for i in range(len(events)):
cosTheta[0] = np.cos(Theta[i])
… # fill other variables
bdtOutput = reader.EvaluateMVA(“BDT method”)
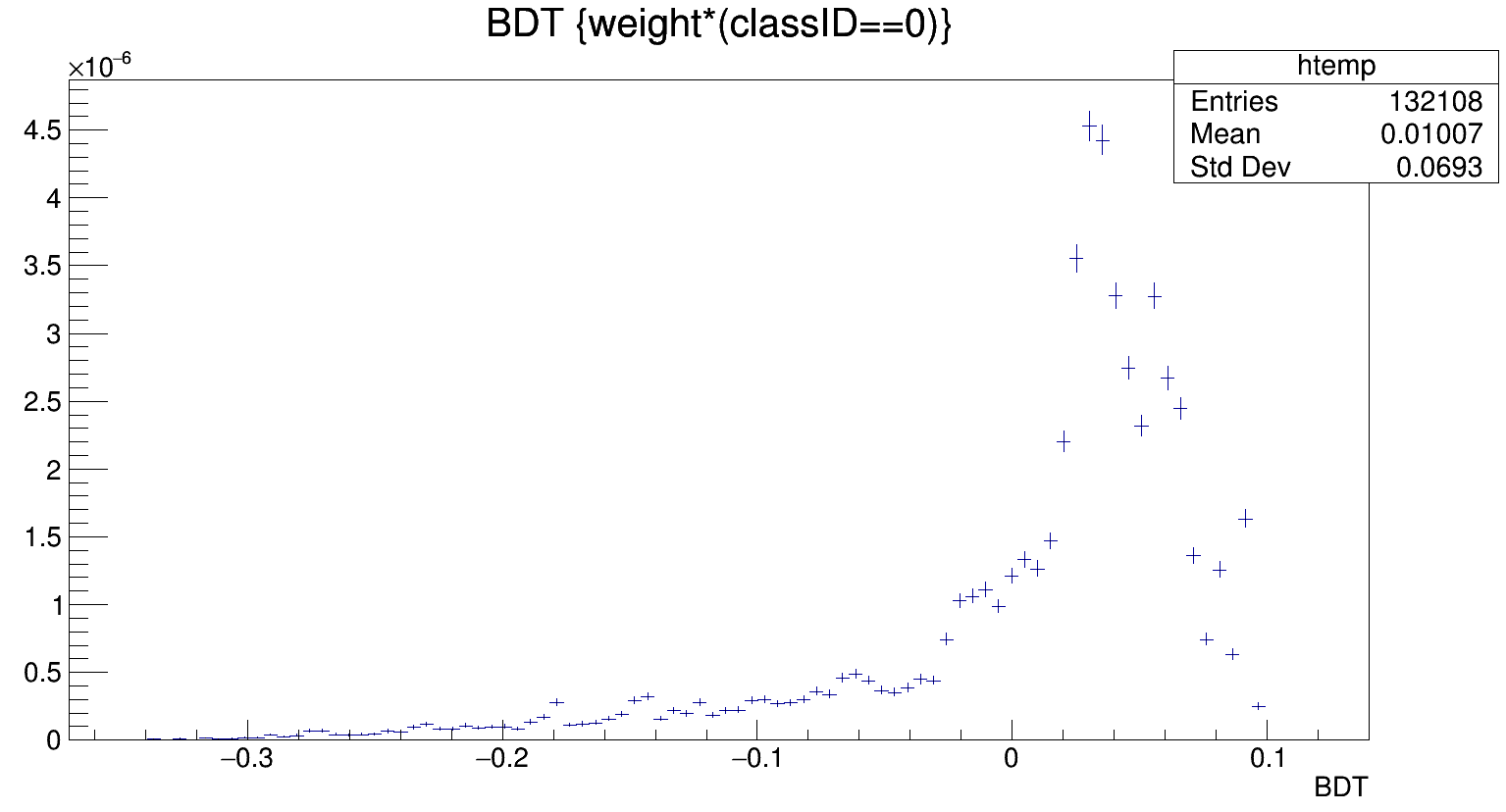
This works fine in the sense that it returns a value for the BDT classifier, but the histogram that I then get looks nothing like what was produced when making the xml file (i.e. in the TMVA GUI). I produced the xml file by running tutorials/tmva/TMVAClassification.C, using half the signal sample to train, the other half to test. I am now trying to get the BDT output for all events in this very same signal sample. I was expecting the result to look exactly the same but it’s completely different, in particular it’s not a smooth distribution: it has several peaks.
