Hello!
I’ve been looking into TMVA alongside some of the less HEP specific multivariate analysis tools (primarily using BDT’s like AdaBoost and gradient boosting such as XGBoost). In the wider non-HEP sense whenever overtraining/overfitting is discussed it is usually in the context of learning curves (e.g see, performance as a function of number of trees in XBGoost)
,

where over-training is said to be occurring when the performance on the test sample starts to get worse, despite the performance on the training sample improving. So in the above example above 30 Trees, we would say we are over training. At about 5 Trees the performance of test and train are very similar, but as the performance is improving for both so we are undertraining, i.e more training will improve both test and training performance.
However, in TMVA and HEP in general, overtraining is mainly used to describe any difference between test and training performance at all, with plots such as
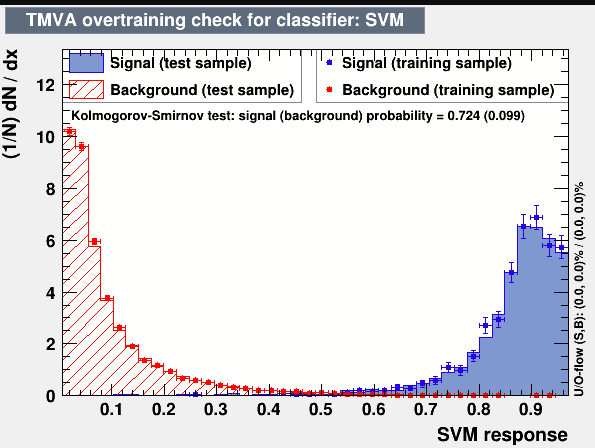
being used to judge this being very common. However, this doesn’t seem to be common at all outside of HEP, where I struggled to find a single example of such practice that wasn’t TMVA. Similarly, in the wider community differences between the training/test performance (as measured by the absolute difference between the two lines in a learning curve for example) is more commonplace, so long as the performance on the independent test sample is well behaved (usually by studying learning curves or cross-validation), and the performance on the training samples are generally considered a poor metric of performance and aren’t used.
In a recent talk on modern TMVA by Stefan Wunsch seemed to suggest that this is a HEP thing but the context wasn’t 100% clear to me. Demanding that the test and train samples show similar shapes seems to me to be favoring under-training also. (https://indico.cern.ch/event/773049/contributions/3476171/attachments/1936050/3208338/CHEP_2019__Machine_Learning_with_ROOT_TMVA.pdf)

I guess I don’t have any particular questions, but just maybe to start some discussions about HEP specific trends/manners.
Best,
Mark
