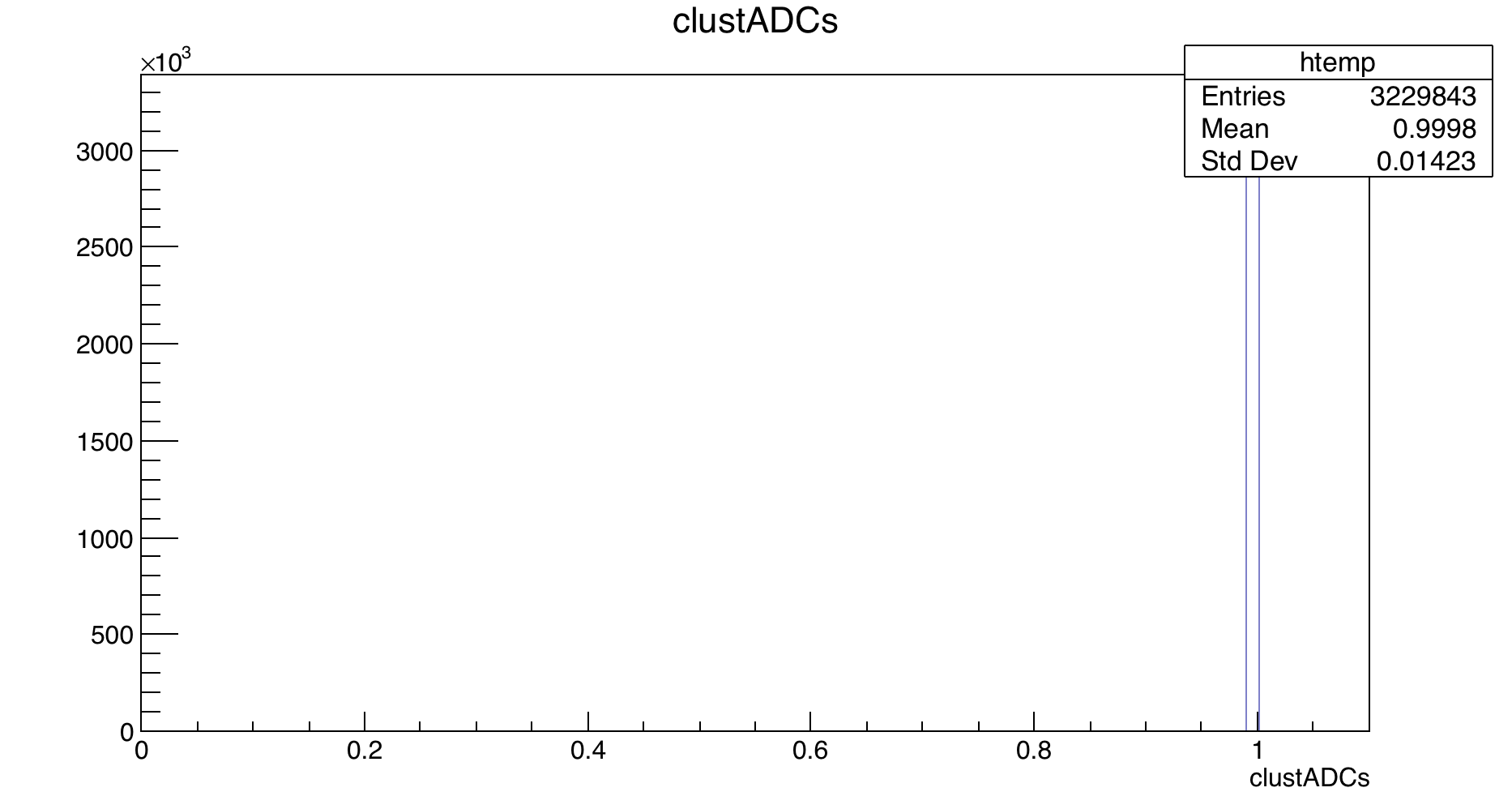
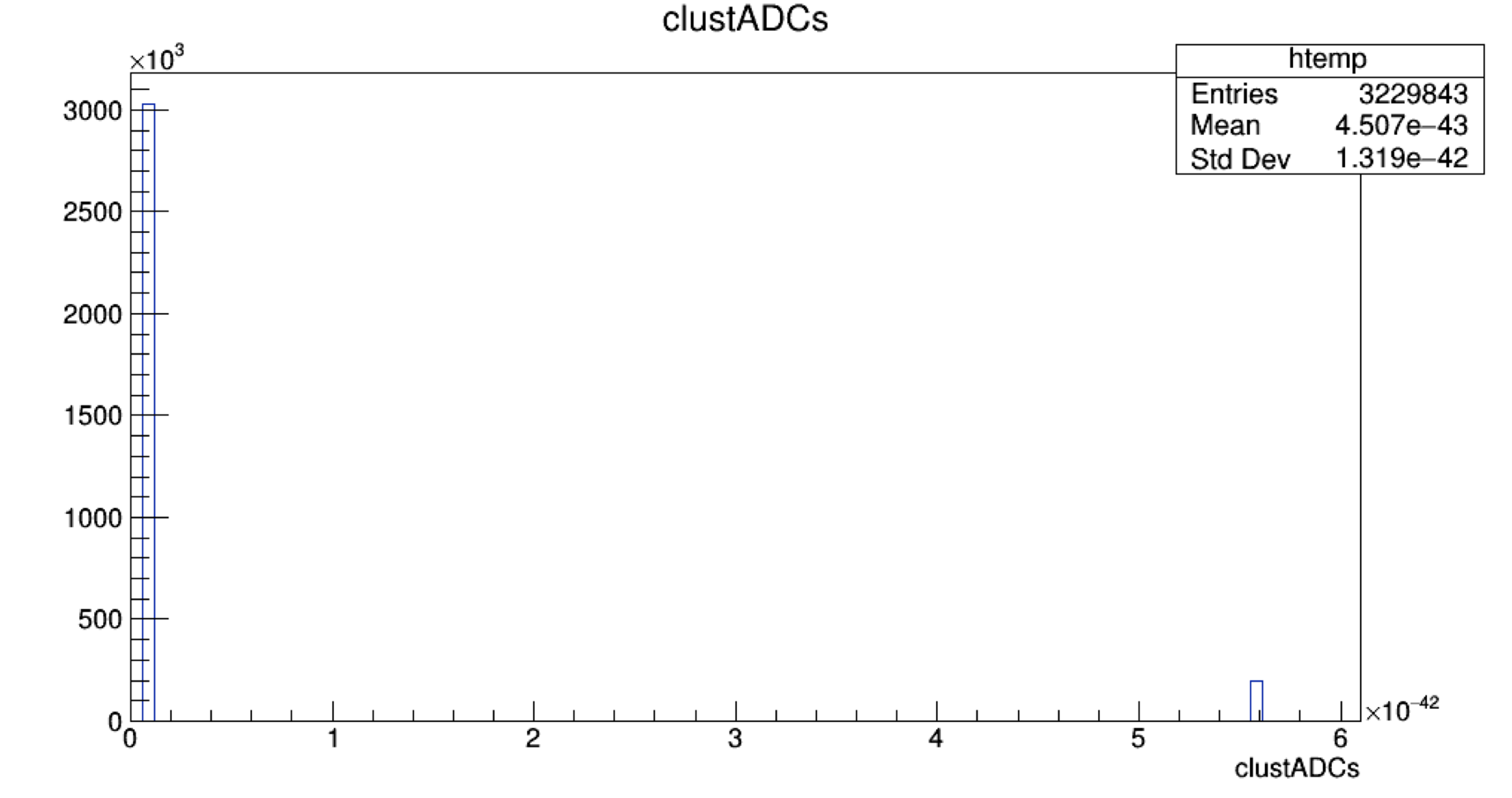
I’m not sure if I stumbled upon a bug, but when attempting to create a branch on an existing tree and then fill that branch with data, something strange happens to the data that is written to the root file. For example, the stat box on a histogram for the original data is:
Entries: 3229843
Mean: 2001
Std Dev: 1914
while the data written to the leaf produces a histogram with the following stats:
Entries: 3229843
Mean: 4.507e-43
Std Dev: 1.319e-42
file_out = TFile.Open("/path/to/file.root", 'update')
tree1 = file_out.Get("TCluster") #get TCluster tree
#puts data stored in a list of lists back into original ordering
clustMod_orig = sorted(clust, key = lambda x: (x[3]))
#declare a 1D array to be used as a pointer
clustADCs = array('f', [0])
#Create branch to be written
branch = tree1.Branch("clustADCs", clustADCs, 'clustADCs[nclust]/F')
for ii in range(0,nev):
clustADCs[0] = clustMod_orig[ii][2]
branch.Fill()
file_out.Write("", TFile.kOverwrite)
file_out.Close()
I have also tried printing the data as it is filling the branch in this loop, and the correct numbers are being assigned to clustADCs[0]. When filling an empty array with the data, the correct data is also stored, so I am not sure why the branch is not filling properly. Does anyone know why this is occurring?
