’ used in some later cuts/filters - I put those as new columns in the DataFrame instead of capturing these variables in a lambda. This was mainly that I could write each Filter as a full function which I could put into a separate file instead of writing a lambda in the middle of the code - is this a good idea or should I try to avoid unnecessary new columns? Most of the Defines are ints/floats or RVec, RVec, not complicated objects.
What might help is a system-wide flame graph to see what the CPU is doing when its utilization drops. It would be interesting to know if it is waiting for more data or if it is it stuck in a global lock. @eguiraud might have more ideas.
Hi,
It would be great to be able to run this ourselves to investigate properly, but from the plots these are my best guesses:
the first phase, that lasts about the same independently of where data is stored, is just-in-time compilation. String Filter/Defines such as Filter("x > 0") as well as non-templated actions such as Histo1D("x") (as opposed to Histo1D<float>("x")) need to be just-in-time compiled right before starting the event loop. I very much hope those are not really 3000 seconds, 3 seconds would be a more appropriate runtime for this phase
the drop in CPU usage in the second phase when reading for EOS is most probably due to too-slow network I/O: CPUs need to wait for the data
the increase in memory usage after the first phase is due to RDataFrame actually creating the histograms and all other storage necessary for the analysis at that point, right before starting the data processing. Running the program under valgrind --tool=massif should confirm that’s the case.
Do these statements sound reasonable?
Performance tips:
avoid unnecessary columns (e.g. for those constants that you mentioned), they have a cost and RDF does not know they are constants so actually re-evaluates the expressions at every entry
to split events into categories, I suppose you are using one Filter and one histogram per category? That is much less efficient than e.g. using a single higher-dimensional histogram, with its “slices” representing categories, or even a dedicated custom action (we should really provide such an action or at least an helper, but I could never quite put my finger on the scenarios we need to cover)
Hi @eguiraud,
Thanks a lot! There are several good suggestions which I will try!
the first phase, that lasts about the same independently of where data is stored, is just-in-time compilation. String Filter/Defines such as Filter("x > 0") as well as non-templated actions such as Histo1D("x") (as opposed to Histo1D<float>("x")) need to be just-in-time compiled right before starting the event loop. I very much hope those are not really 3000 seconds, 3 seconds would be a more appropriate runtime for this phase
Is there any counter available how many objects are compiled? I don’t know if in my case it gets compiled for each category? It also seems that the first part scales with the number of events in my case?
Does the Histo1D(“x”) work also for RVec<float> ? I will try it for saving on the histogramming part
Performance tips:
avoid unnecessary columns (e.g. for those constants that you mentioned), they have a cost and RDF does not know they are constants so actually re-evaluates the expressions at every entry
Ok, thanks! I will remove what I don’t really need. Do you have a good style suggestion - I use these constants in Filters, having them as columns, I could define the cut function in a separate header file - can I write a Filter function that takes both columns and other non-column variables as parameters? I could capture the parameter in a lambda but that would mean that I need to write the lambda somewhere in the middle of the code?
to split events into categories, I suppose you are using one Filter and one histogram per category? That is much less efficient than e.g. using a single higher-dimensional histogram, with its “slices” representing categories, or even a dedicated custom action (we should really provide such an action or at least an helper, but I could never quite put my finger on the scenarios we need to cover)
Thanks for the suggestion. It’s ultimately more than one histogram (like a vector of configured histograms) for each category (so M x N x O 3D array of TH1DModels, M,N,O are relatively small <10), but I will think if I can rewrite this in TH3DModels instead
Not really, but every Filter(string), Define(string, string) and Histo*D(...) call has to be just-in-time compiled. Filter(callable), Define(string, callable) and Histo*D<ColType>(...) do not require just-in-time compilation.
Ah that’s interesting, I don’t know what to make of it. As I mentioned it would be great to be able to run this ourselves to investigate properly. Could you provide a reproducer that we can run e.g. on lxplus?
Alternatively, as @jblomer suggested it would be interesting to look at a flamegraph of your application.
Yes, and Histo1D<ROOT::RVec<float>>("x") as well.
If you would rather not define inline lambdas, I would suggest to create them from a lambda factory:
auto MakeCut(float constant) {
return [constant](float x, float y) { return x + y > constant; };
}
Hello Enrico,
thank you very much for your suggestions!
A few remarks on what I tried:
The lambda factories are nice! For my C++ experience (or lack of it, especially in functions returning functions ) it somewhat abuses the C++ syntax I’m used to, but it allowed to reduce the number of Defines
The templated Histo1D unfortunately hinders my efforts to be able to plot anything from a configuration, I tried to rewrite this as
if (frame.GetColumnType(variable) == "type1")
{
result = frame.Histo1D<type1>(variable);
}
else if (frame.GetColumnType(variable)=="type2")
{
result = frame.Histo1D<type2>(variable);
}
else
{
result = frame.Histo1D(variable)
}
...
but I don’t know if the GetColumnType()/comparison with strings is efficient here, I could in principle rewrite this to an integer comparisons as I could know the types
if (GiveMeType(variable) == 1)
{
result = frame.Histo1D<type1>(variable);
}
else if (GiveMeType(variable) == 2)
{
result = frame.Histo1D<type2>(variable);
}
...
but it’s still not elegant as I have to repeat this a few times in my code…
But generally 1 and 2 didn’t bring a significant improvement so
3) I think the most important would be to avoid the splitting into separate dataframes and use TH2D/TH3D and slice them in the end
However, I don’t know how to fill the 2D histogram for this case?
