ROOT Version: 6.30/02
Platform: CentOS7
Compiler: g++ 11.3.0
Hello everyone,
I have a more conventional question concerning RDataFrames. I am one of the developers of CROWN (GitHub - KIT-CMS/CROWN: C++ based ROOT Workflow for N-tuples (CROWN)) where we use a configuration, to automatically generate C++ Code that is then compiled. The heavy lifting is done using a single, large RDataFrame. Most functions in the framework are optimized and do not use any JITting.
Now, we are at a point, where one of our users is running a DF, that is hard to handle on our HTCondor system. This DF contains a large amount of defines and outputs, which result in a memory consumption of about 40GB when running with 4 threads
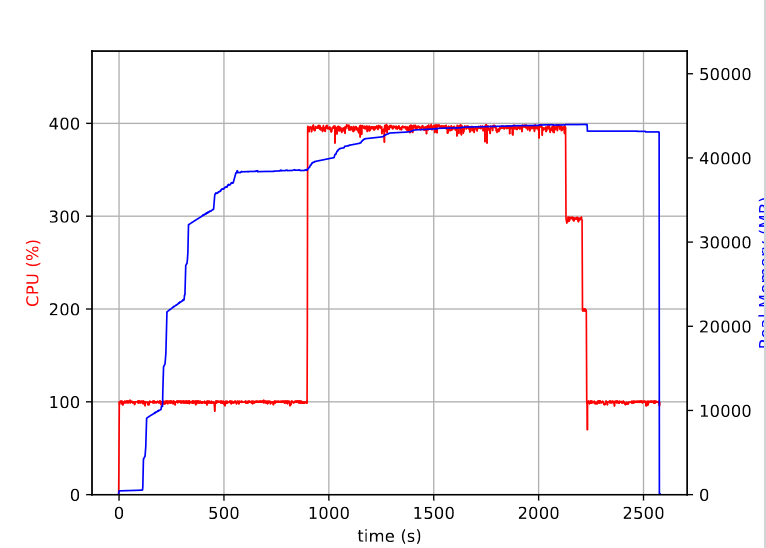
Total Number of Defines: 28620
Total Number of Outputs: 21778
I think it is very nice, that DF can handle something like this, however, the memory footprint is worrisome for large-scale productions of ntuples.
It is possible to split the task into multiple DFs by hand, but I was thinking about potential solutions on how to reduce this overall memory usage from the framework side, so the user does not have to optimize this on his side. One idea that I had was to split up the DF into multiple DFs that generate intermediate output files. This would cost a significant amount of performance since events have to be processed multiple times but would allow the overall task to succeed with less memory.
Are there any other solutions that you can think of, that might help to reduce the memory usage of such a DF? Are there even some built-in mechanisms that might help here?
Best Wishes
Sebastian
[1] The code of the main executable can be found here PrivateBin