Thank you for the help!
ROOT Version: 6.24/00
Built for linuxx8664gcc on May 21 2021, 23:47:00
From heads/latest-stable@v6-24-00-1-ge6a04a86cb
Any idea? Anyone? My problem is that I don’t get the same distribution of the bdt output when I compare what I get from the TMVA GUI when training/testing the BDT, and when I apply it on the same data set using the xml file.
This is strange. Are you are you are using the a same sets of data when using the Reader or looking at the output produced during training and examined with the GUI ?
If you can add some macros and data file showing this problem, it will be helpful too
So for instance, I tried with only 2 variables named cosTheta and conf15. The distribution of the BDT output on the train tree and the test tree look very similar. I paste here the test tree to give you an idea. Now, when I add the bdtOutput to my data tree from reading the xml file using the reader, I only ever get two values, and I therefore get this other histogram.
The way I retrieve the bdtOutput is as described above, with the recommended method using the reader. These are the same variables that were used to make the xml file, in the same order, etc.
Hi,
Something has gone wrong. It is difficult to say what without looking at your code and your input file.
Can you please post them, you could do privately to me in case you cannot share them
Thanks for your response. My events are stored in a hdf5 file. So I use pyROOT to loop over all events in the file, recover the bdtOutput and add it to the file as an extra dictionary:
import h5py
import matplotlib.pyplot as plt
import numpy as np
from modules.plot import *
from modules.utils import *
from modules.DecayWidths import FullWidth
import math
from tqdm import tqdm
import sys, argparse
import ROOT
import array
# Define input arguments
parser = argparse.ArgumentParser(description='Plot the selected quantity for the selected particle')
parser.add_argument('-i', '--inputfile', type=str, default='190606_L7_995.h5', help='Name of the file')
args = parser.parse_args()
inputfile = args.inputfile
f = h5py.File(inputfile,'a')
ROOT.TMVA.Tools.Instance()
# Create the Reader object
reader = ROOT.TMVA.Reader( "!Color:!Silent" )
# Create a set of variables and declare them to the reader
# - the variable names MUST corresponds in name and type to those given in the weight file(s) used
cosTheta = array.array('f',[0])
conf_15m = array.array('f',[0])
reader.AddVariable("cosTheta", cosTheta)
reader.AddVariable("conf_15m", conf_15m)
# Book the MVA methods
reader.BookMVA("BDT method","dataset/weights/TMVAClassification_BDT_cosTheta_conf15.weights.xml")
### Conditions
# Condition basic from MVA
cdt_basic = (f['cascade0TaupedeDict']['Energy'] > 0) & (f['cascade1TaupedeDict']['Energy'] > 0) & (f['millipedeDict']['E_cascade0_15m'] > 0) & (f['millipedeDict']['E_cascade1_15m'] > 0) & (f['cascade0TaupedeDict']['Energy'] < 1000) & (f['cascade1TaupedeDict']['Energy'] < 1000) & (f['millipedeDict']['E_tot'] < 5000) & (f['taupedeDict']['chiSquared']/f['taupedeDict']['chiSquared_dof'] < 200) & (f['taupedeDict']['bestFitLength'] > 0) & (f['taupedeDict']['bestFitLength'] < 800)
