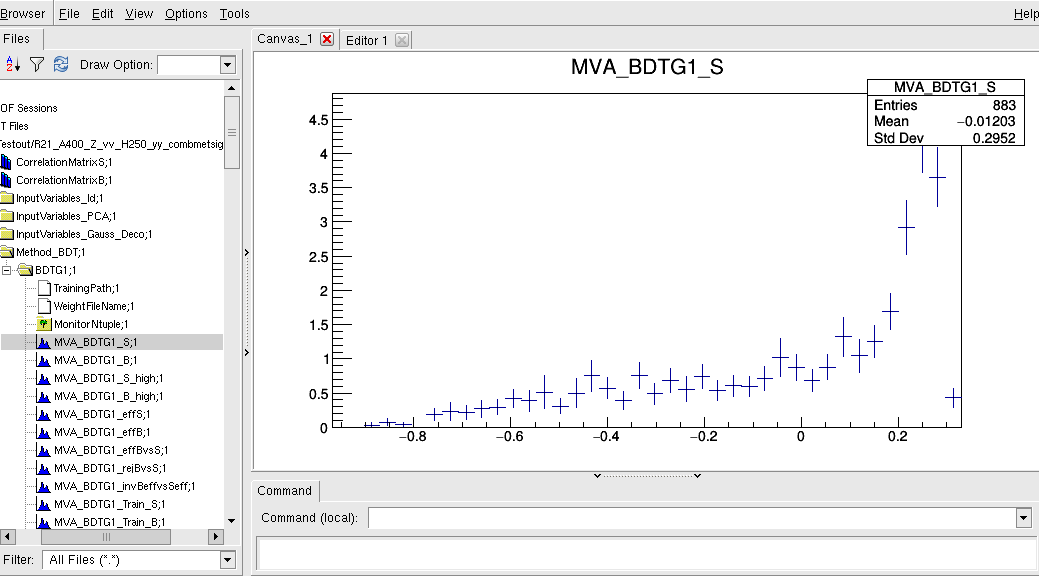
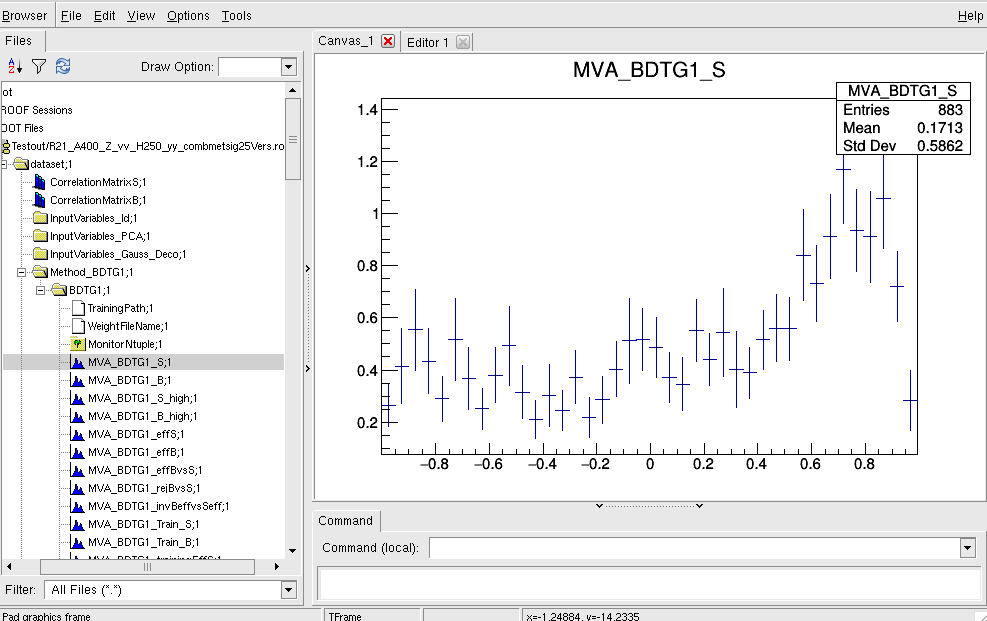
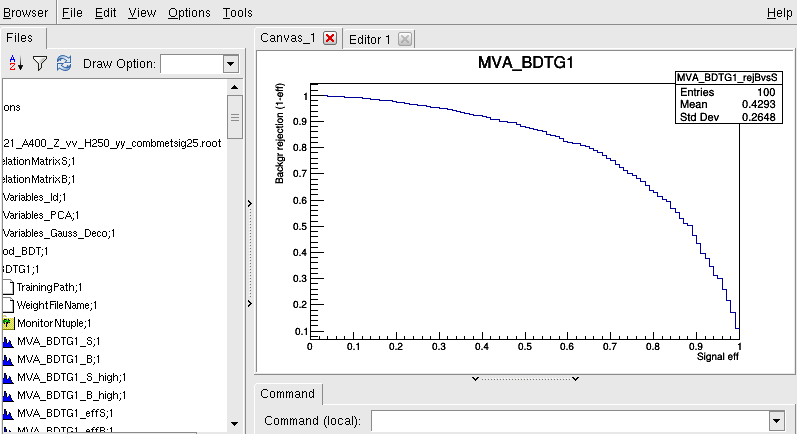
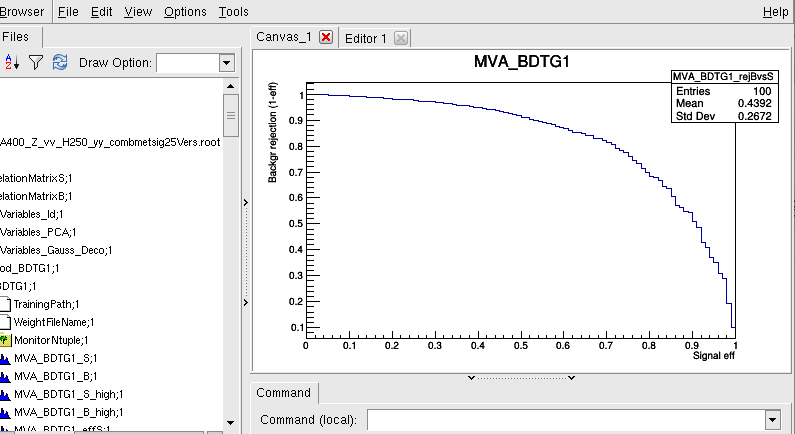
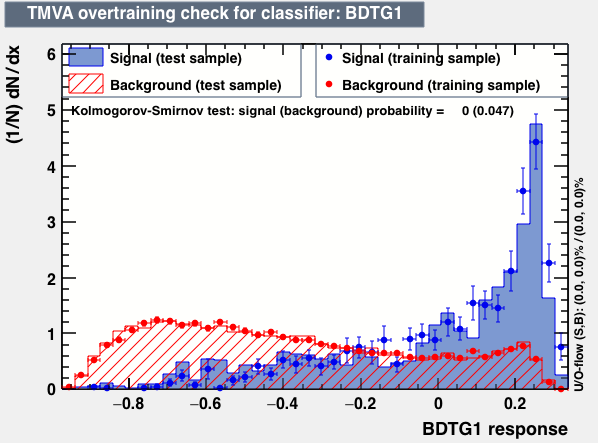
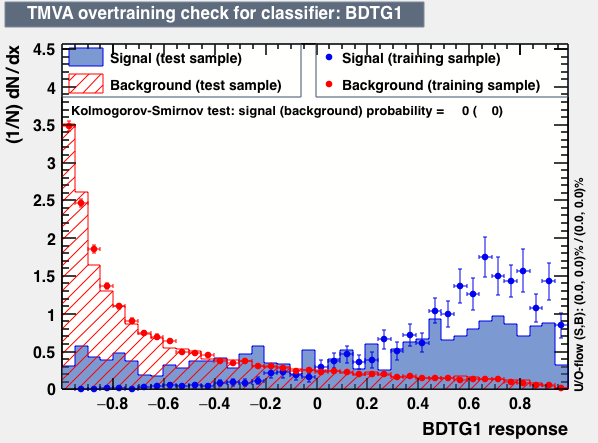
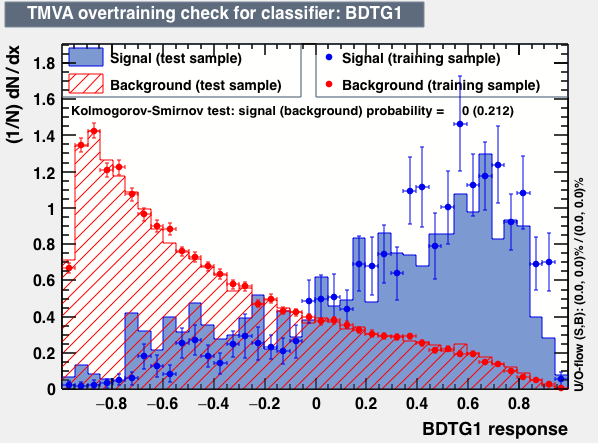
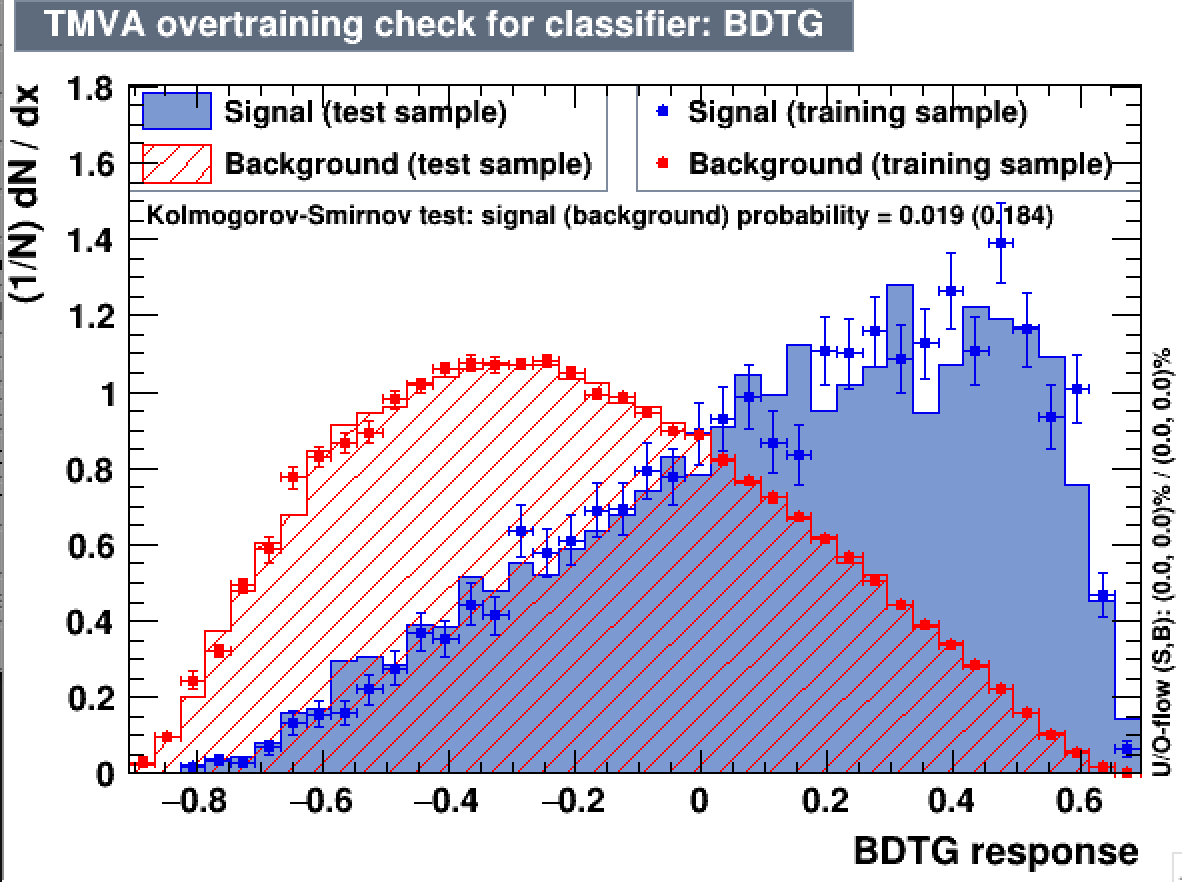
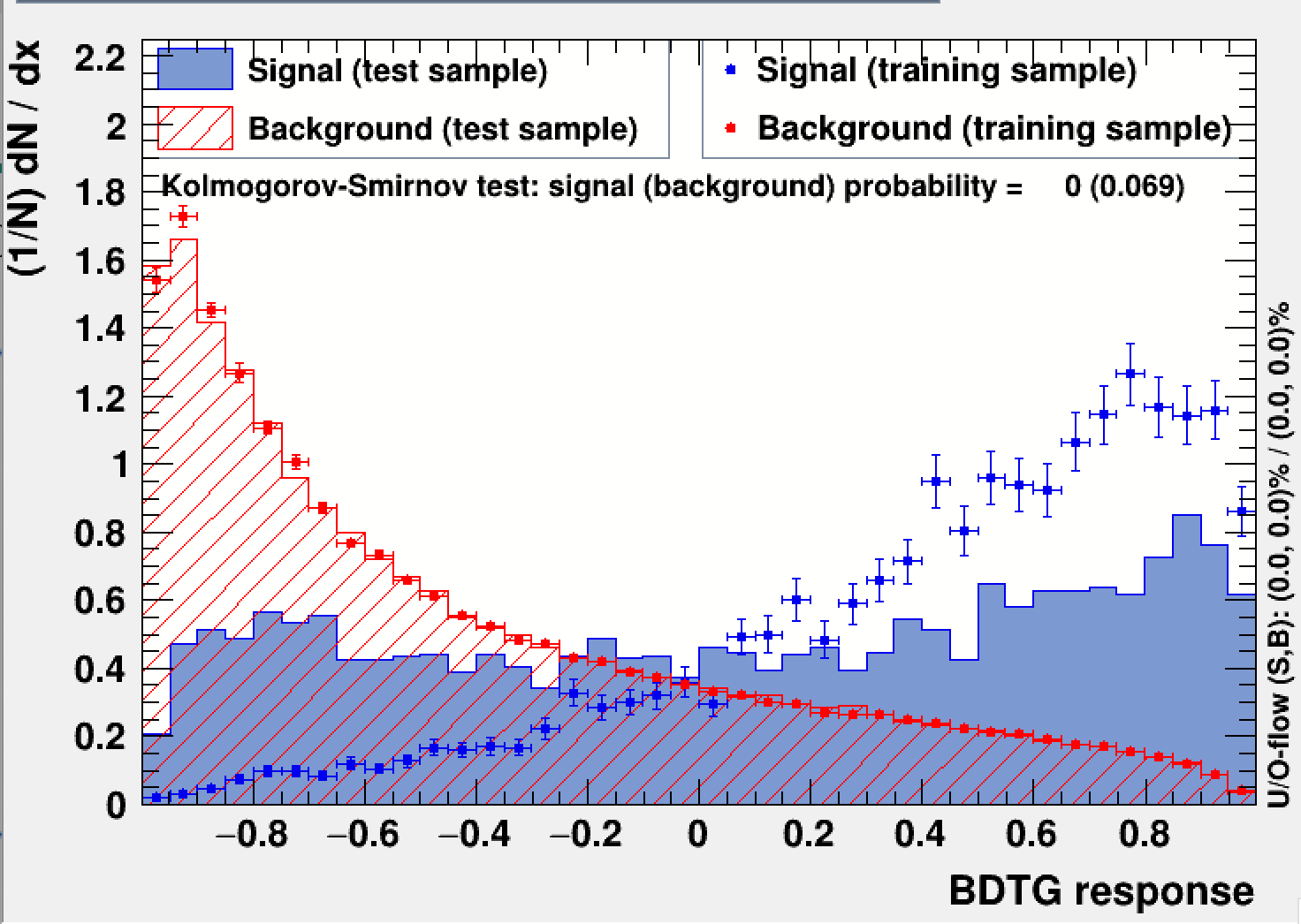
Hi Kim,
thanks for the response, here is a snippet from the scripts
for version 6.06.02:
TMVA::Factory *factory = new TMVA::Factory( sampletype+bdtclass, outputFile,"!V:!Silent:Color:DrawProgressBar:Transformations=I;P;G,D:AnalysisType=Classification" );
std::vector mvaVars_V = splitstr(getVar(bdtclass)," “);
std::vector spectatorVars_V= splitstr(spectatorVars,” ");
std::cout<<“initializing variables…”<<std::endl;
