Hello Experts,
I am trying to fit a distribution with the following form of equation:
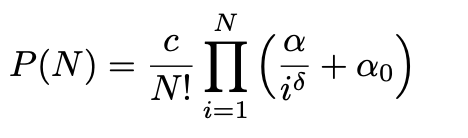
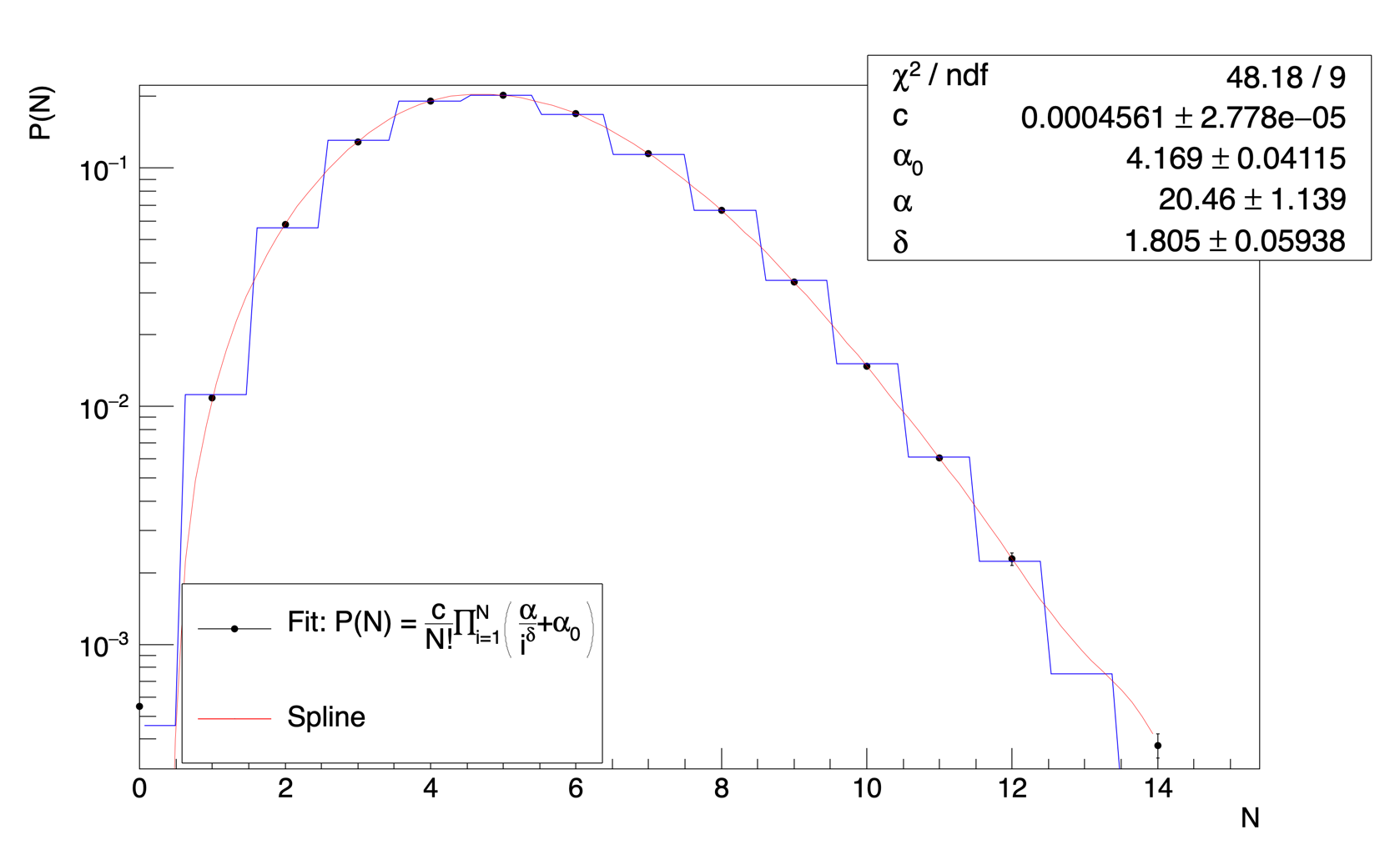
I made the following code for the purpose:
double myFitFunction(double *x, double *p)//Subpossonion
{
int N = (int)std::round(x[0]);
double mul =1.0;
for (int i = 1; i < N; ++i)
{
mul = mul*((p[2]/pow(i,p[3]))+p[1]);
}
double r = p[0]*mul/tgamma(x[0]+1);
return r;
}
void CrossCheck()
{
gStyle->SetOptStat(1);
gStyle->SetOptFit(1);
gStyle->SetTitleW(0.4);
//Histogram
TCanvas* canvas = new TCanvas();
canvas->SetLogy();
double binY[14] = {0.00055, 0.01083, 0.05802, 0.1293, 0.1917, 0.2019, 0.1692, 0.1151, 0.06641, 0.03329, 0.014690, 0.006080, 0.002279,0.0003763};