# Cascade not nan
cdt_nan = np.logical_not(np.isnan(f['cascade0Dict']['Energy'])) & np.logical_not(np.isnan(f['cascade1Dict']['Energy']))
# This is "no condition" (always True)
cdt0 = np.ones(len(f['neutrinoDict']['Energy']), dtype=bool)
# Final condition
cdt = cdt_nan & cdt_basic
# Get variables from file
f_Zenith = f['cascade0TaupedeDict']['Zenith'][cdt]
f_E0_millipede_15m = f['millipedeDict']['E_cascade0_15m'][cdt]
f_E1_millipede_15m = f['millipedeDict']['E_cascade1_15m'][cdt]
f_Etot_millipede = f['millipedeDict']['E_tot'][cdt]
# Declare new container for the MVA output
bdtOutput = []
# Loop through events in h5 file
for i in range(len(f['cascade0TaupedeDict']['Energy'][cdt])):
cosTheta[0] = np.cos(f_Zenith[i])
conf_15m[0] = (f_E0_millipede_15m[i]+f_E1_millipede_15m[i])/f_Etot_millipede[i]
print(cosTheta[0],conf_15m[0])
print(reader.EvaluateMVA("BDT method"))
bdtOutput.append(reader.EvaluateMVA("BDT method"))
del f['bdtOutput']
f.create_dataset('bdtOutput', data=bdtOutput)
f.close()
Here is the xml file (in txt format just for the upload). Unfortunately, I cannot upload the hdf5 file containing the data here because the forum does not accept this format. TMVAClassification_BDT_cosTheta_conf15.weights.txt (1.6 MB)
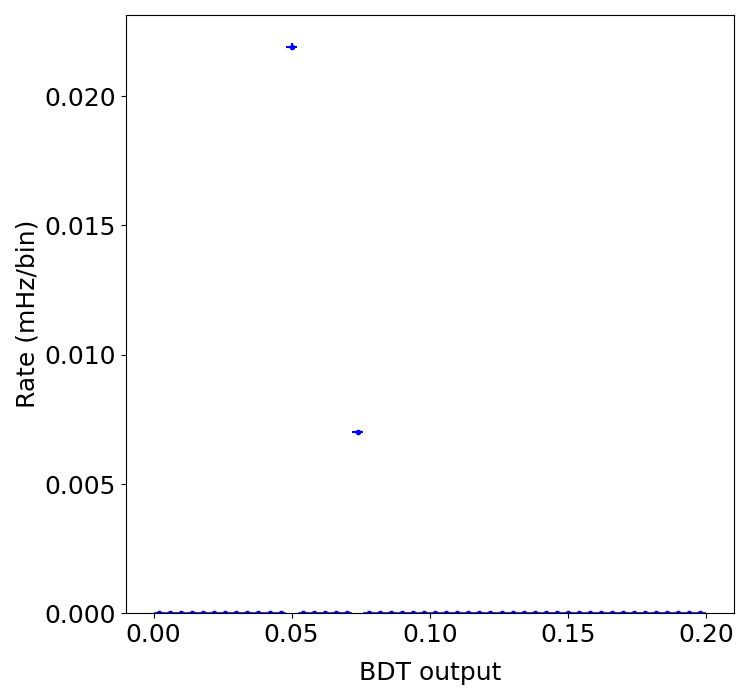
The two values on the same row are the cosTheta and conf_15m values, followed at the following line by the corresponding value of the bdtOutput. You can see that there are only ever two different values for the bdtOutput, and that it seems to depend on whether conf_15m is equal to 1.0 or not. I looked at my code and compared it against the few examples I’ve found online and it really seems correct. I correctly recover the cosTheta and conf_15m values, but somehow the bdtOutput does not vary correctly as a function of these two variables.
Hi,
You can post a link to the hdf5 file if you cannot attach, by using for exemple cernbox or sharebox.
From what I see it looks like the BDT is maybe not well trained.
I would need to see and being able to run macro used for trainiing the BDT and input training data
I’ve tried the other method but got the exact same result: I only ever get two values for the bdt output, whatever the loaded variables. Have you got any chance on your side,
But when I use it with the data from my h5 file, I get a segmentation fault, and then it prints a large vector with all the outputs that, again, are only these two numbers I ever get.
Hello,
Exactly the same values I am having too. So the question is why when using the old TMVA:Reader you are getting different values {-0.008333333333333333, -0.013888888888888888, -0.013888888888888888}
I will check also using the Reader