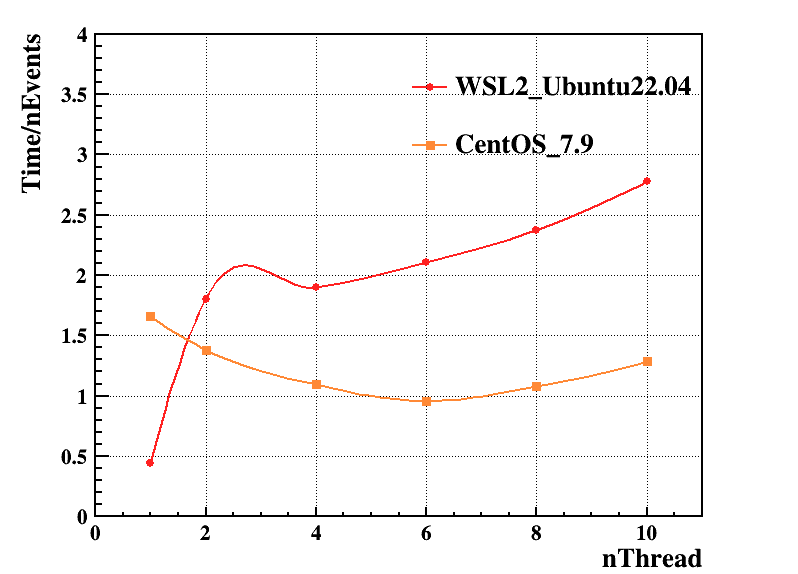
Dear Garfield++ experts:
I am trying to speed up my simulation by using the OpenMP. In the code below, I built my detector model in Comsol software, then imported the field maps to Garfiled++ and simulated the electron drift using the class AvalancheMicroscopic.
Some Garfield++ objects were defined as arrays of pointers for each thread. However, The results of multi-threading and single-threading simulations were consistent, but the former was much slower. Race conditions seemed happened between different threads.
Is there an issue with either my code or the ComponentComsol class in Garfield++? And how can I solve the issue?
Here is part of my code:
// Initial ComponentComsol Obj
ComponentComsol* fm = new ComponentComsol();
fm->Initialise(fileMesh.c_str(), fileDielectrics.c_str(), fileField.c_str(), "mm");
fm->SetMagneticField(0.,0.,0.);
if( Debug ) fm->PrintRange();
const unsigned int nMaterials = fm->GetNumberOfMaterials();
for (unsigned int i = 0; i < nMaterials; ++i)
{
const double eps = fm->GetPermittivity(i);
if (eps == 1.)
fm->SetMedium(i, &gas); // for Gas Medium ,eps=1. copper set to 1e10
}
//Set up avalanche and sensor for each thread:
Sensor **sensor=new Sensor*[nThreads];
AvalancheMicroscopic **driftelectron=new AvalancheMicroscopic*[nThreads];
std::vector<TRandom3*> vRnd;
vRnd.resize(nThreads);
for(int iThread=0;iThread<nThreads;++iThread)
{
//Random Engine
vRnd[iThread] = new TRandom3(0);
//Sensor
sensor[iThread]=new Sensor();
sensor[iThread]->AddComponent(fm);
sensor[iThread]->SetArea(-Radius-4, -Radius-4,0,Radius+4,Radius+4,Zmax);
//aval
driftelectron[iThread]=new AvalancheMicroscopic();
driftelectron[iThread]->SetSensor(sensor[iThread]);
driftelectron[iThread]->EnableMagneticField();
driftelectron[iThread]->SetCollisionSteps(100);
}
// Create ROOT file
TFile *file = new TFile("DriftLine_e_MP.root", "RECREATE");
// Creat TTree
TTree *tte = new TTree("tte", "DriftVelocity");
tte->Branch("velocity", &velocity, "velocity/D");
tte->Branch("x0", &x0, "x0/D");
tte->Branch("y0", &y0, "y0/D");
tte->Branch("z0", &z0, "z0/D");
tte->Branch("x1", &x1, "x1/D");
tte->Branch("y1", &y1, "y1/D");
tte->Branch("z1", &z1, "z1/D");
tte->Branch("status", &status, "status/I");
tte->Branch("threadid",&threadid,"threadid/I");
tte->Branch("t1", &t1, "t1/D");
omp_set_num_threads(nThreads);
#pragma omp parallel for
for (int i = 0; i < nEvents; ++i)
{
omp_set_lock(&writelock);
int thread_num = omp_get_thread_num();
if (i % 200 == 0)
std::cout << "----WT" << thread_num << ">: " << i << "/" << nEvents << " || " << std::endl;
omp_unset_lock(&writelock);
int statusmt(0);
double xx0(0.), yy0(0.), zz0(0.), tt0(0.), ee0(0.), velocitymt(0.);
double xx1(0.), yy1(0.), zz1(0.), tt1(0.), ee1(0.);
xx0 = vRnd[thread_num]->Uniform(-15, 15);
// xx0 = rnd.Uniform(-15, 15);
yy0 = 0., zz0 = posZ, tt0 = 0;
driftelectron[thread_num]->DriftElectron(xx0, yy0, zz0, tt0, ee0);
driftelectron[thread_num]->GetElectronEndpoint(0, xx0, yy0, zz0, tt0, ee0, xx1, yy1, zz1, tt1, ee1, statusmt);
if ((tt1 - tt0) != 0)
velocitymt = 1e9 * TMath::Abs(zz0 - zz1) / (tt1 - tt0); // Unit [cm/s]
else
velocitymt = 0;
#pragma omp critical
{
x0 = xx0;
y0 = yy0;
z0 = zz0;
x1 = xx1;
y1 = yy1;
z1 = zz1;
velocity = velocitymt;
status = statusmt;
threadid = thread_num;
t1 = tt1;
tte->Fill();
}
omp_destroy_lock(&writelock);
}
tte->Write();
file->Close();
Lansx.