Hi @pcanal ,
the compression ratio is as follows.
24TTree, 5e6 events, default AutoFlush:
******************************************************************************
*Tree :detector0 : G4 data for detector0 *
*Entries : 5000000 : Total = 1383278855 bytes File Size = 40326533 *
* : : Tree compression factor = 34.43 *
******************************************************************************
*Br 0 :Energy : Energy/D *
*Entries : 5000000 : Total Size= 40088615 bytes File Size = 323902 *
*Baskets : 901 : Basket Size= 3153408 bytes Compression= 123.71 *
*............................................................................*
*Br 33 :Volume : Volume/C *
*Entries : 5000000 : Total Size= 45154963 bytes File Size = 7609952 *
*Baskets : 1459 : Basket Size= 25600000 bytes Compression= 5.93 *
*............................................................................*
24TTree, 2e6 events, 5MB AutoFlush:
******************************************************************************
*Tree :detector0 : G4 data for detector0 *
*Entries : 2000000 : Total = 552571727 bytes File Size = 15071192 *
* : : Tree compression factor = 36.72 *
******************************************************************************
*Br 0 :Energy : Energy/D *
*Entries : 2000000 : Total Size= 16015507 bytes File Size = 104321 *
*Baskets : 155 : Basket Size= 3153408 bytes Compression= 153.49 *
*............................................................................*
*Br 33 :Volume : Volume/C *
*Entries : 2000000 : Total Size= 18026491 bytes File Size = 2978768 *
*Baskets : 247 : Basket Size= 8340480 bytes Compression= 6.05 *
*............................................................................*
1TTree, 1e8 events, 5MB AutoFlush:
******************************************************************************
*Tree :detector0 : G4 data for detector0 *
