In Allpix Squared we generate quite a few TRef objects over the course of a simulation run, often several thousand per event. We generate those TRefs to link objects between each other to preserve some history of that simulation and to store this MC truth information to a ROOT TTree. This is done in a multi-threaded environment with many threads writing to the same file. They share a lock to ensure sequential access, among other things.
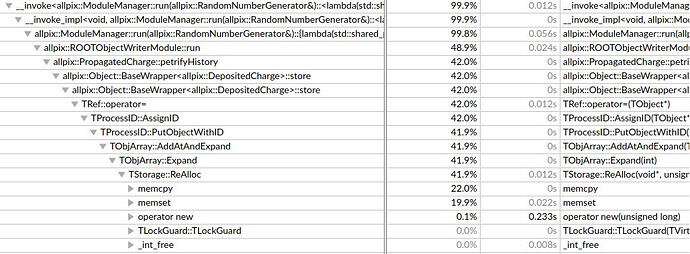
I observed that we are severely limited in performance by constant memory re-allocations, longer into the run (here a screenshot from Intel VTune profiling):
Following down that call stack I find that the TObjArray allocated by TProcessID is hardcoded to an initial length of 100 entries (see here for master) and every single subsequent addition of a TUUID will call for a re-allocation of the full table and an addition of yet another 100 slots.
As you see in the stack trace, this becomes very expensive quite quickly, in that range of the simulation (later into the run) reating up more than 40% of the total CPU cycles.
Is there any more efficient way to deal with this?
Are you using TProcessID::SetObjectCount()? See test/Event.cxx for an example. Without this call, TRefs can potentially reference cross-entry objects - but that means the table’s size is steadily growing. (Disclaimer: TRef is something we have learned a lot of lessons from…, and we will see how to do better with RNTuple!)
just run allpix and observe how the events are processed quickly at the beginning and then slow down considerably after a few hundred.
Essentially it is the code of two modules, both located at the bottom of src/core/module/Module.cpp, the DummyModule which produces objects with a relation, and the ROOTObjectWriter which generates the TRef relation and saves them to a TTree.
Thank you for the reproducer. I cannot but confirm your analysis above.
Overall, that program spends more than 70% of its time in TProcessID::AssignID, which is called by TRef::operator=, which is called by allpix::Object::BaseWrapper<allpix::PropagatedCharge>::store .
Looking at the first few seconds of the execution vs the last ones, there is definitely a huge difference in what % of the execution is taken by TProcessID::AssignID as well as in where AssignID itself spends time.
Maybe there was a better solution. To know whether this is the case, we would to go back to reproducing this mangling and understand why the object were crossing the event boundaries (i.e. for example maybe all the ‘previous’ event’s referenced object were deleted before reading/using the next one).
One of the question is “what is the intent of BaseWrapper?”, it seems that all object are being assigned to a TRef in order to be stored. (Since object can be stored without going through a TRef, I wonder if this is really the intent and/or a real need).
Hi all, thanks for all your input and also for reproducing my the stack!
Alright, I will try to dig out our documentation on the issue and try to reproduce it. I’ll let you know!
The intent of the BaseWrapper and PointerWrapper classes is exactly the opposite - it is meant to serve as a reference between objects. During runtime, this is a raw pointer, without ever generating a TRef. Only when an object is stored, the petrifyHistory method goes through all its raw pointer references to other objects and converts them to a TRefif (and only if) the related object will also be stored.
Essentially this means we’re only generating TRefs right before storage to file and only when necessary. This wrapper class is the reason why the TStorage::Realloc problem only really surfaced now, because one user has an unusual setup that requires an unusually high number of relations to be stored.
Just to add here: the locks are not really the problem - the example above is off course specifically designed to exaggerate the problem and does not do any work aside from the TRef generation. At least in regular stack traces I don’t see the locks taking up any sizeable fraction. We are raising a global ROOT lock anyway before writing to the tree as you might have seen at the top of ROOTObjectWriter::run().
I think I had an epiphany this morning, following your suggestions concerning TProcessID::SetObjectCount().
Staring at the patch that removed my object count reset back then when it was not working I realized there is a crucial ingredient that was not there at the time of attempting to use it:
At the time, our objects looked like this:
class MyObject : public TObject {
public:
MyObject(const OtherObject* other_object = nullptr)
: other_object_(other_object){};
private:
TRef other_object_{nullptr};
};
which essentially means that
All object relations where always created as TRef and stored in the TProcessID table
They were created directly with the object, meaning at different points in time on many different threads
This of course means that calling SetObjectCount() at a (random) point in time would completely mess up the reference table of all events currently processed on any thread - hence we removed it again.
We then ran into the issue of overlocking because of the many-threads-write operation into the TProcessID storage - and therefore developed the PointerWrapper which would not only defer the generation of TRefs to the single thread that also writes it to the ROOT file, but also gave us the option of not generating them for any object not stored in the file. So the object became:
Another food for thought. Are all those (new) objects actually needing a direct relation? Could it be replaced by an indirect relation, for example a container and an index? (Even if the resetting the count works, this might be an additional performance and file size gain).
I have a follow-up question. I looked back at our git history and we actually did have the above things already in at the time I removed the object count reset. So I am now trying to understand what the issue was.
One thing that I still don’t understand: Why don’t I have to call a similar reset of the object count when reading in the data? Don’t the TRefs read from file also generate these entries, and wouldn’t the counting go completely wrong when I read the next event, because when writing I had reset the counting before, but not when reading? At least I don’t see any precaution against this in your Event.cxx example.
Unfortunately yes. Unless there is really no way of scaling this I would really like to keep their direct relations.
That is because the count is used to assign unique id to new objects. When reading the ids are already assigned, so there is no count to reset (or more exactly it wouldn’t change anything). When using the reset count, it is assume that all the objects (that might have redundant/duplicated ids because of the reset count) are either deleted or re-used (possibly with new ids)
When accessing event 1, object 0 will I get the one from event 0 or 1?
That slightly depend. If the object from event 0 with ID 0 is still live a that time, it will indeed be retrieved. However it has been reused (to read in some other object from event 1) or deleted and the object with ID0 from event 1 has been read (and/or setup the auto-reading by call tree->BranchRef()) then it will be that object.
(no problem for the delay, I also come back to this problem only intermittently…)
Alright, so if I understand you correctly, the following two options are both fine:
I read and process data on a single thread. All data from event 0 will have been deleted when I read event 1, so no problem. (This is the use case for most of our users who will analyze their trees with some macro)
I read data on a single thread but later on process it on multiple threads. Here, I should essentially turn the TRef back into a raw pointer and set the TRef to a nullptr directly when reading in the data. Then there is no mixup between events since there are no centrally-accounted TRefs anymore.