Dear TMVA expert,
I’m trying to use MethodCategory with a BDT method. I get very weird and absurd results that make me curious on how categories work in TMVA.
My categorization is really simple: in about 5% of my events some variable are not available so I made two categories:
- Category 1 for 95% of the events with all the 10 variables
- Category 2 for 5% of the events with 6 variables
In order to control what is going on I train in the same macro a BDT with no categories (the empy variables are filled with -1 for that 5% of events). In principle the perfomances should be really similar since only very few events are not in category 1, and the events in category 2 should be quite difficult to separate.
This is my code (where I edited the variable names for simplicity):
factory->BookMethod( dataloader, TMVA::Types::kBDT, “BDT”, bdtOptions ); //control BDT
TString Cat1Vars(“var1:var2:var3:var4:var5:var6:var7:var8:var9:var10”);
TString Cat2Vars(“var1:var2:var3:var4:var5:var6”);
TMVA::MethodCategory* mcat = 0;
TMVA::MethodBase* BDT_Cat = factory->BookMethod( dataloader, TMVA::Types::kCategory, “BDT_Cat”,“” );
mcat = dynamic_castTMVA::MethodCategory*(BDT_OSMuon_Cat);
mcat->AddMethod( cat1Cut, Cat1Vars, TMVA::Types::kBDT, “BDT_Cat1”, bdtOptions );