ROOT Version: 6.14/00 Platform: MacOS High Sierra, v.10.13.4 Compiler: gcc version 5.1.0
Thank you for the help! This has seemed to fix the issue. After processing the data, however, there are values from the histogram that are missing. I realized that the number of entries in the tree do not correspond to the number of entries in the clustADCs leaf of the tree. For instance, while there are 199977 entries in the evtID leaf, there are 3358152 entries in the clustADCs leaf, which should be the proper number to run the loop over. I have been searching but cannot find a way to get the number of entries from a leaf object so that the loop will run over the proper number of entries. Any advice on this would be greatly appreciated!
Ultimately the purpose of this program (only a snippet was provided in the original post) is to extract data from another root file, modify the contents of the clustADCs leaf and then write that data to a cloned root file without the original clustADCs leaf. At the beginning of the program, the original file is opened and the command nev = tree.GetEntries() returns the number of events (199977), which I presume is from the evtID leaf in that tree. However, the number of entries stored in the clustADCs leaf in the original file is 3358152, which would be the proper number of entries to loop over. Is there a way to retrieve the number of entries in the original leaf?
The result of tree.GetEntries() does not correspond to any leaf, it is the number of entries of the tree. All the branches/leaves in a tree have the same number of entries, which is the value returned by tree.GetEntries(), in your case 199977, I understand.
What can happen is what is described in this other post:
If a branch is a variable sized array and you plot a histogram of that branch, the number of entries in the histogram can be different from the number of entries in the tree, but these are two different things. How do you obtain 3358152? Is it what you see in the histogram plot for the clustADCs branch?
import ROOT
from ROOT import TTree
file = TFile('myFile.root')
tree = file.TCluster
entries = 0
clustEntries = 0
for entry in tree:
entries += 1
for jj in entry.clustADCs:
clustEntries += 1
And then return the values for each, I get entries = 199978 and clustEntries = 3358152. The value of clustEntries matches the number of entries in the histogram. So this is an easy fix then: just run a loop that returns both the number of entries in the tree and the leaf of interest. In order to extract the data I followed the tutorial at http://lcgapp.cern.ch/project/pi/Examples/PyAIDAProxy/examples/hippoDemo.html, but it appears that this link is no longer working. The code is very similar to the code reproduced in this post: Reading Values using PyROOT, which was based on code at a similar link (http://lcgapp.cern.ch/project/pi/Examples/PyAIDAProxy/examples/readTree.py, which is also no longer working). From your previous comments, each event does contain a variable array with multiple entries, and the number of clusters for each event are specified in the nclust leaf in the tree. I have been looking for a solution but have found no simple way to run a loop to extract the array of values in the clustADCs branch when running the loop over the events. For instance, the .GetValue() function only returns the first element of the array stored for each event. Is there a way to simply extract the array with a function?
At every iteration, entry.clustADCs is your array of values for that entry. Also, at every iteration, entry.clustADCs is refilled with new values. So if by extracting the array you mean saving its values somewhere, you can do something like this:
import ROOT
from ROOT import TTree
file = TFile('myFile.root')
tree = file.TCluster
entries = 0
clustEntries = 0
for entry in tree:
mylist = []
for val in entry.clustADCs:
mylist.append(val)
# Here mylist contains all the values of your array
Or you could use an array.array or numpy array instead, whatever you like, to do the copy before the next iteration replaces the previous values.
