I want to document a JIT performance issue.
(Solution at the end of the post.)
I compared the performance of JITed and compiled functors that are called from multiple threads.
Here the code snippet for the g++ compiled functor:
Thanks for your quick reply!
Unfortunately, the suggested change has no effect on the results with v6.20/02.
I also added the pragma before I define the functor and enabled R__CLING_PTRCHECK(off). [1]
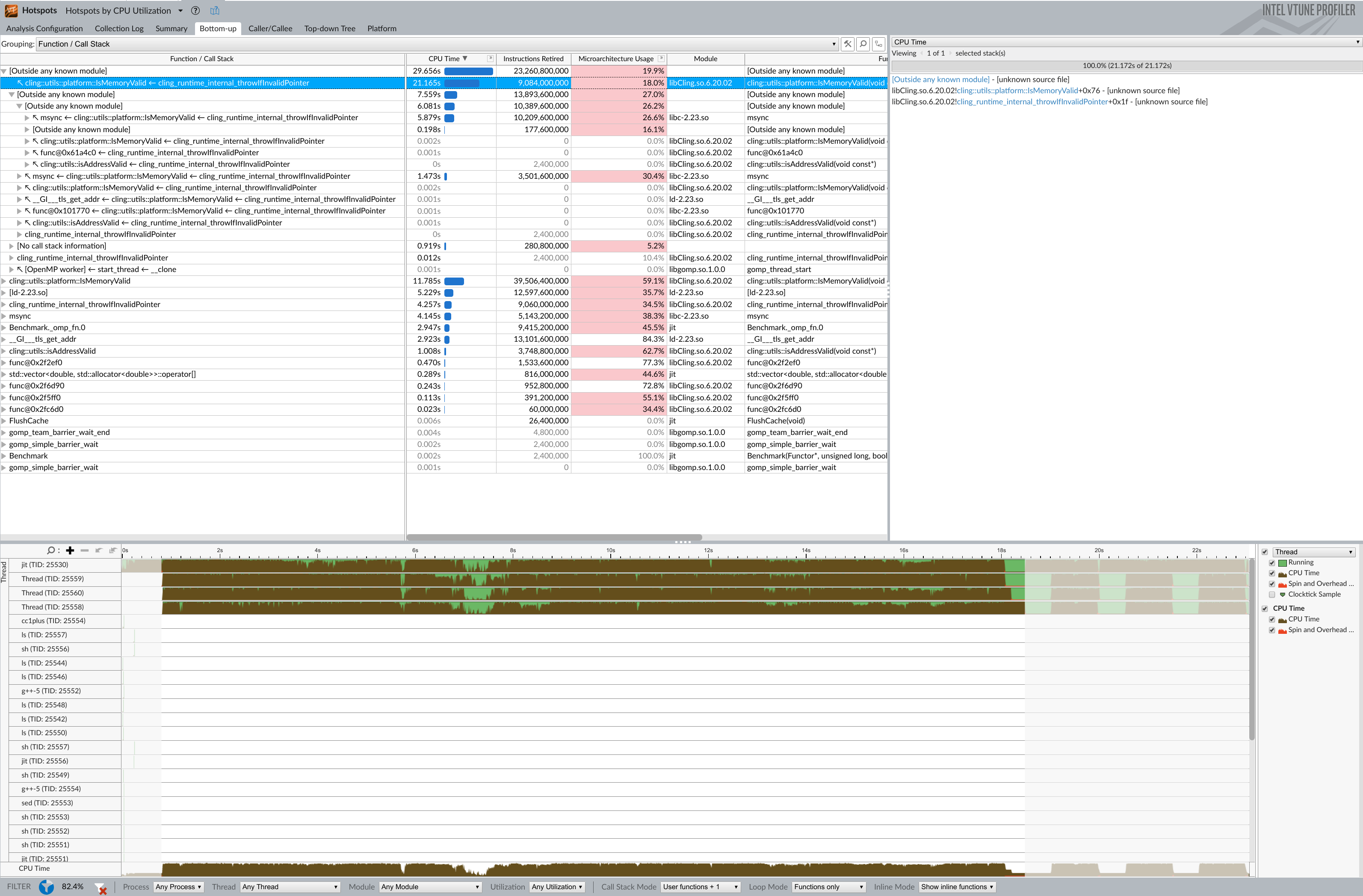
I profiled [1] with Vtune and found that the majority of the time is spent in function cling::utils::platform::IsMemoryValid.
Shouldn’t R__CLING_PTRCHECK(off) disable these checks?
The following screenshot shows the vtune hotspot analysis filtered for the “jit (pointer)” benchmark.
Adding this patch to cling is a little tricky. We used to have optimization level -O2 in the past for a while. It turns out that the optimizer made most of the code 50% slower on average because it was not heavily used and the optimizer invested a lot of time optimizing. That is why the #pragma cling optimize is very useful to annotate the heavily used code.
If we can conditionally enable/disable the inline pass that would likely solve the issue with #pragma cling optimize
Well, but Lukas has reported here that #pragma optimize doesn’t work, and we must fix that. I’ll get to it, either today or in 10 or so days (off next week…)
I.e. as I said, #pragma optimize must appear where code generation happens, i.e. at the point of use of a symbol. R__CLING_PTRCHECK(off) is an annotation for the scope containing the function that should not see pointer checks. Declare actually disables pointer checks altogether.
The issue is that the code is passed through ProcessLine (or one of its siblings), and cling thought “it’s an expression”, and that doesn’t bother to look for R__CLING_PTRCHECK as that’s a declaration thing.
Your options:
use Declare (vividly recommended)
wait for me to fix the interplay between the pointer check and cling’s extraction of declarations from cling’s evaluation wrapper.
I can confirm that runtimes are almost equal with your modifications.
There is one drawback using Declare.
All required headers must be included.
While this is no problem in the reproducer, my real world use case is a bit more complex.
The body of the functor depends on user input and might contain user-defined types.
The definitions of these types are available in dictionaries that are loaded into cling. gInterpreter->ProcessLineSynch seems to take this information into account and compiles the functor without any include statements.
Is there a JIRA ticket to follow the progress of option 2?
@vvassilev
I am not sure if I understood the 50% slow down correctly.
Does the cost of running the optimizer outweigh the performance gains of the generated code?