I would like to import a tree into a numpy array using pyROOT and Python 3.6. I managed to do that except for a branch containing the names of the particles involved (one name per event). I tried with
tree.SetBranchAddress(name, addr)
for j in range(nentries):
tree.GetEntry(j)
col.append(addr[0])
array[name] = col
with fixed format for the strings (‘S30’ to be specific), but I obtain results like
proton\x00\x00\x00
I thought that the strings have different lengths and so I tried
for j in range(nentries):
tree.GetEntry(j)
for i, (name, t) in enumerate(listOfColumnsAndTypes):
array[i].append(getattr(tree, name))
but I got UTF-8 encoding errors. I tried to change the encoding (to ASCII) and I got the same results as above. Is there any way to know the encoding used by the strings in the tree entries? I guess that this problem might also explain why my first attempt was unsuccessful.
(If it matters, the root file comes from a GEANT4 output and the tree.Print() method shows that the branch I am interested in has the Char_t type.)
First I would like to mention that, since ROOT 6.14, we have a feature to read TTrees into numpy arrays. It works for trees with branches of arithmetic types, though:
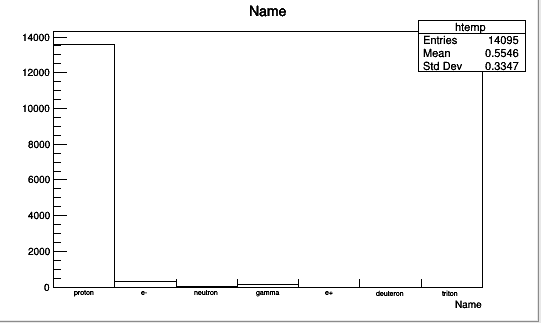
I didn’t notice that earlier because I have several thousands values and I simply didn’t print them: I was OK checking the automatic histogram of the ntuple by the TBrowser (which apparently looks fine to me).
Actually, the names should be “proton”, “neutron”, “e-”, “e+”…, and not “e-ton”, “roton”… At least, this is what I expect from GEANT4 and what I see in the histogram of the TBrowser.
That is why I thought about an encoding problem: since everything seems fine as long as I am exclusively on ROOT, I guessed that Python expects a somewhat different structure for the strings, resulting in it reading parts of the memory surrounding the string entries and/or not correctly decoding the bytes. The issue is not simply related to the string length, because even when I store the values into 2-charachter strings I get things like “e-”, “e+”, “\x00-”, “\x00+” etc.
Would it be possible that you share with me the input file you are using? I would like to know if this is related to the Python version (did you try if the same happens with Python2?).
I do have a Python 2.7 installation, but my ROOT is built for Python 3.6 and I am not sure I want to rebuild ROOT just to try that: I did it quite some time ago and I remember it was not easy for me. Moreover, if I break something, I might not be able to get the output out of GEANT4 any more, which is my primary concern…
After saving the output of tree.Scan() into a file, I noticed some blank entries where the names of the particles were supposed to be, even if the TBrowser looks fine. I as starting to think that the issue is with the file itself and thus Geant4 (unless somebody finds a solution).
If that is so, thank you anyway for your efforts and help.
I believe the e-ton appearances are due to the fact that the same buffer is reused to read protons and electrons. So when you read a proton, that buffer stores proton, but then when you write e- in the same memory address it keeps the old characters that were written there.
This looks like a bug in PyROOT, I will open the corresponding ticket. A temporary workaround would be to just get a substring when the name starts with e, so f.Detector.Name[:2].
Actually, the same thing happens in C++ if you allocate an array of characters and use SetBranchAddress, the only difference is that the zero character is interpreted as end of string in C++ but not in Python.
Thanks for starting this thread! I find this thread too valuable to be hidden as a topic in the Newbie section. Do you have objections against moving this thread to the ROOT section?