While profiling some non-trivial ATLAS code on multiple threads, I found that using TTreeFormula from multiple threads seems to be a bottleneck. So I played a bit with this. I wrote the following code as a test formula.tar.bz2 (9.5 KB).
I thought that this simple example would help me understand things more, but I’m just more confused now than I’ve been before.
On macOS, on a 4 (HT) core laptop I get the following output from this:
Info in <process>: Spent 0.717164 seconds with 1 threads (result = 68.0995)
Info in <process>: Spent 5.20281 seconds with 2 threads (result = 68.0995)
Info in <process>: Spent 8.80905 seconds with 4 threads (result = 68.0995)
Info in <process>: Spent 10.8224 seconds with 8 threads (result = 68.0995)
On SLC6, on an 8 (HT) core desktop on the other hand I get:
Info in <process>: Spent 0.652441 seconds with 1 threads (result = 68.0995)
Info in <process>: Spent 0.243597 seconds with 2 threads (result = 68.0995)
Info in <process>: Spent 0.378358 seconds with 4 threads (result = 68.0995)
Info in <process>: Spent 0.65322 seconds with 8 threads (result = 68.0995)
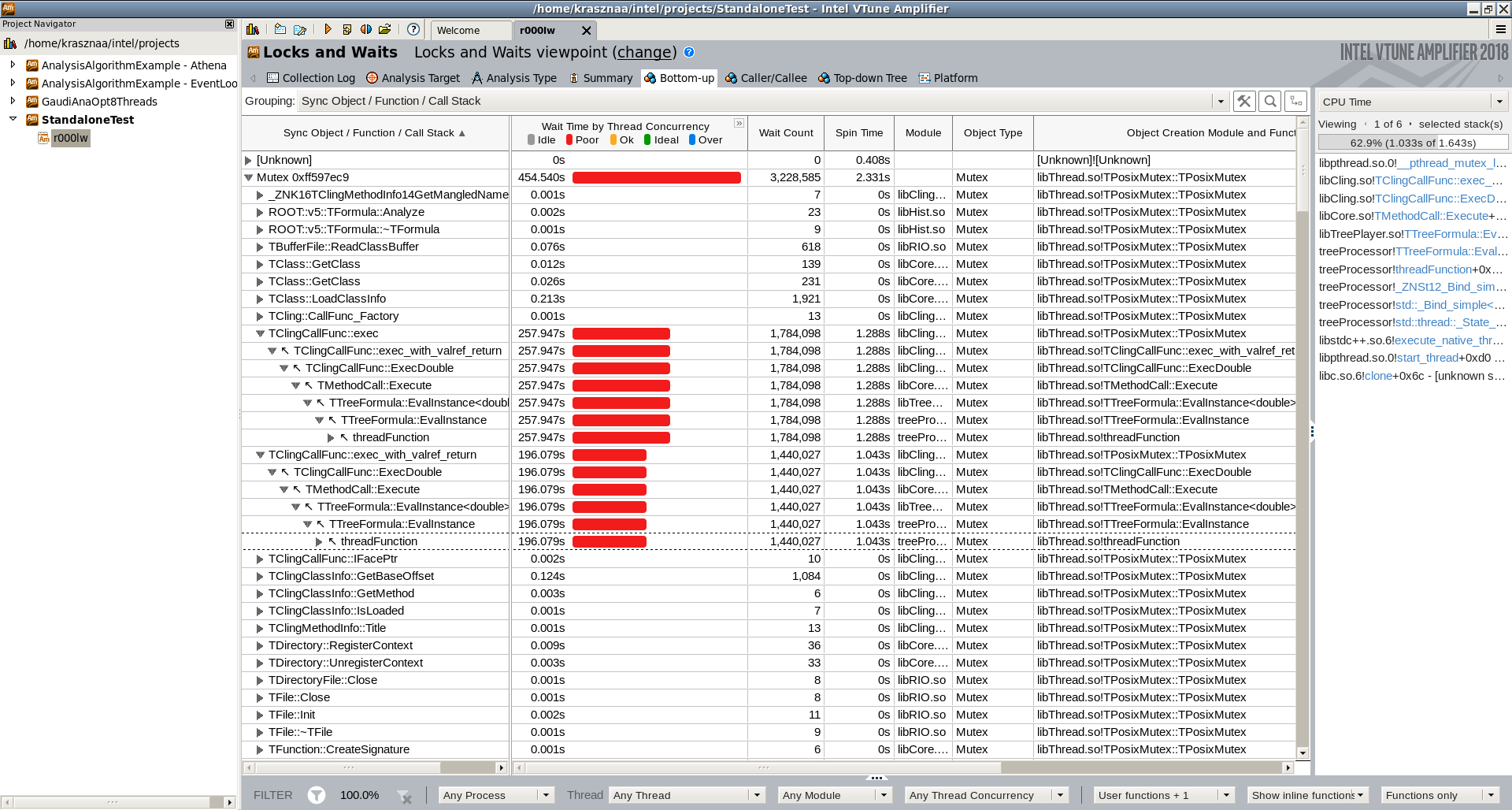
Then I ran a “Locks & Waits” analysis on the executable with VTune (this is how I found the original problem in the ATLAS code), and while executing that test, I saw:
Info in <process>: Spent 1.07751 seconds with 1 threads (result = 68.0995)
Info in <process>: Spent 2.75665 seconds with 2 threads (result = 68.0995)
Info in <process>: Spent 40.5598 seconds with 4 threads (result = 68.0995)
Info in <process>: Spent 61.5856 seconds with 8 threads (result = 68.0995)
So clearly the formula evaluation is a pretty big bottle neck, it’s just that under normal circumstances it doesn’t show up “as much” under SLC6 as under macOS.
Finally, the question: How is one supposed to write efficient code like this for a multi-threaded application? I know that ROOT internally can do this efficiently. But how exactly?
@eguiraud, maybe it’s quicker if I ask you directly about this. How does TDataFrame produce pre-compiled code internally that can be used efficiently from multiple threads, without locks on a single global resource?
Hi Attila,
stripping out a lot of details that are hopefully unimportant in your case, this is pretty much what happens in TDataFrame:
struct F { int(*f)(void); }
auto fptr = reinterpret_cast<F*>(gInterpreter->Calc("F{[]() { return 42; }}"))
fptr->f(); // can be invoked from multiple threads
Indeed, until v6.12 (or the current master), the ROOT main lock was held during the execution of any JIT compiled code.
If you re-run your example with the master, you should see this bottle neck reduced (we still need to hold the lock while preparing the argument for the call).
Thanks for the feedback! I’m getting the sense though that if we want an analysis tool to be performant, we’ll have to move it away from getting values out of a TTree with interpreted code.
@eguiraud, how would you pass values from a TTree to this function?
Having to write explicit code for doing what is done through interpreted code at the moment is of course not out of the question. I’m mainly just trying to determine at the moment how much work it’s going to be to make one particular ATLAS tool performant in MT mode.
You can access “compiled” variables from jitted code by address. You take a string that is the address of the variable and reinterpret_cast it to the correct type in the jitted code:
struct F { int(*f)(void); }
int a = 42;
std::stringstream codestr;
codestr << "F{[]() { return *reinterpret_cast<int*>(" << &a << "); }}"
auto fptr = reinterpret_cast<F*>(gInterpreter->Calc(codestr.str().c_str()))
fptr->f(); // can be invoked from multiple threads
With this said I don’t know your use-case so I cannot tell whether there would be more efficient ways to get the results you want (e.g. some tricks with TTreeFormula that only @pcanal knows )

 How does
How does