I wanted to know how the background efficiency is calculated (based on mvaeffs.cxx). Assuming that the confusion matrix is used for such purpose, how do you calculated the TRUE NEGATIVE and FALSE POSITIVE when your background events each have a predetermined weight?
I mostly want to know this because I’d like to use a different coefficient to find the best cut (the matthews correlation coefficient) and I do not understand how the background weights are accounted for when calculating this efficiency?
If your events have weights the numbers of true negative and false positive are computed weighting each events with its own weight.
Since you calculating effciencies, these are normalised by the total sum of the weights.
The weights can be in principle negative too, as far as the total number of weights is not a negative number.
Thank you Lorenzo for your reply. If I understand correctly, for a defined cut value, you increment the true negative and false positive value by the weight of the event you are classifying rather than by one. Then, to obtain the efficiency, you divide by the total weight of all the events you are classifying?
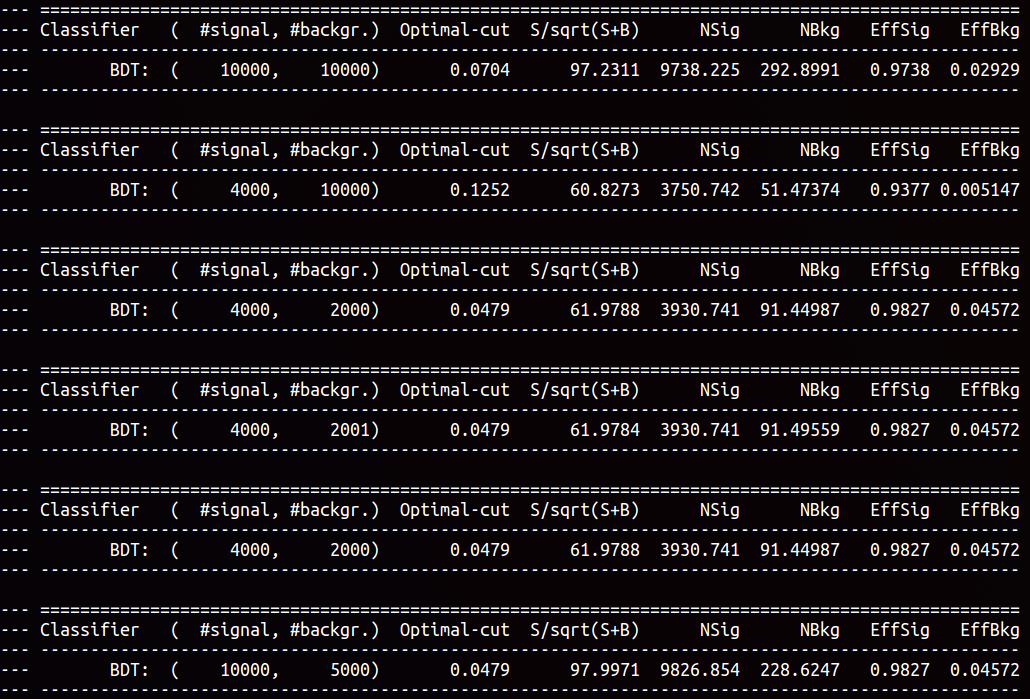
If I am correct, it means that the S/sqrt(S+B) curves as well as the efficiency curves heavily depend on the number of events you wish to use to get these values. I see that when plotting the efficiency, purity and significance curves, the algorithm automatically chooses 1000 signal and 1000 background training events. If I increase them both to 10000, not much changes in these curves. However, if I have let’s say, 1000 signal and 10000 background training events, a significant change occurs (different optimal cut and different maximum significance). See the picture below. Does that mean that it is best to always have the same number of signal and background training events when plotting these curves? How do you end up knowing which is the best cut if its value is so sensitive to the number of events you consider?
My understanding is that the best values for S and B in this case is determined by the situation that you are looking at. I.e if you are expecting to see 1000 background events and 10 signal events, then this is what you should put.
The expectation might be estimated from e.g. integrated luminosity and process probabilities.