*Entries : 100000000 : Total = 27601605583 bytes File Size = 715748091 *
* : : Tree compression factor = 38.57 *
******************************************************************************
*Br 0 :Energy : Energy/D *
*Entries :100000000 : Total Size= 800047651 bytes File Size = 4323216 *
*Baskets : 483 : Basket Size= 3153408 bytes Compression= 185.06 *
*............................................................................*
*Br 1 :Energy : Energy/D *
*Entries :100000000 : Total Size= 800047651 bytes File Size = 4323216 *
*Baskets : 483 : Basket Size= 3153408 bytes Compression= 185.06 *
*............................................................................*
*Br 33 :Volume : Volume/C *
*Entries :100000000 : Total Size= 900043875 bytes File Size = 146492636 *
*Baskets : 411 : Basket Size= 8340480 bytes Compression= 6.14 *
*............................................................................*
I truncated the output, the values are almost the same for the branches with the same type and they are the almost same for each tree. Branches with different types have very different compression ratios.
If I now try to follow your calculation with those values, the default AutoFlush gives a compression factor of 34.43 multiplied with 32 MB = 1102 MB, i.e. for 24 trees it is 26 GB? The AutoFlush(5MB) gives 36.72 * 5MB = 184 MB for each of the 24 trees, i.e. in total 4.4 GB. For the 1 TTree case it’s 38.57 * 5MB = 193 MB. Is that right?
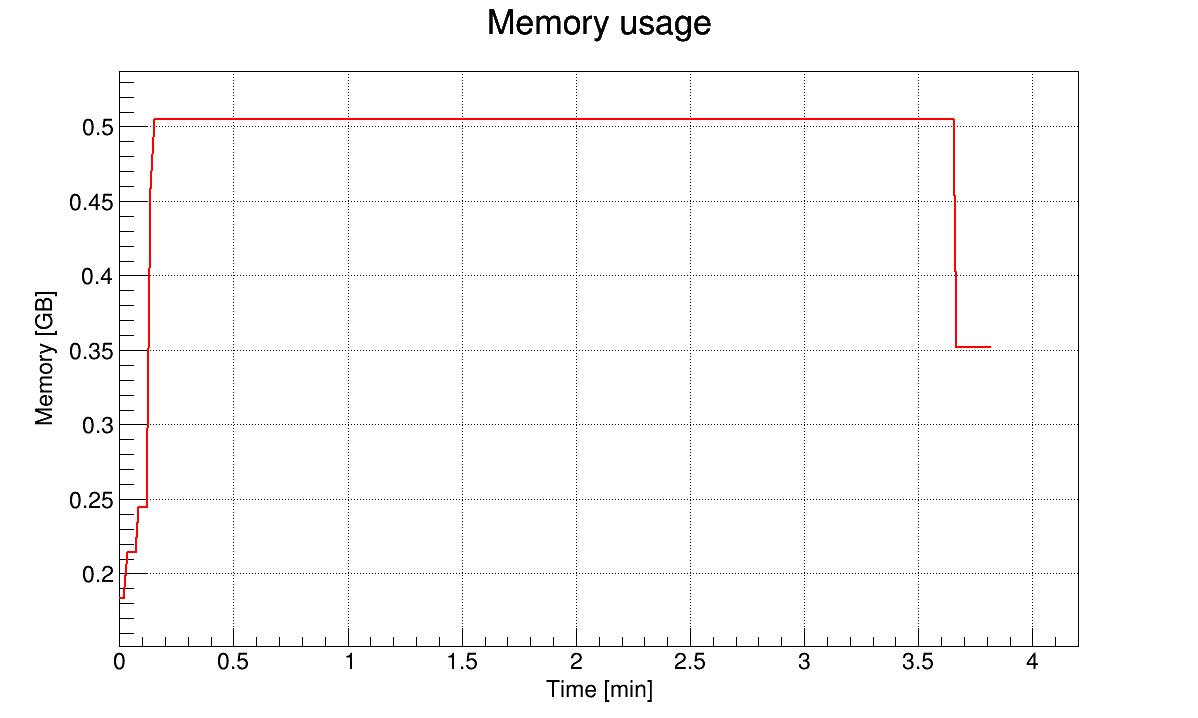
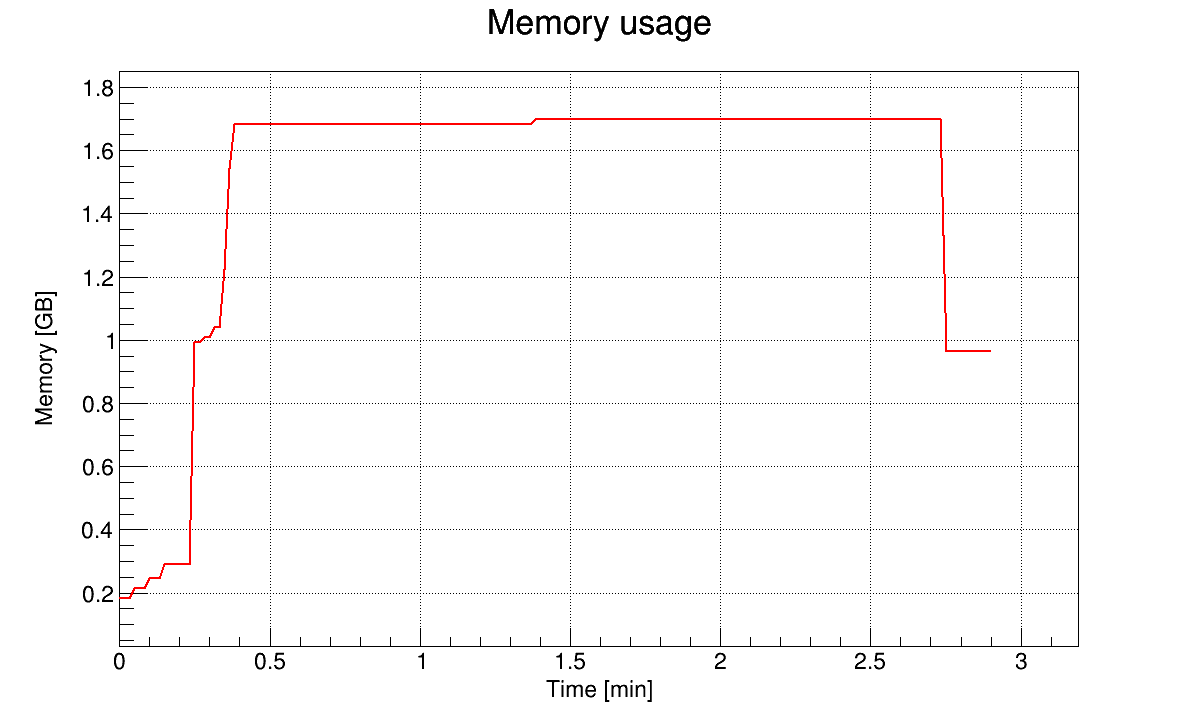
I’m unsure concerning your statement of the base memory per tree. To me it looks like the memory does not significantly increases when creating the tree. Before and after creating the 24 trees there is only an increase of something like 4 MB in res memory.
