Hello root developers,
Is there any particular difference between the implementation of Adaptive Boosting of TMVA and that of scikit-learn?
I am applying the same algorithm with the same parameters to the same dataset and I get very different results.
The parameters I am using are:
NTrees=1200 MinNodeSize=1.0 BoostType=AdaBoost AdaBoostBeta=0.02 SeparationType=GiniIndex nCuts=14 MaxDepth=6
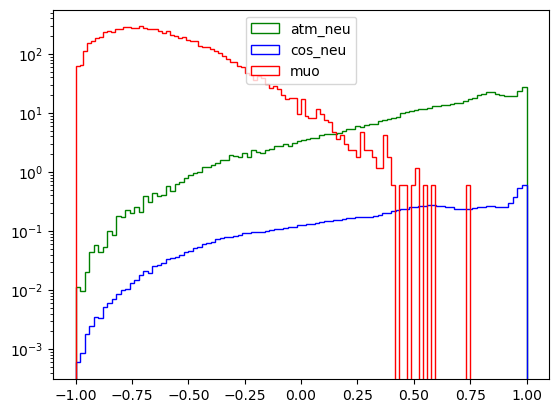
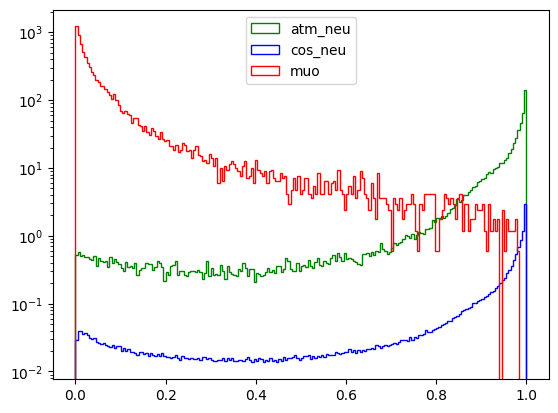
Here we see the score histograms for the two classes. You can ignore the green line.
TMVA AdaBoost
Maybe the difference is just a simple transformation of the output? It seems a bit like this, because even the range on the x-axis is different.
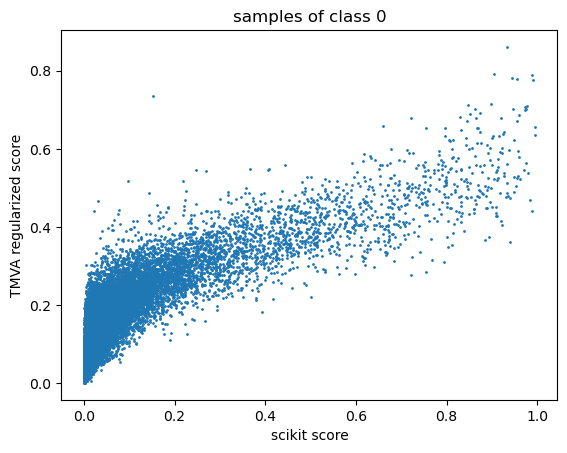
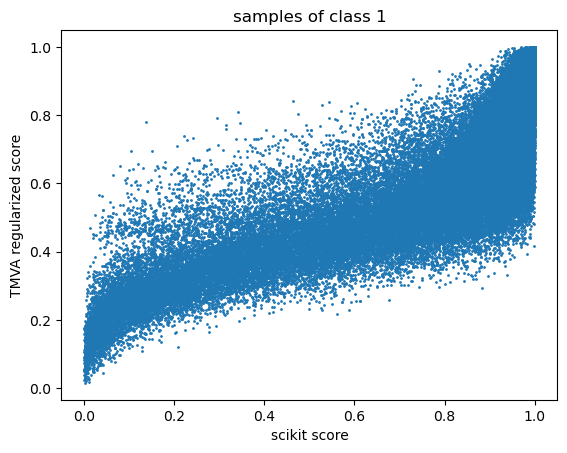
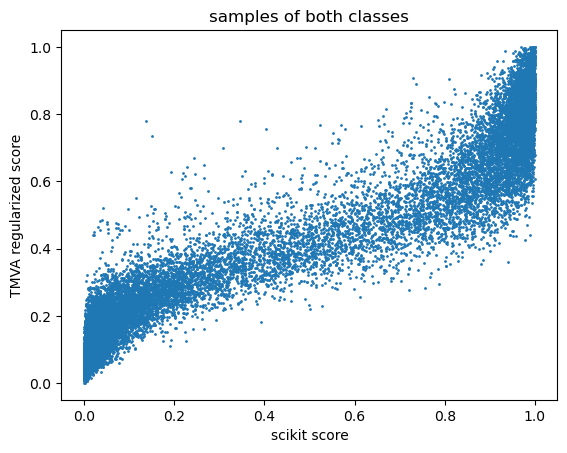
Can you maybe produce a scatterplot of the TMVA ouput vs. the sklearn output for every given sample? If all the dots lie on a line, then it can give you a hint on the difference between the outputs.
Hello Jonas,
first of all thank you for the quick response.
I tried what you proposed and here is what I got.
It seems like there is an inverse sigmoid missing from tmva implementation!!