We’re doing simple TTrees mergings and recently we noticed that it seems to be very slow. 1700 files containing ~20 trees merging with a final output of 25gb take about 5 hours to complete. I used TFileMerger to do the merging. Something like this:
for (auto&& fileName : fileList)
{
fileMerger.AddFile(fileName.c_str());
}
std::cout << "Merging " << fileList.size() << " files. Can be long and no progress bar. Please be patient..." << std::flush;
auto beginTime = std::chrono::system_clock::now();
if (!fileMerger.Merge())
{
throw std::runtime_error("Cannot merge file.");
}
std::cout << "Done. Finished in " << (double)std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now()-beginTime).count()/1000 << "s." << std::endl << std::flush;
[/code]
So I’ve been doing some investigations. A poor man profiling seems to point to TBuffer::Read. I suspect that it may be because where the input files reside actually has network-like performance even though we access them like a local file. So I’ve been playing around with TTreeCache. First of all it doesn’t seem like I can get it to work at all with the TFileMerger or creating a chain and call CloneTree(-1, “fast”) myself. I’m guessing that the “fast” mean the TTree wasn’t read as a tree but simply a stream of data?
Next I actually force TTreeCache usage by actually looping like this:
auto beginTime = std::chrono::system_clock::now();
std::cout << "Merging " << treeName << " from " << fileList.size() << " files..." << std::flush;
auto chain = std::make_unique<TChain>(treeName.c_str());
for (auto&& fileName : fileList)
{
chain->AddFile(fileName.c_str());
}
TTreeCache::SetLearnEntries(1);
chain->SetCacheSize(10*1024*1024);
chain->SetCacheEntryRange(0, chain->GetEntries());
chain->AddBranchToCache("*", true);
chain->StopCacheLearningPhase();
auto perfstat = new TTreePerfStats("ioperf", chain.get());
//std::unique_ptr<TTree> outputTree(chain->CloneTree(-1, "fast"));
for (Long64_t entryIndex = 0; entryIndex < chain->GetEntriesFast(); entryIndex++)
{
chain->LoadTree(entryIndex);
chain->GetEntry(entryIndex);
}
std::cout << "Done. Finished in " << (double)std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now()-beginTime).count()/1000 << "s." << std::endl << std::flush;
chain->PrintCacheStats();
perfstat->SaveAs("perf.root");
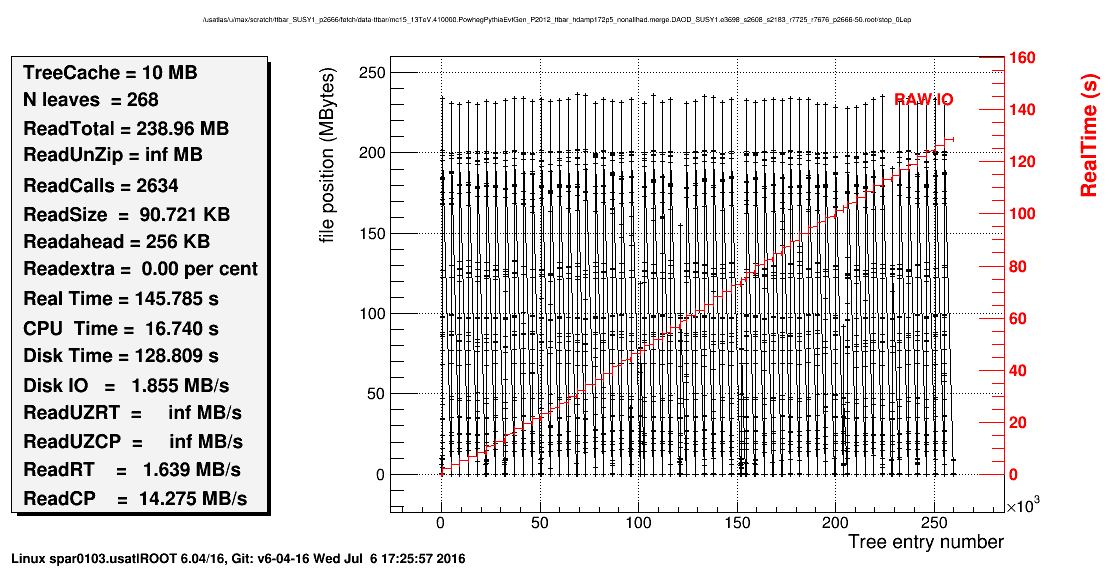
The duration seems to be comparable to actually using the CloneTree() line. What puzzling to me is that it doesn’t look (to me) like the TTreeCache is caching all that much. Here’s the printout:
Why does it only read 107kb on average? Shouldn’t it be ~10MB? Here’s the result from TTreePerfsStat:
Again, it looks like still reading in a small chunk to me.
Any suggestion on what I can do to improve this? I tried to find a way to force these input file to use TNetFile but couldn’t. I thought about doing multithread, but I have problem using std::async with ROOT for some reason, and I think it probably hurt rather than help. I also toying with the idea of loading the whole file into a TMemFile, but I feel like I’m going in a wrong direction.
[quote]Edit: I’m using 6.04/16[/quote]This is the first release where the ‘fast cloner’ is also using a prefetching (for technical reason this could not have been the TTreeCache itself), so it makes sense that the performance for the fast cloning as far as raw I/O latency is concerned would be similar (however the fast cloning should actually have been ‘faster’ since it would skip the decompression and unboxing/streaming of the object).
[quote]Why does it only read 107kb on average? Shouldn’t it be ~10MB? Here’s the result from TTreePerfsStat:[/quote]This seems to indeed be the problem. It looks like the TTree is ‘sparsely’ spread within the file. It is plausible that this is due to 2 separate TTrees of similar size being written at the ‘same’ time in the same file.
Could you share of the input file so that we can investigate ways to improve things?
[quote=“pcanal”]This seems to indeed be the problem. It looks like the TTree is ‘sparsely’ spread within the file. It is plausible that this is due to 2 separate TTrees of similar size being written at the ‘same’ time in the same file.
Could you share of the input file so that we can investigate ways to improve things?
Thanks,
Philippe.[/quote]
Hi Philippe,
What would be the best way to share the file with you? Is a public directory on CERN’s LXPLUS work? I’m a little unsure about the policy of ATLAS about sharing the file, but I hope that a small subset of MC should be ok…
That said, the trees are produced exactly as you described. For each event, we run multiple times for each systematic uncertainties and write each of them in a separated tree. The reason for that was originally the slowest part of the code was retrieving those events from the input file so we don’t want to loop the other way (i.e. process the whole tree for a single systematic, then repeat). Changing that now will be very complicated so I’d like to avoid it. Is there anything else I can do to improve the situation for now? Something like caching multiple events before writing so the data are less spread?
[quote]What would be the best way to share the file with you? Is a public directory on CERN’s LXPLUS work? [/quote]Yes, this would work.
[quote]Changing that now will be very complicated so I’d like to avoid it. Is there anything else I can do to improve the situation for now? Something like caching multiple events before writing so the data are less spread?[/quote]I’ll take a look at the file. Likely the easiest would be to increase the cluster size.