Hi guys,
can anyone explain to me how TF1::GetRandom() exactly works when called?
I don’t know if it’s only me, but the explanation given in the source code is very foggy, or maybe too much condensed.
I will appreciate any kind of help
Hi guys,
can anyone explain to me how TF1::GetRandom() exactly works when called?
I don’t know if it’s only me, but the explanation given in the source code is very foggy, or maybe too much condensed.
I will appreciate any kind of help
Hi,
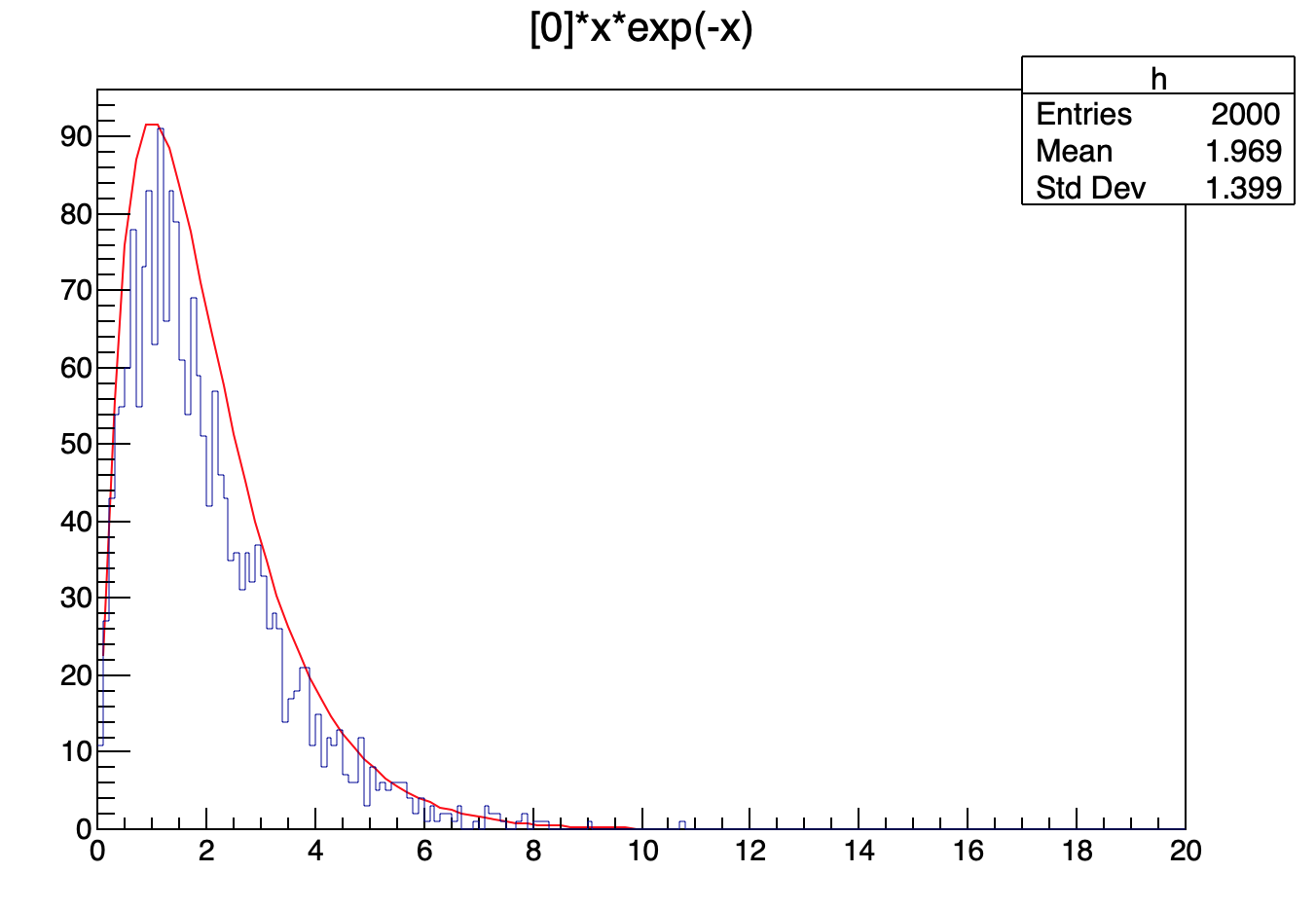
the TF1::GetRandom()of the TF1 extract a number using the TF1 function as a p.d.f.
In example I defined the TF1 as
TF1 *f=new TF1("f","[0]*x*exp(-x)",0,20) and set the parameter [0] equal to 250
then i called 2000 times GetRandom to fill an histogram
for( int i=0;i<2000;i++)h->Fill(f->GetRandom())
and the result is the plot attached.(choosing the right scaling factors, the TF1 overlap with the histogram perfectly)
Cheers,
Stefano
Hi Stefano,
Sorry for the misunderstanding, but with my questions I meant: “How does GetRandom() can give you random numbers following the function shape?”
The explanation given in the source file is the following:
The distribution contained in the function fname (TF1) is integrated over the channel contents.
It is normalized to 1. For each bin the integral is approximated by a parabola. The parabola coefficients are stored as non persistent data members Getting one random number implies:
This is what is not clear to me about GetRandom()
Thank you so much
Sorry for the late answer and the misunderstanding,
When you want to generate a random number according to a specific distribution, you have
to apply the Inverse transform sampling
In simple case, as exponential distribution you are able to do all this analitically and obtain
x = log(1-r1)/(−λ)
otherwise you have to do everything numerically with some approximation, and it is what root do.
I hope everything is understandable .
S
Ok that’s clear, but what about the parabola mentioned in the description?
It’s just for the approximation of the cumulative and to easily compute the x from the y
Ok thank you, problem solved