Let’s say I will have a TH2DModel, x-axis will be the variable of interest, y-axis will be the categories - it seems that Histo2D will only support filling x vs y or vector<x> for 1 category?
In a loop-style, I would do something like
for (auto x: vector<x>)
{
for (auto category : categories)
{
my2Dhisto->Fill(x, category, weight);
}
}
(event could be filled for several categories)
but is it possible to achieve this with Histo2D?
vectorx vs vectory (possibly with vector_weights) is also supported.
I don’t understand the situation: for every event, x is an array (which represents different variables) and each element of the array could belong to one or more categories? What is weight? 0/1 depending
EDIT:
I might be missing the point, but how about a TH2D per variable, with the category on the x axis and the variable values on the y axis?
This works if the variable you ultimately want to fill histograms with is a scalar for every event:
// on_categories is an array with the bins of the active categories for this event
df_c = df.Define("on_categories", "{1,3,4,6}", {....});
for (auto &varname : varnames)
df.Histo2D(..., {"on_categories", varname});
If the variable is an array per event, the default behavior of Histo2D is not what you want, so you probably need Aggregate:
struct CategoriesAndValues {
RVec<int> on_categories;
RVec<double> values;
};
df_c = df.Define("categories_and_values", "CategoriesAndValues{cats, xs}", {...});
auto fill = [] (TH2D &h, const CategoriesAndValues &c) {
for (auto cat : c.on_categories)
for (auto x : c.values)
h.Fill(cat, x);
};
auto add_histos = [] (TH2D &h1, TH2D &h2) { h1->Add(h2); };
auto th2 = df.Aggregate(fill, add_histos, {"categories_and_values"});
The scalar option is nice, unfortunately the variables of interests are vectors/arrays so I will have to go the second option. The weight is an event weight, so I think I would need to add it to the struct CategoriesAndValues as well.
I’m a bit worried about the performance since it means re-adding the same variable, but I’ll need to test it first
The computation graph should shrink by a lot, and that should help performance greatly.
But again: every time performance is a concern, you should first of all measure what’s taking time, e.g. by looking at a flamegraph as suggested above.
Hello,
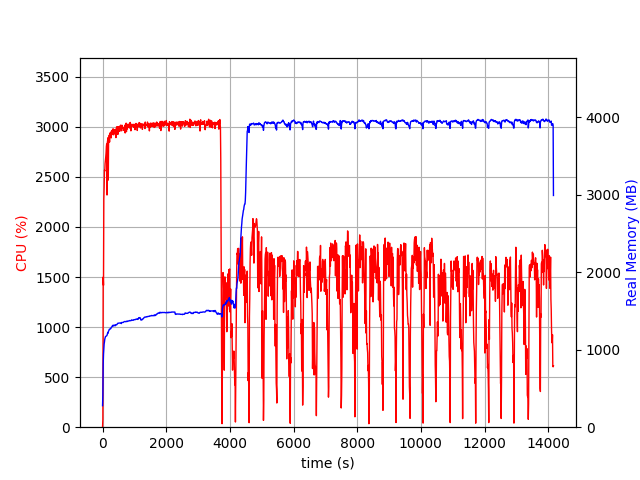
I have now managed to rewrite my code and I’m testing it at the moment:
I couldn’t get the Define work with the initialization list, I changed it to a separate function
as with U=TH2D in my case, the merger has a signature U(U,U), the aggregate is auto fill = [] (TH2D &h, const My2DObservablestruct &c) - is that correct?
the psrecord graph shows a huge (~factor of 10) improvement in time.
I’m at the moment investigating, but I’m getting a crash in the end when I try to create the RDataFrame graph - is it possible that I have too many Defines?
In my case, I not only have to (re)Define each My2DObservablestruct but since the ‘values’ in it take RVec<float>, I also re-Define non-RVec<float> (only int, float, RVec<int> in this example) variables to RVec<float> if I want to fill them using the same code
Is is somehow possible to ‘hack’ or change the column type in RDataFrame? Let’s say column is an integer, but I would like the RDataFrame think that it is a vector<float> of size 1?
No, that should not cause a crash. Do you get a stacktrace? Can you share a minimal self-contained reproducer so that we can debug the crash on our side? Otherwise I suggest you compile the code with debug symbols (-g) and inspect the point of crash with gdb.
If that becomes a problem you can use templates to write a generic My2DObservablestruct and two fill aggregate functions, one for the scalar case and one for the RVec case:
Unfortunately not, the type of the column matters because it tells RDF how to read the bytes from disk.
P.S.
better to take RVecs as const& function arguments to avoid extra copies: void fun(const RVec<float> &values) rather than void fun(RVec<float> values).

 ) it somewhat abuses the C++ syntax I’m used to, but it allowed to reduce the number of Defines
) it somewhat abuses the C++ syntax I’m used to, but it allowed to reduce the number of Defines