double binYE[14] = {0.00000, 0.00019, 0.00042, 0.0006, 0.0007, 0.0008, 0.0008, 0.0007, 0.00055, 0.00043, 0.000300, 0.000188, 0.000132, 4.31e-05};
double binX[14] = {0.,1.,2.,3.,4.,5.,6.,7.,8.,9.,10.,11.0,12.0,14.0};
double binXE[14] = {0.};
TGraphErrors* Summation = new TGraphErrors(14,binX,binY,binXE, binYE);
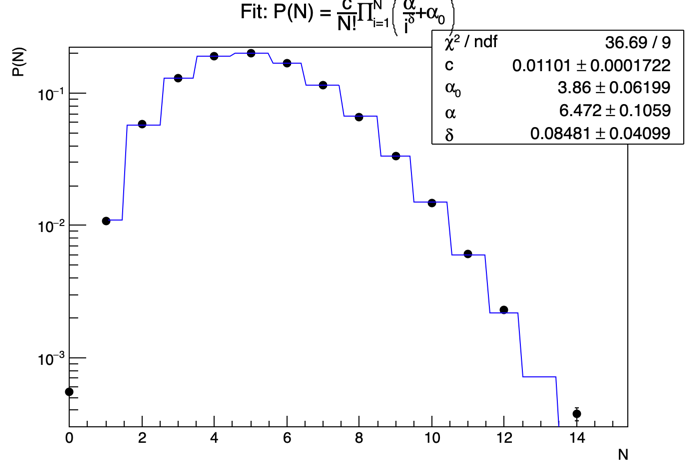
Summation->SetTitle("Fit: P(N) = #frac{c}{N!}#prod_{i=1}^{N}(#frac{#alpha}{i^{#delta}}+#alpha_{0})");
Summation->GetYaxis()->SetTitle("P(N)");
Summation->GetXaxis()->SetTitle("N");
Summation->SetMarkerColor(1);
Summation->SetMarkerSize(1);
Summation->SetMarkerStyle(20);
Summation->Draw("AP");
TF1 *fitMul =new TF1("fitMul",myFitFunction,0,14,4);
fitMul->SetParLimits(0,0.0,1.00);
