when I configure dataloader with (1), DNN_GPU response looks ok, you can see the log (2) and the root file (3).
when I configure with (4), the DNN_GPU is strange, the bins are too big, you can see the log here (5) and the root file here (6).
Do you know why by using the ramdon (half/half) tree splitting for the trainning and testing, the DNN response differ that’s much? more over, I would expect it to be better in case of half/half as it use all the events in the tree?
Looking at the log file, it seems to me that the DNN is not working in both case. Looking at the big file I did not see any decrease in the test error.
I would try, still using all the events, maybe some regularisation and /or drop out, maybe a different batch size (how big is your size ?), a larger learning rate at the beginning and longer convergence steps.
If you are still having a problem, please share your data input and macro and I can have a look into it
Dear Lorenzo,
I fixed the issue. While comparing with BDTG the BDTG seems to be better by 5% on the ROC curve. Shouldn’t DNN be better? is there cases where the DNN is better? is the a good wy to train the DNN? When I run ober the root test sample, the DNN looks better, but now I’m surprise to see the the BDT is better…
Regards
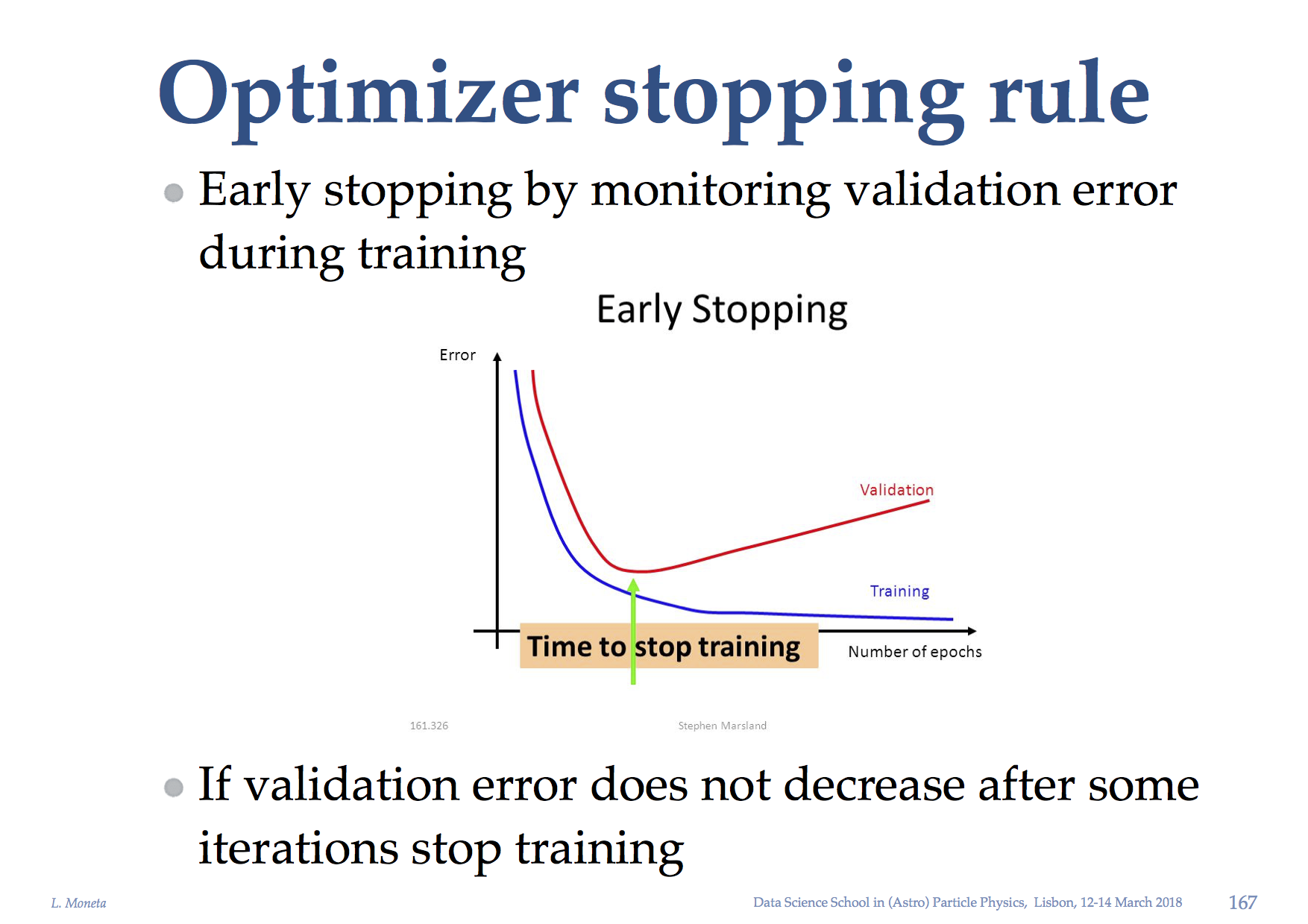
yes, both training and testing error should decrease. At some point the test error will stop decreasing, because you are starting overfitting. There the minimiser should stop.
(see attached figure)
In your case something is not working, because there is no decrease at all of both training and test/validation error.
This you can see also in the obtained ROC curve result. You get something around 0.5 which is just the value obtained from random guessing
Dear Lorenzo,
I’ve changed the parameters… but the DNN still output non-sense result. Could you please give it a try?
you can see the code here (1) and the inputs (2). The problem seems to appear when I’m applying cuts "TCut mycuts = “mcut”. The cut I applied is to select evt in the signal region. Please let me know if you need more information.
Regards
Thank you for the files. I will look at them
I have downloaded them. But since these are big files, please avoid next time to upload there and send maybe just a link.
I have not find anything really wrong with the DNN. I have tried also using Keras and I get similar results. Looking at your data, I could not find by eye any real difference between the two categories, so probably one need to identify better features
Yes, this is my impression. Trying also other methods (e.g. BDT) I get a very poor separation.
I would also check correctly the input data and study their input distributions. I did not have the time to look at that carefully