for(int i = 0; i<mvaVars_V.size(); i++){
std::cout<<"adding: "<<mvaVars_V.at(i)<<std::endl;
factory->AddVariable(mvaVars_V.at(i),mvaVars_V.at(i), ‘F’);
}
for(int i =0; i<spectatorVars_V.size(); i++){
std::cout<<"adding spectator: "<<spectatorVars_V.at(i)<<std::endl;
factory->AddSpectator(spectatorVars_V.at(i),spectatorVars_V.at(i),‘F’);
}
Double_t signalWeight = 1.0;
Double_t backgroundWeight = 1.0;
factory->AddSignalTree ( signalTree, signalWeight);
factory->AddBackgroundTree(backgroundTree, backgroundWeight);
factory->SetSignalWeightExpression (“weight”);
factory->SetBackgroundWeightExpression(“weight”);
TCut mycuts = getcut(bdtclass);
TCut mycutb = getcut(bdtclass);
factory->PrepareTrainingAndTestTree(mycuts,mycutb, “nTrain_Signal=0:nTrain_Background=0:SplitMode=Random:NormMode=EqualNumEvents:!V”);
factory->BookMethod( TMVA::Types::kBDT, “BDTG1”,"!H:!V:NTrees=800:MinNodeSize=1:BoostType=Grad:Shrinkage=0.06:UseBaggedBoost:BaggedSampleFraction=0.6:nCuts=20:MaxDepth=3");
std::cout<<“Training all methods…”<<std::endl;
factory->TrainAllMethods();
std::cout<<“Testing all methods…”<<std::endl;
factory->TestAllMethods();
std::cout<<“Evaluate all methods…”<<std::endl;
factory->EvaluateAllMethods();
outputFile->Close();
std::cout<<“Finished the training run…”<<std::endl;
delete factory;
for version 6.12.02
TMVA::Factory *factory = new TMVA::Factory(mvaoutname, outputFile,"!V:!Silent:Color:DrawProgressBar:Transformations=I;P;G,D:AnalysisType=Classification" );
TMVA::DataLoader *dataloader=new TMVA::DataLoader(“dataset”);