mcat->AddMethod( !cat1Cut, Cat2Vars, TMVA::Types::kBDT, “BDT_Cat2”, bdtOptions );
Where
TString bdtOptions(“H:V:UseBaggedBoost:BaggedSampleFraction=0.8:NTrees=500:MaxDepth=X:nCuts=-1:MinNodeSize=0.1%:BoostType=RealAdaBoost:AdaBoostBeta=0.6”);
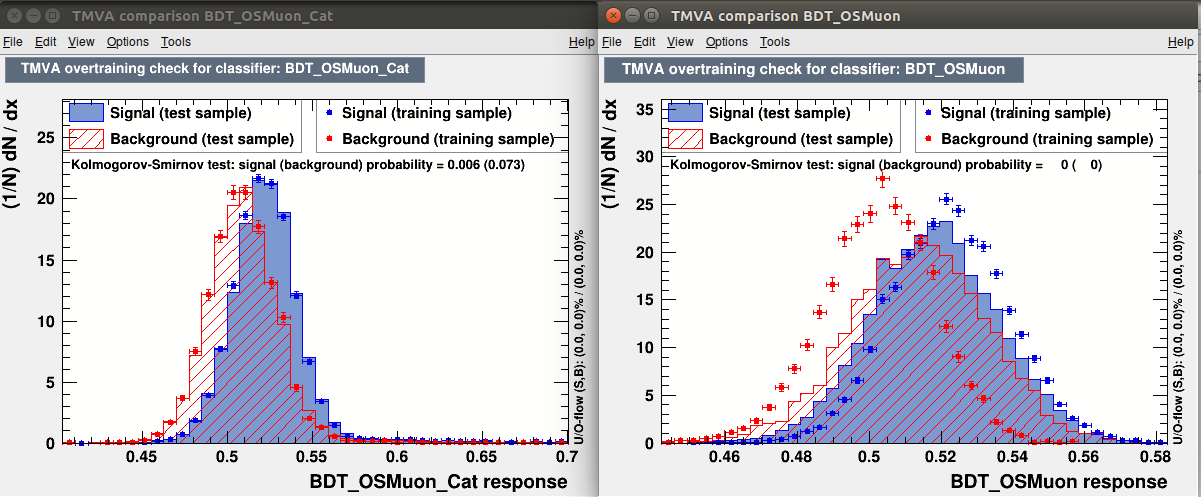
Strange things happen when I start to tune MaxDepth. If I use a “standard” value like MaxDepth=4 everything seems normal (see figure), and the categorized BDT perform slightly better (0.645 vs 0.639 ROC AUC)
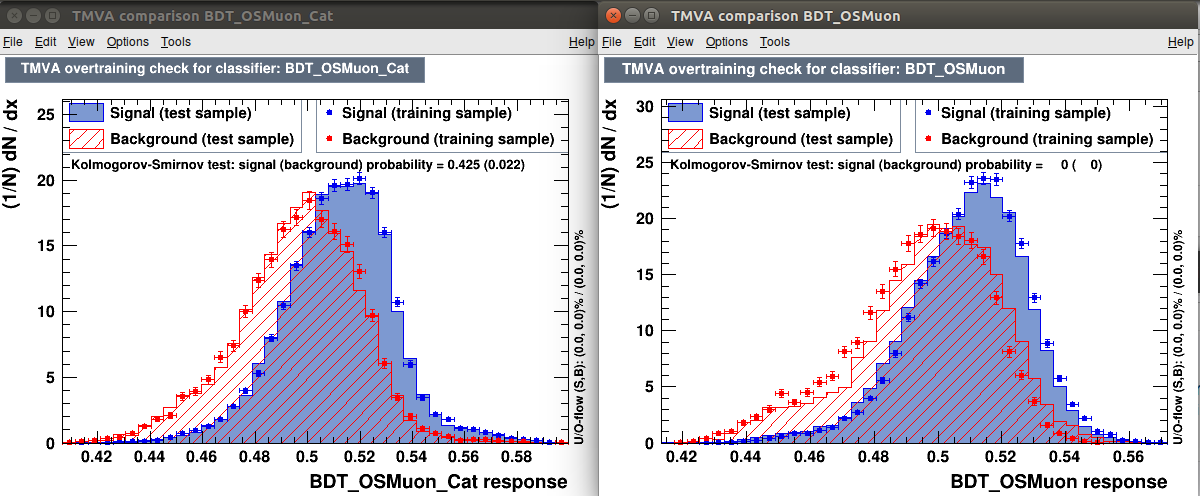
When I start to push MaxDepth to higher value the non-categorized BDT start to (as expected) heavily overfit, while the categorized BDT keeps getting better and better (see figures). This is absurd since they should have very similar performance.
MaxDepth=6

MaxDepth=20
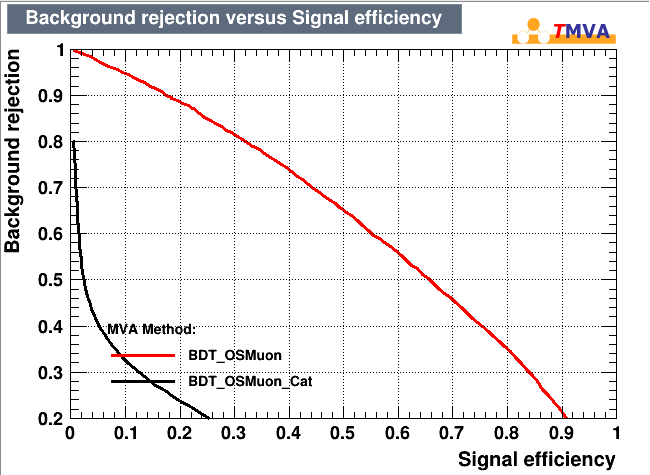
The ROC response is even weirder (considering the fact that TMVA give mi an outstanding 0.820 as roc integral (black curve)
MaxDepth=20
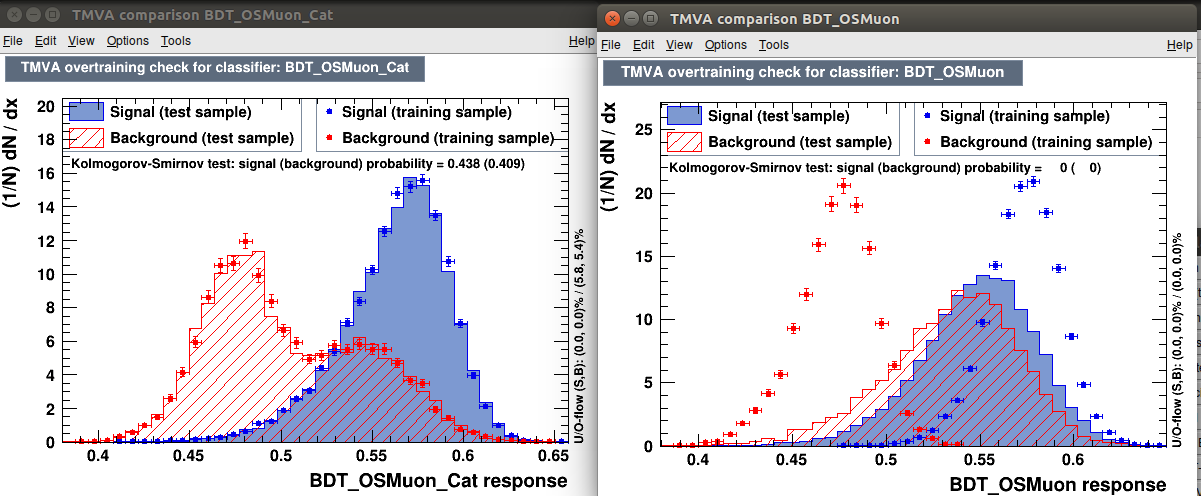
I really cannot understand what is going on with the categorized BDT. Basically the more I overfit the BDT the more the same BDT gets better in a simple characterization. The dataloader is the same and the SplitSeed is set to 0.