fitMul->SetParLimits(1,1.0,10.0);
fitMul->SetParLimits(2,0.0,150.);
fitMul->SetParLimits(3,0.0,10.0);
fitMul->SetParNames("c","#alpha_{0}","#alpha", "#delta");
fitMul->SetLineColor(4);
fitMul->SetLineWidth(2);
//Do Fit
Summation->Fit(fitMul,"RME");
}
which gives the following fit curve:
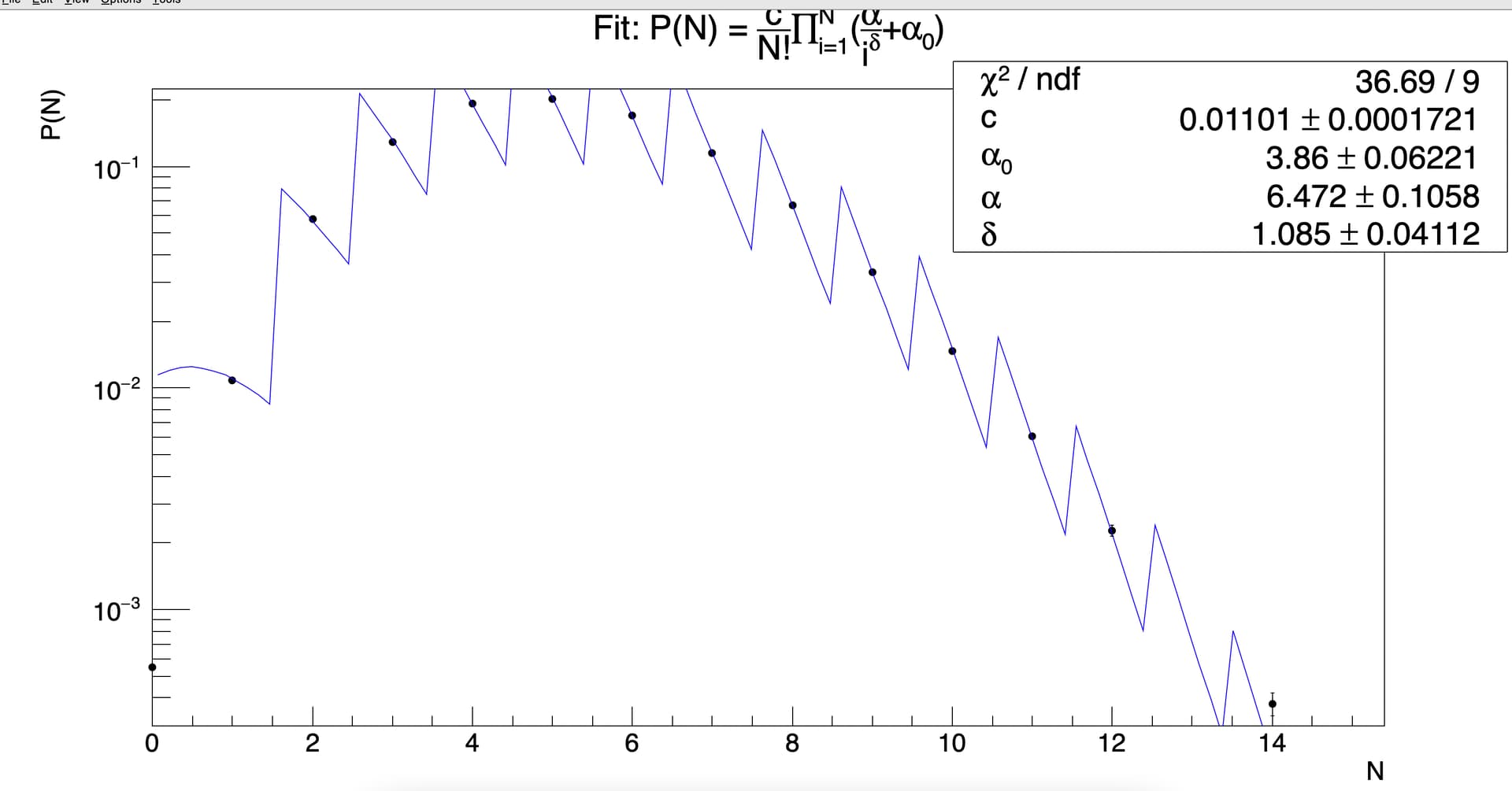
Since the multiplication series is from i = 1 to N and there is N! which has to be taken from the X axis during the fitting, I did this:
int N = (int)std::round(x[0]);
and I am using:
n! = tgamma(n+1)
in the fit function. I think that something is obviously wrong with the way in which I am trying to implement this fitting. Could you please help me to make it correct?
Sincerely
Rahul