Dear TMVA experts,
I’m using TMVA for a signal/background classification problem. In particular, I’m using several trees with signal samples and a single tree with background samples (drell-yan).
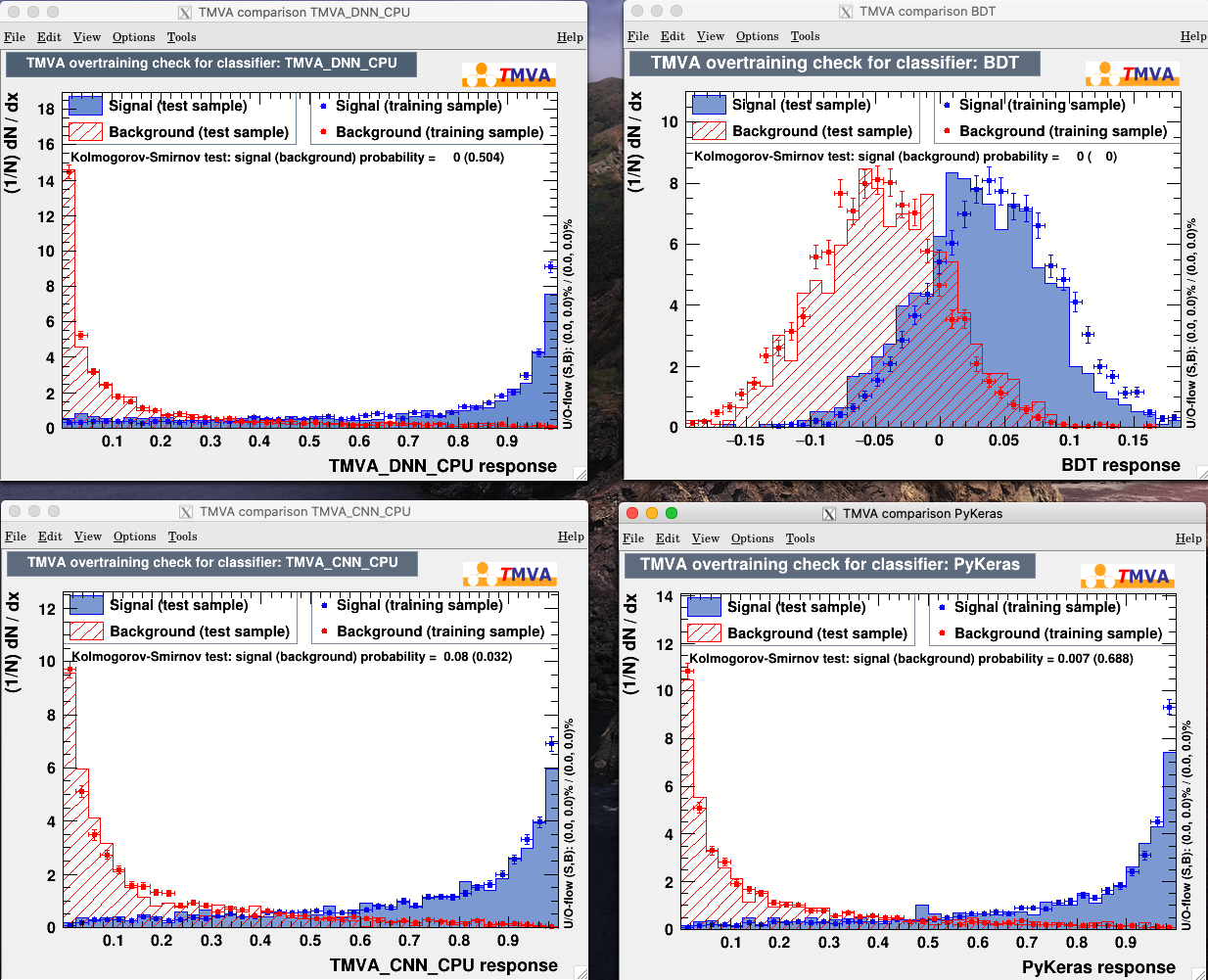
In the classification macro, I try different methods for training:
- PyKeras (with a python script that defines the model architecture)
- BDTs
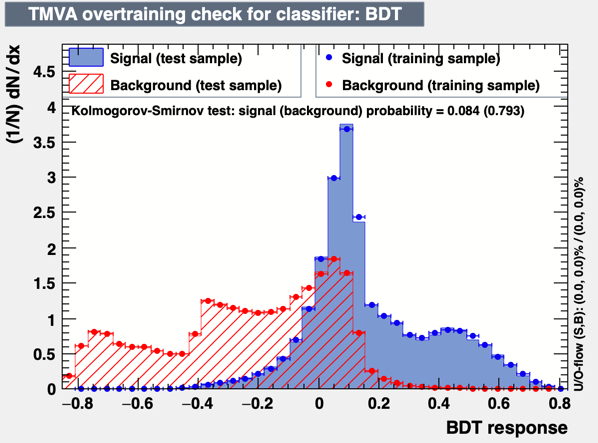
Using the BDT approach, I see something like that:
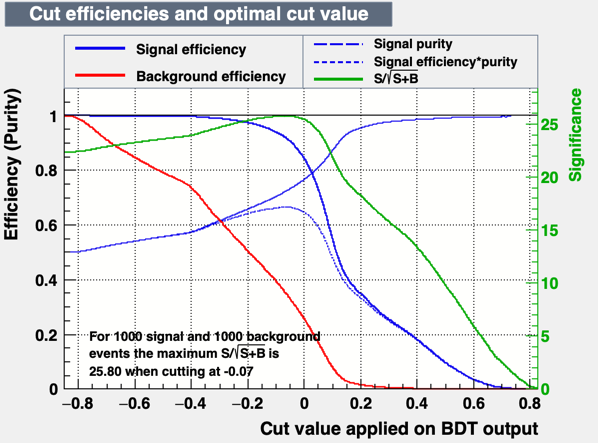
The code for the BDT option is:
factory.BookMethod(dataloader, TMVA.Types.kBDT, "BDT",
"!H:!V:NTrees=1000:MinNodeSize=2.5%:MaxDepth=6:BoostType=AdaBoost:AdaBoostBeta=0.3:UseBaggedBoost:BaggedSampleFraction=0.3:SeparationType=GiniIndex:nCuts=20:VarTransform=D+N" )
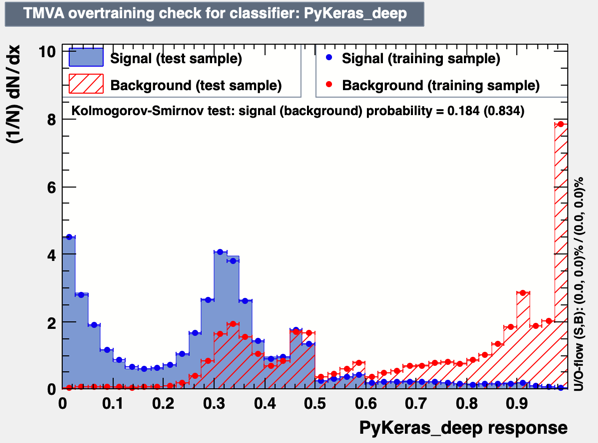
When I use the PyKeras code, instead, I see something like:
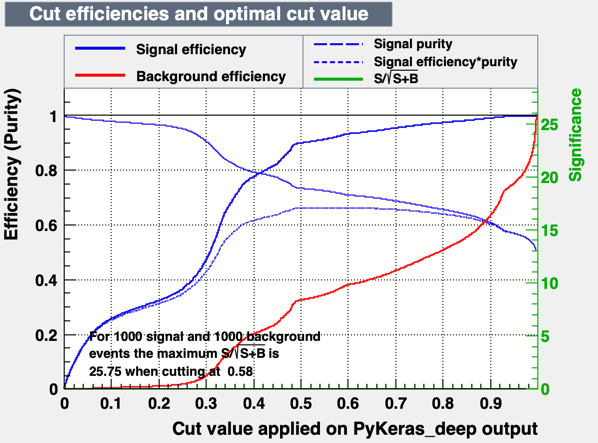