Do you have any idea why this happens? Where is the trick for this unrealistic performance of MethodCategory?
Thank you,
Alberto
EDIT:
to further test this behavior to the extreme I change the categorization into two random categories of the same size with no physical meaning (basically 50% chance to go into cat 1 and 50% canche to go into cat 2). In principle this should bring no increase in performance at all. But this is what I get:
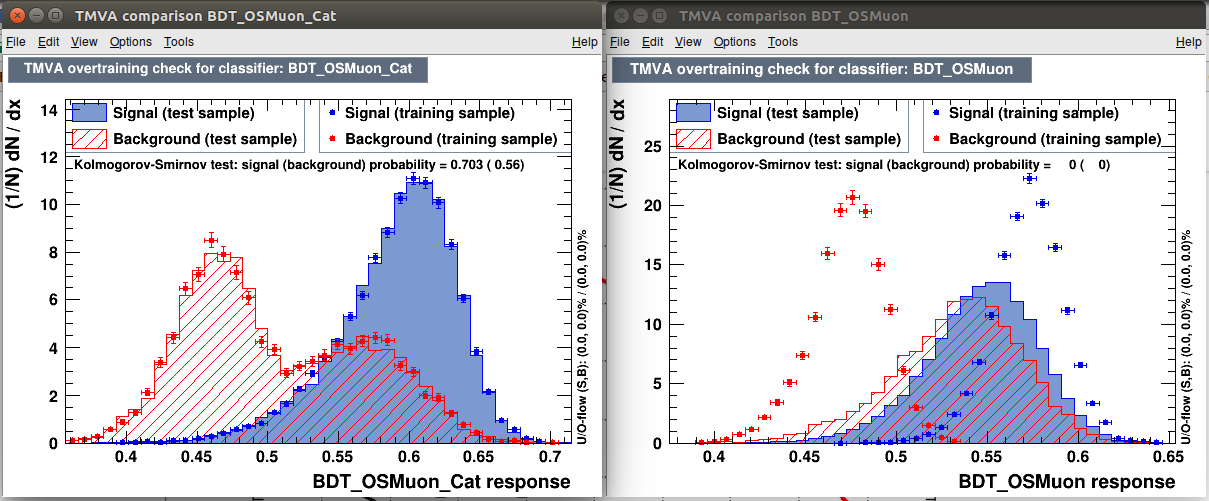
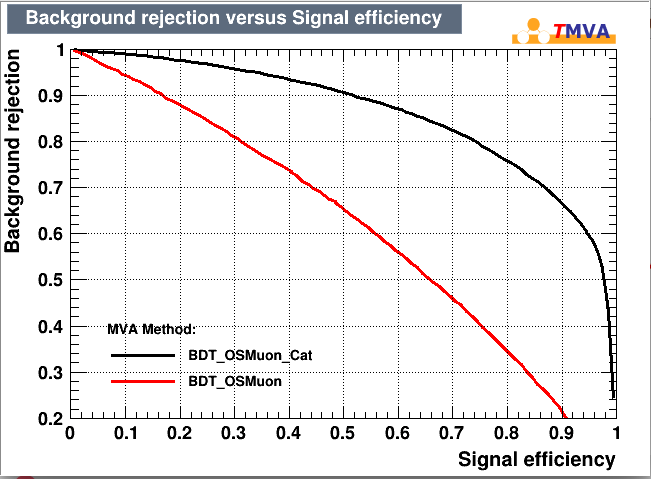
The simple fact of being categorized (even without any sense) seems to make the BDT immune to overtraining!