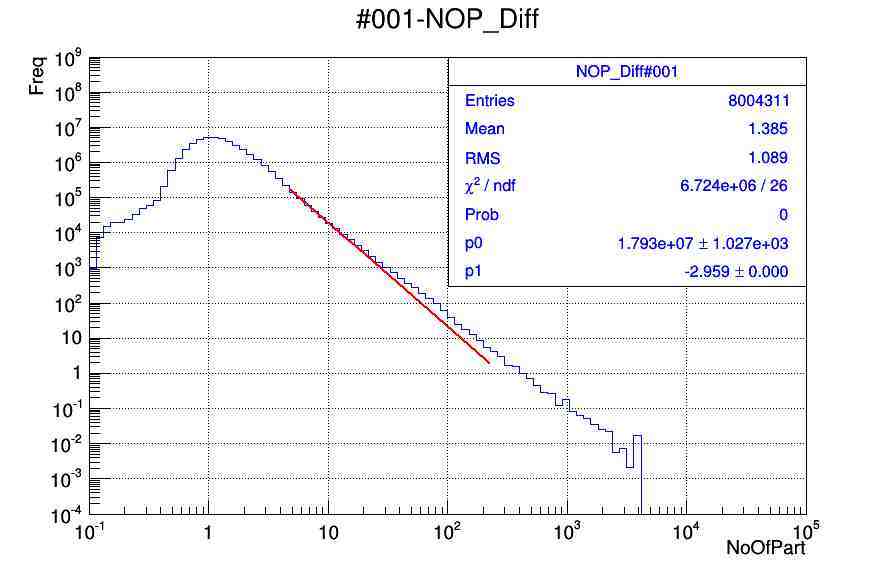
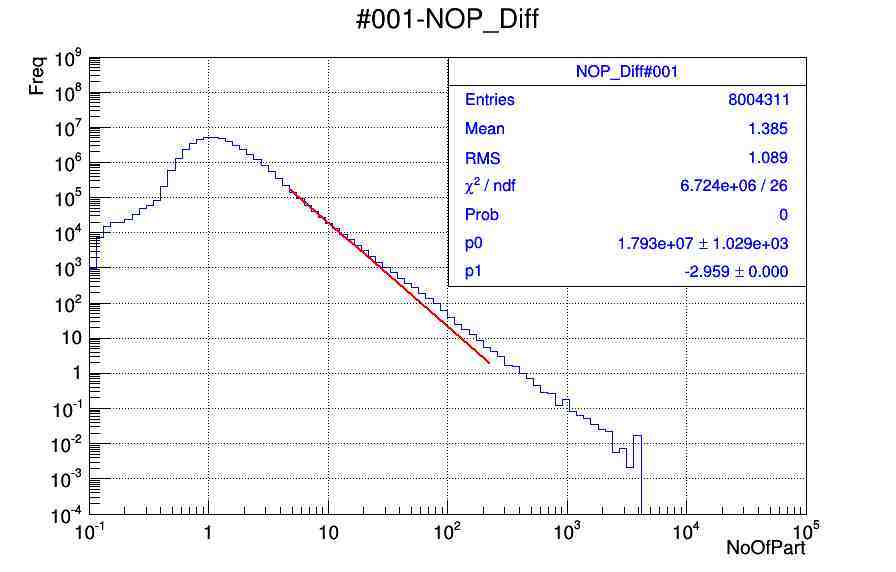
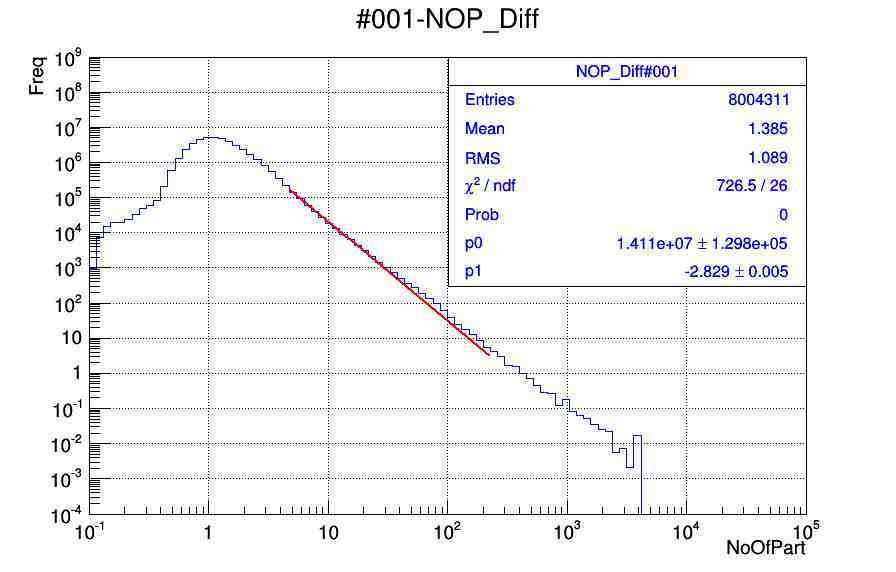
After doing so I am getting the fittings for some histos and for some I don’t get. Can anyone please help me to use the correct way of fitting the histograms with power law function. I am not clear with chi2/ndf calculations, I mean how to judge the values are correct or fitting is correct. I am attaching the .pdf and .root files of plots.
Are the fits failing (fit error) or not invoked (logic / code flow error)?
Fits can fail if the data doesn’t match the fit function. You’re not initializing your fit function’s parameters - that would probably be a good start.
I don’t know what your Det[i] does. That could also be a source of missing fits.
No idea what that’s supposed to do - is that another way of saying TH1::AddDirectory(false)?
Regarding chi2/NDF, please look at your favorite statistics book. You should have learned that at school / university…
There is no any fit error shown or not invoked (logic / code flow error) popped up.
What you have suggested about initializing the parameter, I tried with the same and not fitting problem got solved.
[Det[i]] is the Array index for detector Id.
I clicked at the same link and as you mention it took me to the instructions what you also have mentions. Infact,
that webpage is helpful quite a bit but I was confused and getting not expected fit. Actually in principle if weight free method is used so then fit should not deviated much from the actual data set.
That’s the kind of fit I’d expect. You’re doing a log scale, thus the deviation for the bins with low count is more visible than that for the bins with lots of content.
It looks as if the curve is not just an exponential.
Please correct if my understanding is wrong, What are you trying to say that the problem of deviation is more because of less statistics at higher number of particles and deviation is less at lower bins because of high statistics.
This thing I can understand with normal method but in case of WW and W fitting how the statistics of bin is taking part into the calculations(How the theoretical value is being calculated).