Hi all,
I would like to share my experience with Proof & Storage so far, it may help others and lead to interesting discussions.
This is a viability test for some store options in our Tier3. The hardware used for this purpose was:
* 1 Worker: Double intel quad-core node with single SATA disk and Gigabit network,
* 1 Master: Single P4-3Ghz with one sata disk and Gigabit network.
* 2 dCache Pools: double dual-core with 3ware 9650se + 13 RAID6 * 500GB data disks and Gigabit network.
* Production Storage Element with very low usage.
The Proof analysis test job examines a 42-file .root dataset with 10000 events/each.
[size=150]Samples[/size]
There are four different tests, and each uses a different access method (two local and two remote)
-
Remote with dcache, addresses in the shape of dcap://dcapdoor/pnfs/site.es/…. One of the samples is using the protocol as-it-comes (native) and the other samples come from a “tuned” dcap protocol using the read-ahead and a bigger buffer with this environment variables: DCACHE_RAHEAD=TRUE and DCACHE_RA_BUFFER=128000
-
Local, with addresses like root://hepdc1/proofpool/files/pnfs/site.es/…. That are translated to local access. There’s as well to kind of samples, one with new data (not cached) and the other with data recently read before (cached). The dataset is small enough to fit in memory.
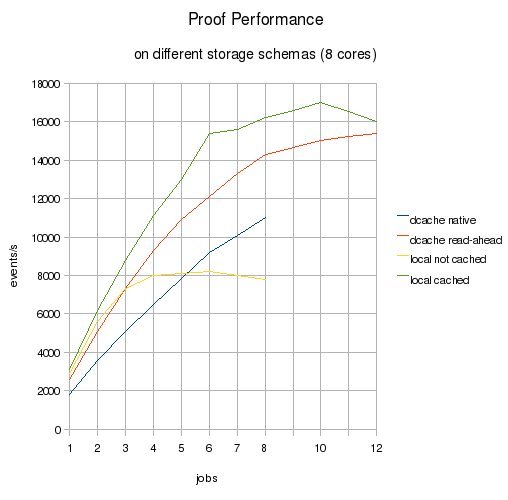
You can see the performance evolution (events/s) in the attached graph. Please take a look at it before reading further.

[size=150]Comments[/size]
There’s almost no difference between reading the data remotely the first time (uncached in the pools) and reading it the second time (cached). The pools are really fast.
Activating read-ahead in dcache is “free” and transparent to the user, so using dcache-native makes no practical sense.
The local-cached sample does not seem to be very realistic either. There’s usually not much free memory to cache files, and a single dataset can be much larger. Maybe a single user executing the same job one and more times could make partial use of the system cache.
The local-uncached sample looses performance very quickly (below remote), because data is store in a single sata disk. This loss can be partially avoided using some kind of hardware RAID, changing the fstype to xfs and the block-size.
In either local-cached and local-uncached, the data has been previously staged in. This time is not shown in the graph.
The performance impact against the Storage Element in the remote reads is minimal.
You can run more jobs than the number of cores and still get some performance boost (up to 1.5 times the number of cores). This is due to the wait time in remote transfers.
Best candidates, local-cached and dcache-readahead, almost touch at 12 jobs. The reason is that the biggest problem with remote transfer is the iowait, but if you launch more jobs than cores, one job will be executing while the other waits for it’s file. It does not reach the best possible performance (local-cached) but, after all, the difference is very small and local-cached is not very realistic.
[size=150]Conclussions[/size]
After all this tests, the impressions left in our environment are that remote accesses are very close to local ones, and scale better. Taking into account:
* The cost of filling the workers with redundant disks to lower the local-uncached decay
* Having the local data cached in memory is unlikely to happen
* There is a stage-in time in the local-* samples not show, and it's high compared to the analysis time.
* There is also a much higher administrator effort to build the stage-in system and keep the local and remote data consistent.
Our conclussion is to avoid local data and work remotely.