Thank you! I was able to extract these values with no problem. However, there is now an issue with writing these values to the tree. Since this is a variable array that needs to be written, I have tried using the following code, which extracts the number of clusters (to be used as the range for the nested for loop when looping over all of the entries in the tree) and then attempts to pass zeroes to the variable clustADCs declared in the branch, and then write them to the tree (to see if this produces the expected output of a histogram with ~3 million entries with zero):
file_out = TFile.Open("myfile.root", 'update')
tree = file_out.Get("TCluster")
branch = tree.Branch("clustADCs", clustADCs, 'clustADCs[nclust]/F')
#Extract values in nclust leaf
nclust = []
for entry in tree.nclust:
nclust.append(entry)
index = []
for jj in range(0,199977):
index = nclust[jj]
print(index)
for bb in range(0,index):
clustADCs[0] = 0
branch.Fill()
file_out.Write("", TFile.kOverwrite)
file_out.Close()
There is an issue with the nclust branch. I have tried many different ways to write this loop, but I can only get it to work using the method at Reading Values using PyROOT. When running the loop to get the value of nclust, I receive the following error: TypeError: 'int' object is not iterable. However, if the other method is used and the nclust values are extracted, I can run the code:
for jj in range(0,199977):
index = nclust[jj]
print(index)
for bb in range(0,int(index)):
clustADCs[0] = 0
branch.Fill()
where nclust is an array of floats cast to integers using nclust = numpy.array(nclustValues, dtype = int). When checking to see if the data were successfully written, a histogram with a mean of ~10^30 is produced which is certainly incorrect. Do you have any ideas or suggestions on how to correct this?
That does in fact work to retrieve the integer values and it does return the proper length. I think I understand now why the previous loop did not work. That’s correct; I want to create a branch clustADCs of type float array whose size for every entry is in the nclust_list, and will be filled with the modified data from the original file.
In your case the branch will be linked to an array. You can declare an array.array variable in Python with a size that should be greater or equal than the maximum of nclust.
I have followed those instructions, using the array module method to declare the nclust array:
nclust = array('i')
for i in range(maxClust):
nclust.append(0)
and unfortunately I cannot get the branch to fill correctly. So far I have the following code, which attempts to create the variable-length array for each “event,” then write that to the tree using clustADCs[0] as a pointer and then the branch.Fill() method. I am trying to fill with just zeros first to see if I can reproduce a histogram with zero mean and zero standard deviation before writing any actual data to the branch. Below is the code:
for entry in tree:
nclustValues.append(entry.nclust)
events += 1
maxClust = max(nclustValues)
nclust = np.zeros(maxClust, dtype = int)
clustADCs = array('f',[0])
branch = tree.Branch("clustADCs", clustADCs, 'clustADCs[nclust]/F')
for jj in range(0,events):
index = nclustValues[jj]
temparray = []
for bb in range(0,index):
temparray.append(0)
clustADCs[0] = temparray
branch.Fill()
I am receiving the following error: TypeError: a float is required for the line clustADCs[0] = temparray, which is strange because even after declaring temparray = array('f', [0]) this same error occurs. Further, I have also tried passing a list of floats to the only element of clustADCs and this works just fine.
Is there a subtlety that I am missing when filling this branch? Any suggestions are greatly appreciated.
In your example, the array that has the right size to host the content that will be written is the numpy array, nclust. Note how clustADCs has size 1, and not max(nclustValues). Therefore, you need to do:
I am filling the branch as suggested, using the following code:
nclust = array('f',[0])
for i in range(maxClust):
nclust.append(0)
branch = tree.Branch("clustADCs", nclust, 'clustADCs[nclust]/F')
for jj in range(0,events):
index = nclustValues[jj]
for aa in range(0,index):
print clust[jj][aa]
nclust[aa] = clust[jj][aa]
print nclust[aa]
branch.Fill()
file_out.Write("", TFile.kOverwrite)
file_out.Close()
Using the print statements in the loop, I can verify that the correct data is being pulled from clust[jj][aa] and is correctly being assigned to nclust[aa], but the branch is not being written correctly for some reason. Is there something I am missing with this loop?