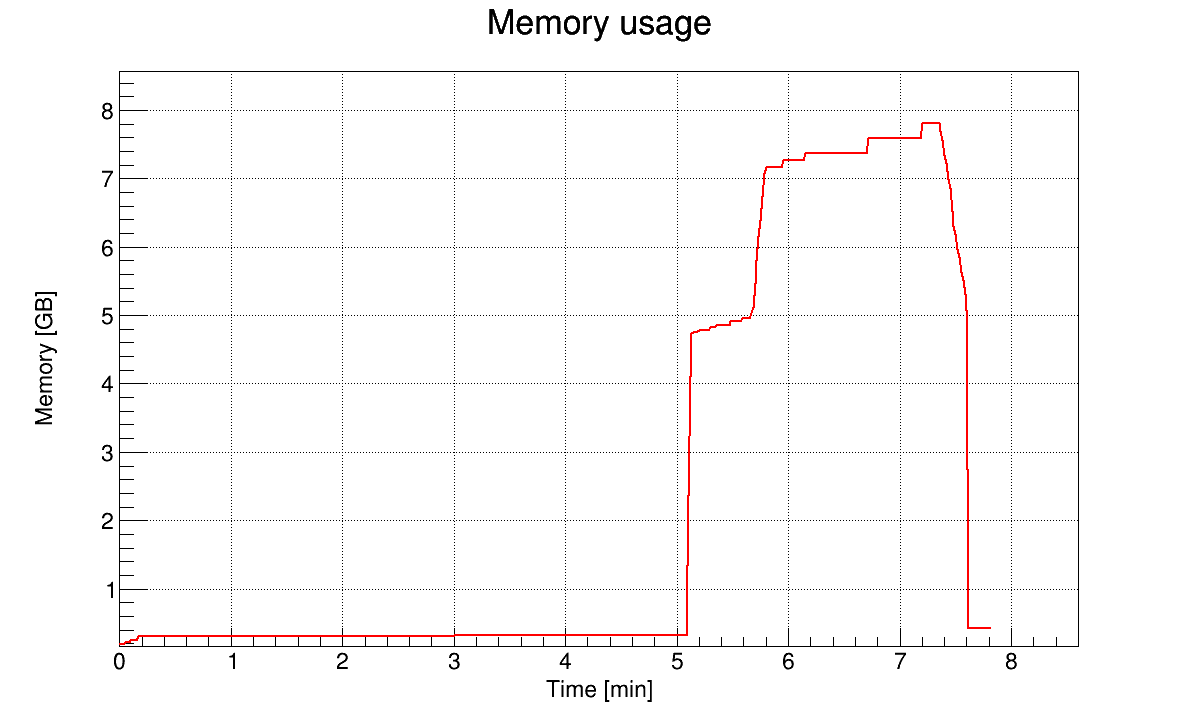
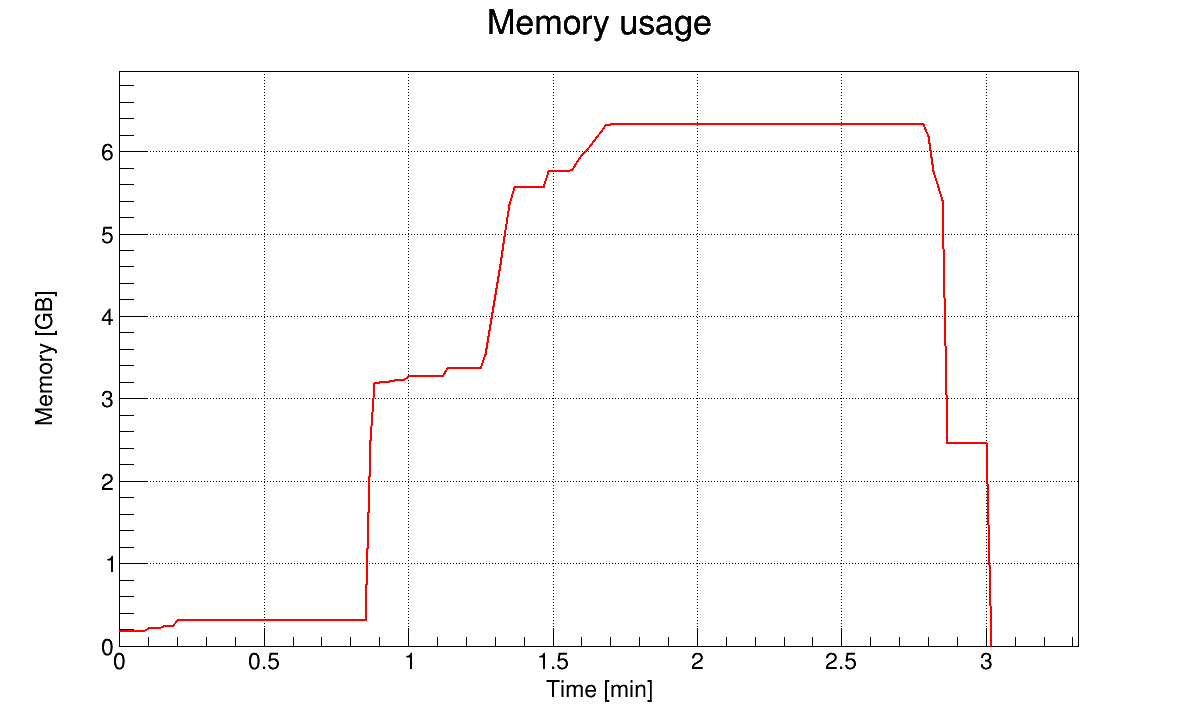
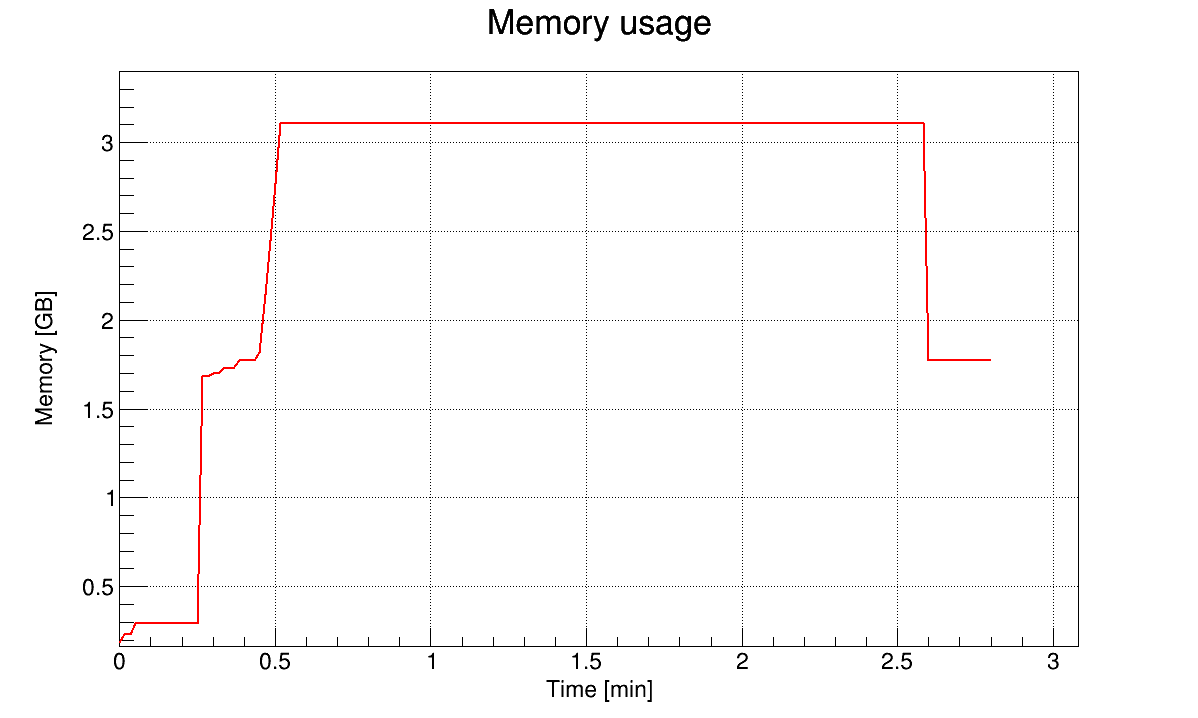
I also tried to use a different compression algorithm and compression level (ROOT::CompressionSettings(ROOT::kLZMA, 1)), which was consuming 1.5 GB of memory for a long time, but after 5e7 events it increased within seconds to 16 GB and the process was killed.
Indeed, for the simplification of this example I just created the branches in loops. The data written to the ROOT file looks as expected, the same number and the same string is stored as intended. In our Geant4 application those branches are not duplicated. The double type branch represents the branches for the x,y,z position, the energy deposition, the event number, etc. The char type branch represents the branches for the volume name, the particle name and the name of the physical process. There are only a few different names for those, which supports your suggestion concerning the high compression ratios.
The compression ratio in a real example from our Geant4 application e.g. for a detector tree it is 19.11 with the individual branches varying between 3 and 170. But we also storing other information in tree, such as the details of the primary particle, which has only a compression factor of 3.
I also had a look if the issue is happening when there are no branches of type char, i.e. all branches are of type double. After x events the memory jumps from 300 MB to 2.5 GB after 2.2M events and to 4.9 GB after 2.7M events when using the AutoFlush(5MB). So this doesn’t really help.
Concerning your question why having 24 TTrees is better, that was a historial choice and people don’t want to change it after using this scheme for many years.