std::vector mvaVars_V = splitstr(getVar(bdtclass)," “);
std::vector spectatorVars_V= splitstr(spectatorVars,” ");
std::cout<<“initializing variables…”<<std::endl;
for(int i = 0; i<mvaVars_V.size(); i++){
std::cout<<"adding: "<<mvaVars_V.at(i)<<std::endl;
dataloader->AddVariable(mvaVars_V.at(i),mvaVars_V.at(i), ‘F’);
}
for(int i =0; i<spectatorVars_V.size(); i++){
std::cout<<"adding spectator: "<<spectatorVars_V.at(i)<<std::endl;
dataloader->AddSpectator(spectatorVars_V.at(i),spectatorVars_V.at(i),‘F’);
}
Double_t signalWeight = 1.0;
Double_t backgroundWeight = 1.0;
dataloader->AddSignalTree ( signalTree, signalWeight);
dataloader->AddBackgroundTree(backgroundTree, backgroundWeight);
dataloader->SetSignalWeightExpression (“weight”);
dataloader->SetBackgroundWeightExpression(“weight”);
TCut mycuts = getcut(bdtclass);
TCut mycutb = getcut(bdtclass);
dataloader->PrepareTrainingAndTestTree(mycuts,mycutb, “nTrain_Signal=0:nTrain_Background=0:SplitMode=Random:NormMode=EqualNumEvents:!V”);
factory->BookMethod(dataloader, TMVA::Types::kBDT, “BDTG1”,"!H:!V:NTrees=800:MinNodeSize=1:BoostType=Grad:Shrinkage=0.06:UseBaggedBoost:BaggedSampleFraction=0.6:nCuts=20:MaxDepth=3");
std::cout<<“Training all methods…”<<std::endl;
factory->TrainAllMethods();
std::cout<<“Testing all methods…”<<std::endl;
factory->TestAllMethods();
std::cout<<“Evaluate all methods…”<<std::endl;
factory->EvaluateAllMethods();
outputFile->Close();
std::cout<<“Finished the training run…”<<std::endl;
delete dataloader;
delete factory;
Thanks
Kehinde