Hi,
As mentioned in https://sft.its.cern.ch/jira/browse/ROOT-9766, I’m trying to profile a potential bottleneck:
I’m looking for a solution which would work and scale well in case of a definition of N~1000 objects which are then filled to a vector of histograms.
The usecase is N systematics variations of a given observable which in my case is a triple differential cross section so filling vector of TH3D.
The proposed solution in the jira is to fill a vector of histograms at once with the Aggregate action, something like:
ROOT::RDF::RResultPtr<ROOT::VecOps::RVec<TH3D>> output3D;
output3D = DF->Define("SystVec",FillSystVector,{"SystBranch","EventWeight"}).Aggregate(Fill3DVec,add_vector3Dhistos,"SystVec",*hempty3DVec);
FillSystVector is a function which defines a vector of MyObject and Fill3DVec takes this vector and fills a correspoding histogram in a vector of histograms
Merger function:
auto add_vector3Dhistos = [] (ROOT::VecOps::RVec<TH3D> v1, ROOT::VecOps::RVec<TH3D> v2)
{
for (int syst=0; syst<v1.size(); syst++)
{
v1[syst].Add(&(v2[syst]));
}
return v1;
};
Identity (not sure this is the most optimal way, it is adapted from previous/simpler usecase - the shared_ptr<ROOT::VecOps::RVec<TH3D>> is passed as identity to the Aggregate call
ROOT::VecOps::RVec<ROOT::RDF::TH3DModel*> model3Dvec(nsyst);
ROOT::VecOps::RVec<TH3D> hempty3Dvec(nsyst);
for (int syst=0; syst<nsyst; syst++)
{
model3Dvec[syst] = new ROOT::RDF::TH3DModel(model3Dname.c_str(),model3Dname.c_str(),binsX.size()-1, &binsX[0], binsY.size()-1, &binsY[0], binsZ.size()-1, &binsZ[0]);
hempty3Dvec[syst] = *(model3Dvec[syst]->GetHistogram());
}
std::shared_ptr<ROOT::VecOps::RVec<TH3D>> hempty3DVec=std::make_shared<ROOT::VecOps::RVec<TH3D>>(hempty3Dvec);
Performance-wise, it corresponds roughly 1500 TH3D (~200bins each) x 1-10 observables
I’m now investigating optimal running/bottlenecks:
- Testing on 10M events in 16 input files, I get the most optimal running in 10 threads? (for example splitting to 25 threads (machine has 32 CPUs) almost doubles both Real Time and Cpu Time?)
- In running on the 10 threads, I tried to see if RDataFrame is going to show any significant time spent with
auto level = ROOT::Experimental::ELogLevel::kDebug;
auto verbosity = ROOT::Experimental::RLogScopedVerbosity(ROOT::Detail::RDF::RDFLogChannel(), level);
Initial JIT took about 2.2s then
Info in <[ROOT.RDF] Info /build/jenkins/workspace/lcg_release_pipeline/build/projects/ROOT-v6.24.00/src/ROOT/v6.24.00/tree/dataframe/src/
RLoopManager.cxx:670 in void ROOT::Detail::RDF::RLoopManager::Run()>: Finished event loop number 0 (24619.2s CPU, 2521.99s elapsed).
Total number of events: 10184588
Real Time = 3140.547s, Cpu Time = 25234.720s
Info in <[ROOT.RDF] Info /build/jenkins/workspace/lcg_release_pipeline/build/projects/ROOT-v6.24.00/src/ROOT/v6.24.00/tree/dataframe/src/
RLoopManager.cxx:613 in void ROOT::Detail::RDF::RLoopManager::Jit()>: Nothing to jit and execute.
It seems there is a significant portion of time spent in postprocessing of the result - the difference between the 2521.99s shown by RDataFrame and Real Time = 3140.547s in my printout (see also attached psrecord:
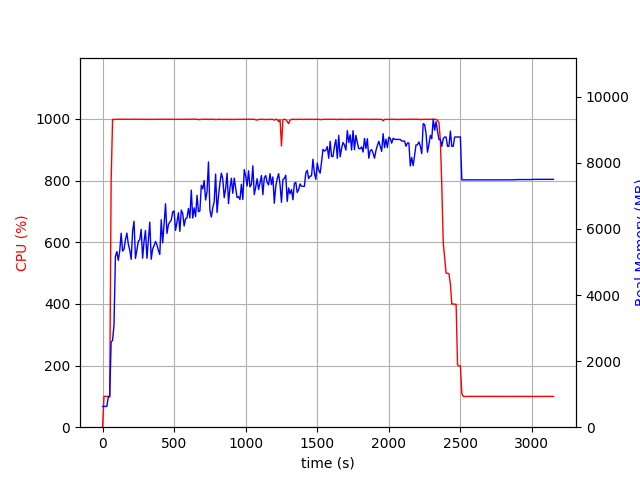
- I’m thinking it’s the 10 CPUs x 1500 x 3 TH3D histograms getting merged together? Is there anything which could be improved (it seems to run only a single thread)
I also tried a profiller (vtune) - it seems that at the moment the most intensive part is TAxis::FindBin/TH3::Fill/TH2::Fill so there probably isn’t much about this part
Cheers,
Zdenek
_ROOT Version: 6.24
Platform: Not Provided
Compiler: Not Provided

{kind=link}