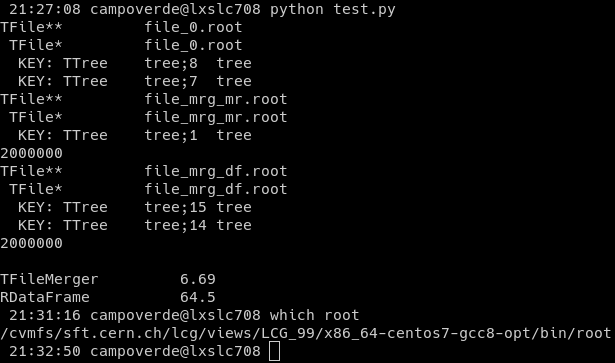
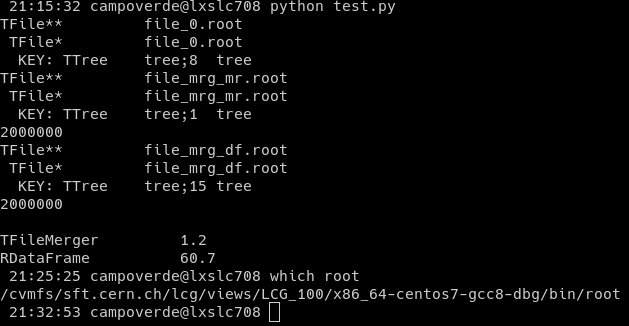
Hi,
I am having problems merging trees using RDataFrame. From the code below:
import ROOT
import shutil
import os
import timeit
#------------------------------------
def make_data(nentries):
filename='file_0.root'
if os.path.isfile(filename):
return
df = ROOT.RDataFrame(nentries)
for i_branch in range(30):
df = df.Define('a_{}'.format(i_branch), 'TRandom3 r(0); return r.Gaus(0, 1);')
df.Snapshot('tree', filename)
ifile=ROOT.TFile(filename)
ifile.ls()
ifile.Close()
shutil.copyfile(filename, 'file_1.root')
#------------------------------------
def merger_fm():
mrg=ROOT.TFileMerger(False)
mrg.SetFastMethod(True)
mrg.AddFile('file_0.root')
mrg.AddFile('file_1.root')
mrg.OutputFile('file_mrg_mr.root')
mrg.Merge()
ifile=ROOT.TFile('file_mrg_mr.root')
ifile.ls()
print(ifile.tree.GetEntries())
ifile.Close()
#------------------------------------
def merger_df():
l_file=['file_0.root', 'file_1.root']
df = ROOT.RDataFrame('tree', l_file)
df.Snapshot('tree', 'file_mrg_df.root')
ifile=ROOT.TFile('file_mrg_df.root')
ifile.ls()
print(ifile.tree.GetEntries())
ifile.Close()
#------------------------------------
make_data(1000000)
val_fm = timeit.timeit('merger_fm()', number=1, globals=locals())
val_df = timeit.timeit('merger_df()', number=1, globals=locals())
print('')
print('{0:<20}{1:<20.3}'.format('TFileMerger', val_fm))
print('{0:<20}{1:<20.3}'.format('RDataFrame' , val_df))
I see:
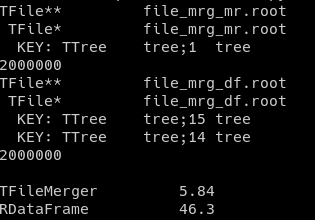
i.e., the approach with TFileMerger takes about 6 times less and produces only one cycle. Is there a way to:
- Speed this up.
- Remove all the cycles.
Although the cycles are supposed to not affect us, when I work with trees I usually do:
l_tree = []
l_key = ifile.GetListOfKeys()
for key in l_key:
obj = key.ReadObj()
if not obj.InheritsFrom('TTree'):
continue
l_tree.append(obj)
fun(l_tree)
which seems to put also the cycles as independent trees:
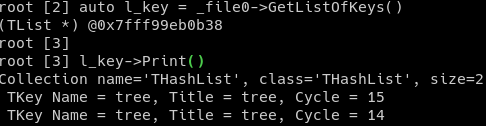
Cheers.
Please read tips for efficient and successful posting and posting code
_ROOT Version:6.22/06
_Platform: x86_64-centos7-gcc8-opt
_Compiler: gcc8-opt
Use LCG_99 with x86_64-centos7-gcc8-opt