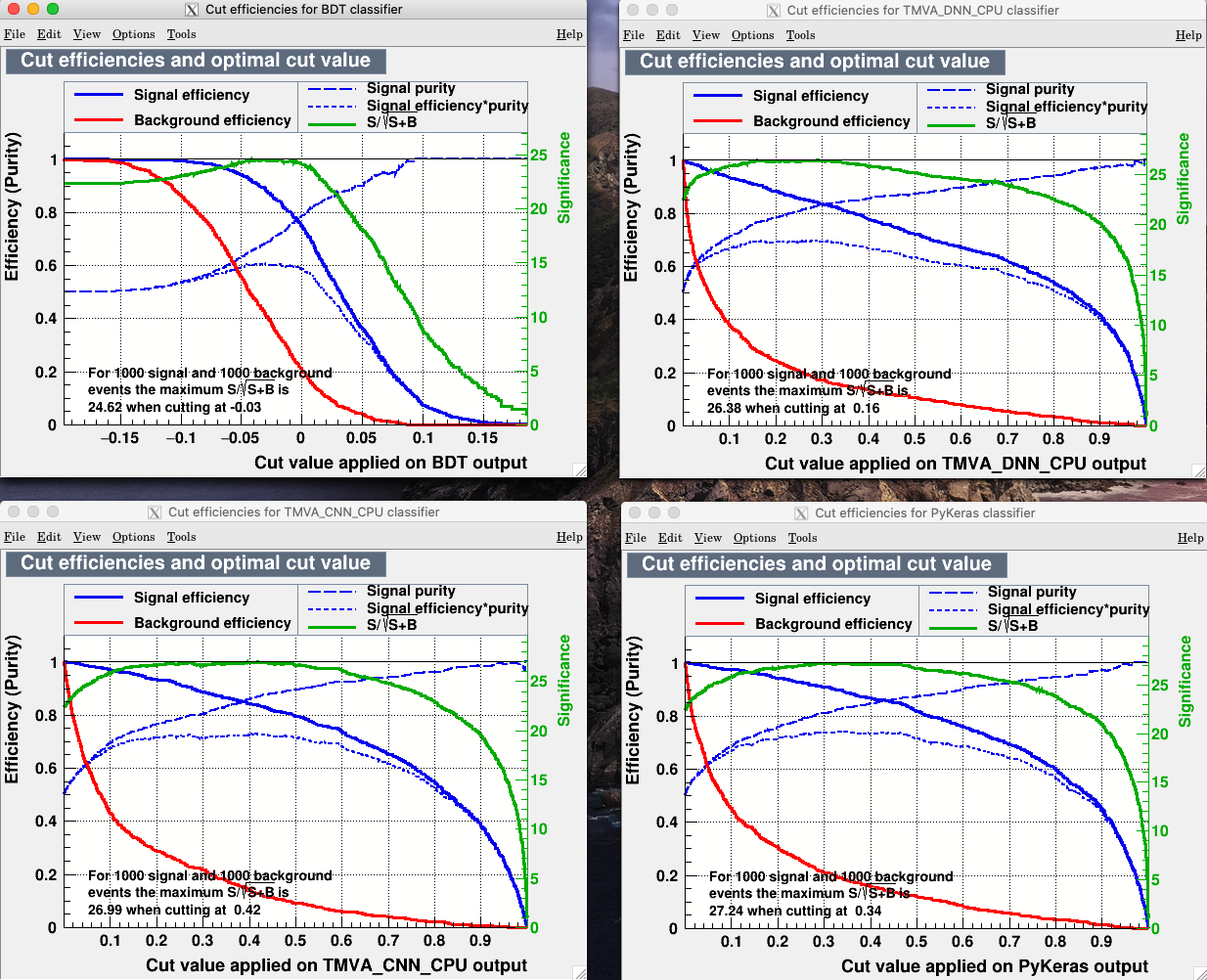
From this plot, I don’t understand why the green line is stuck at 0 (not showing) and why the blue and red line start at zero. In the BDT plot, instead, with no cut, the efficiency is 1 which makes more sense to me.
The code where the network is defined is:
factory.BookMethod(dataloader, TMVA.Types.kPyKeras, 'PyKeras_deep', 'VarTransform=N:FilenameModel=model_deep.h5:UserCode=metrics.py:NumEpochs=10#:BatchSize=500')
and the Keras architecture is quite straightforward:
model=Sequential()
model.add(Dense(150, input_dim=13, kernel_initializer='random_normal', activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(100, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(100, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(70, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(70, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(50, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(50, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(20, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(20, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(10, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(10, activation='relu'))
model.add(Dropout(rate=0.1))
model.add(Dense(2, activation='sigmoid'))
# Set loss function and optimizer algorithm
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001), metrics = ['accuracy', precision, recall])
model.save('model_deep.h5')
To run this code, I use ROOT 6.23/01 built from source in my lxplus account with a version of TMVA slightly changed to add also other metrics (precision and recall).
In your opinion, is this a problem in PyKeras or the issue is in the Neural Network approach by itself?
Best,
Tommaso
PS: You can find the data and the macros in https://cernbox.cern.ch/index.php/s/EvdftAa3FK6F17Q